吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm
from sklearn.model_selection import train_test_split def load_data_classfication():
'''
加载用于分类问题的数据集
'''
# 使用 scikit-learn 自带的 iris 数据集
iris=datasets.load_iris()
X_train=iris.data
y_train=iris.target
# 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train) #支持向量机SVM非线性分类SVC模型
def test_SVC_linear(*data):
X_train,X_test,y_train,y_test=data
cls=svm.SVC(kernel='linear')
cls.fit(X_train,y_train)
print('Coefficients:%s, intercept %s'%(cls.coef_,cls.intercept_))
print('Score: %.2f' % cls.score(X_test, y_test)) # 生成用于分类的数据集
X_train,X_test,y_train,y_test=load_data_classfication()
# 调用 test_SVC_linear
test_SVC_linear(X_train,X_test,y_train,y_test)
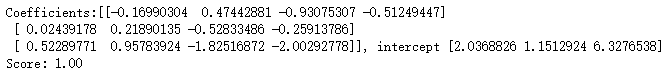
def test_SVC_poly(*data):
'''
测试多项式核的 SVC 的预测性能随 degree、gamma、coef0 的影响.
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure()
### 测试 degree ####
degrees=range(1,20)
train_scores=[]
test_scores=[]
for degree in degrees:
cls=svm.SVC(kernel='poly',degree=degree)
cls.fit(X_train,y_train)
train_scores.append(cls.score(X_train,y_train))
test_scores.append(cls.score(X_test, y_test))
ax=fig.add_subplot(1,3,1) # 一行三列
ax.plot(degrees,train_scores,label="Training score ",marker='+' )
ax.plot(degrees,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVC_poly_degree ")
ax.set_xlabel("p")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.legend(loc="best",framealpha=0.5) ### 测试 gamma ,此时 degree 固定为 3####
gammas=range(1,20)
train_scores=[]
test_scores=[]
for gamma in gammas:
cls=svm.SVC(kernel='poly',gamma=gamma,degree=3)
cls.fit(X_train,y_train)
train_scores.append(cls.score(X_train,y_train))
test_scores.append(cls.score(X_test, y_test))
ax=fig.add_subplot(1,3,2)
ax.plot(gammas,train_scores,label="Training score ",marker='+' )
ax.plot(gammas,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVC_poly_gamma ")
ax.set_xlabel(r"$\gamma$")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.legend(loc="best",framealpha=0.5)
### 测试 r ,此时 gamma固定为10 , degree 固定为 3######
rs=range(0,20)
train_scores=[]
test_scores=[]
for r in rs:
cls=svm.SVC(kernel='poly',gamma=10,degree=3,coef0=r)
cls.fit(X_train,y_train)
train_scores.append(cls.score(X_train,y_train))
test_scores.append(cls.score(X_test, y_test))
ax=fig.add_subplot(1,3,3)
ax.plot(rs,train_scores,label="Training score ",marker='+' )
ax.plot(rs,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVC_poly_r ")
ax.set_xlabel(r"r")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.legend(loc="best",framealpha=0.5)
plt.show() # 调用 test_SVC_poly
test_SVC_poly(X_train,X_test,y_train,y_test)

def test_SVC_rbf(*data):
'''
测试 高斯核的 SVC 的预测性能随 gamma 参数的影响
'''
X_train,X_test,y_train,y_test=data
gammas=range(1,20)
train_scores=[]
test_scores=[]
for gamma in gammas:
cls=svm.SVC(kernel='rbf',gamma=gamma)
cls.fit(X_train,y_train)
train_scores.append(cls.score(X_train,y_train))
test_scores.append(cls.score(X_test, y_test))
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(gammas,train_scores,label="Training score ",marker='+' )
ax.plot(gammas,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVC_rbf")
ax.set_xlabel(r"$\gamma$")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.legend(loc="best",framealpha=0.5)
plt.show() # 调用 test_SVC_rbf
test_SVC_rbf(X_train,X_test,y_train,y_test)

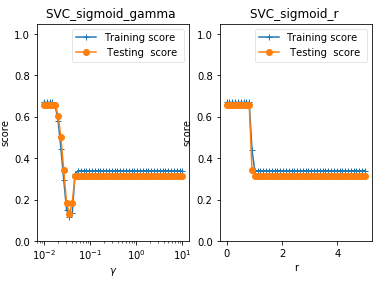
def test_SVC_sigmoid(*data):
'''
测试 sigmoid 核的 SVC 的预测性能随 gamma、coef0 的影响.
'''
X_train,X_test,y_train,y_test=data
fig=plt.figure() ### 测试 gamma ,固定 coef0 为 0 ####
gammas=np.logspace(-2,1)
train_scores=[]
test_scores=[] for gamma in gammas:
cls=svm.SVC(kernel='sigmoid',gamma=gamma,coef0=0)
cls.fit(X_train,y_train)
train_scores.append(cls.score(X_train,y_train))
test_scores.append(cls.score(X_test, y_test))
ax=fig.add_subplot(1,2,1)
ax.plot(gammas,train_scores,label="Training score ",marker='+' )
ax.plot(gammas,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVC_sigmoid_gamma ")
ax.set_xscale("log")
ax.set_xlabel(r"$\gamma$")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.legend(loc="best",framealpha=0.5)
### 测试 r,固定 gamma 为 0.01 ######
rs=np.linspace(0,5)
train_scores=[]
test_scores=[] for r in rs:
cls=svm.SVC(kernel='sigmoid',coef0=r,gamma=0.01)
cls.fit(X_train,y_train)
train_scores.append(cls.score(X_train,y_train))
test_scores.append(cls.score(X_test, y_test))
ax=fig.add_subplot(1,2,2)
ax.plot(rs,train_scores,label="Training score ",marker='+' )
ax.plot(rs,test_scores,label= " Testing score ",marker='o' )
ax.set_title( "SVC_sigmoid_r ")
ax.set_xlabel(r"r")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.legend(loc="best",framealpha=0.5)
plt.show() # 调用 test_SVC_sigmoid
test_SVC_sigmoid(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型的更多相关文章
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——支持向量机非线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——支持向量机线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——多项式贝叶斯分类器MultinomialNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——数据预处理包裹式特征选取模型
from sklearn.svm import LinearSVC from sklearn.datasets import load_iris from sklearn.feature_select ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
随机推荐
- Iptables防火墙(未完)
来自深信服培训第二天下午课程 软防跟硬防 Linux包过滤防火墙概述 netfilter 位于Linux内核中的包过滤功能体系 称为Linux防火墙的"内核态" iptables ...
- pytest学习8-运行上次执行失败的用例
该插件提供了两个命令行选项,用于重新运行上次pytest调用的失败: --lf,--last-failed- 只重新运行上次失败的用例,如果没有失败则全部运行 --ff,--failed-first- ...
- 论文阅读笔记(三)【AAAI2017】:Learning Heterogeneous Dictionary Pair with Feature Projection Matrix for Pedestrian Video Retrieval via Single Query Image
Introduction (1)IVPR问题: 根据一张图片从视频中识别出行人的方法称为 image to video person re-id(IVPR) 应用: ① 通过嫌犯照片,从视频中识别出嫌 ...
- vue 报错碰到的一些问题及其规范
报错信息:Expected error to be handled(需要处理的错误) 这是因为回调函数里面的参数error没有运用到,所以可以不设置参数,或者在回调函数内console.log(err ...
- C++——指针2-指向数组的指针和指针数组
7.4 指向数组元素的指针 声明与赋值 例:int a[10], *pa; pa=&a[0]; 或 pa=a[p1] ; 通过指针引用数组元素,经过上述声明及赋值后: *pa就是a[0],*( ...
- css给span加float:right右浮动后内容换行下移
转自:https://www.jb51.net/css/67309.html 在div css布局中 当span标签右浮动时会产生换行狭义的现象 <!DOCTYPE html PUBLIC &q ...
- flask入门(三)
表单 request.form 能获取POST 请求中提交的表单数据.但是这样不太安全,容易受到恶意攻击.对此,flask有一个flask-wtf扩展,用于避免这一情况 在虚拟环境下用pip inst ...
- 登录时 按Enter 进入登录界面 或者下一行
function keyLogin() { if (event.keyCode == 13) //回车键的键值为13 $(".btn-submit").click(); //调用登 ...
- spring security和java web token整合
思路: spring security 1.用户输入用户名密码. 2.验证:从库中(可以是内存.数据库等)查询该用户的密码.角色,验证用户名和密码是否正确.如果正确,则将填充Authenticatio ...
- OpenCV-Mat结构详解
前面博客中Mat函数谈到一些理解,但是理解的比较浅显,下面谈谈通道,行列等意义: Mat的常见属性 opencv中type类型· CV_<bit_depth>(S|U|F)C<num ...