R_Studio(时序)Apriori算法寻找频繁项集的方法
应用ARIMA(1,1,0)对2015年1月1日到2015年2月6日某餐厅的销售数量做为期5天的预测
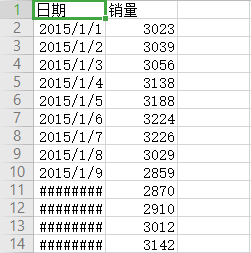
setwd('D:\\dat')
#install.packages("forecast")
#install.packages("plyr")
#install.packages("fUnitRoots")
#install.packages("tibble")
library(forecast)
library(fUnitRoots)
Data=read.csv("arima_data.csv",header=T)[,2]
sales=ts(Data)
plot.ts(sales,xlab="时间", ylab="销量 / 元")
#单位根检验
unitrootTest(sales)
#自相关图
acf(sales)
#一阶差分
difsales=diff(sales)
plot.ts(difsales,xlab="时间", ylab="销量残差 / 元")
#自相关图
acf(difsales)
#单位根检验
unitrootTest(difsales)
#白噪声检验
Box.test(difsales, type="Ljung-Box")
#偏自相关图
pacf(difsales)
#ARIMA(1,1,0)模型
arima=arima(sales, order=c(1,1,0))
arima
forecast=forecast(arima, h=5, level=c(99.5))
forecast
Gary.R
实现过程
数据预处理
setwd('D:\\dat')
#install.packages("forecast")
#install.packages("plyr")
#install.packages("fUnitRoots")
#install.packages("tibble")
library(forecast)
library(fUnitRoots)
Data=read.csv("arima_data.csv",header=T)[,2]
sales=ts(Data)
plot.ts(sales,xlab="时间", ylab="销量 / 元")
相关检验
单位根检验 百度百科:传送门
单位根检验是指检验序列中是否存在单位根,因为存在单位根就是非平稳时间序列了。单位根就是指单位根过程,可以证明,序列中存在单位根过程就不平稳,会使回归分析中存在伪回归。
> #单位根检验
> unitrootTest(sales) Title:
Augmented Dickey-Fuller Test Test Results:
PARAMETER:
Lag Order: 1
STATISTIC:
DF: 1.6708
P VALUE:
t: 0.9748
n: 0.9745 Description:
Thu Nov 29 21:45:16 2018 by user: ASUS
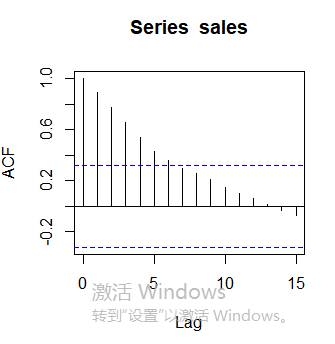
自相关 百度百科:传送门
自相关是指信号在1个时刻的瞬时值与另1个时刻的瞬时值之间的依赖关系,是对1个随机信号的时域描述。
#自相关图
acf(sales)
#自相关图
acf(difsales)

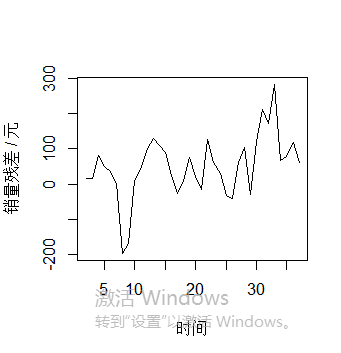
一阶差分 百度百科:传送门
一阶差分就是离散函数中连续相邻两项之差。当自变量从x变到x+1时,函数y=y(x)的改变量∆yx=y(x+1)-y(x),(x=0,1,2,......)称为函数 y(x)在点x的一阶差分,记为∆yx=yx+1-yx,(x=0,1,2,......)
#一阶差分
difsales=diff(sales)
plot.ts(difsales,xlab="时间", ylab="销量残差 / 元")
单位根检验 百度百科:传送门
单位根检验是指检验序列中是否存在单位根,因为存在单位根就是非平稳时间序列了。单位根就是指单位根过程,可以证明,序列中存在单位根过程就不平稳,会使回归分析中存在伪回归。
> unitrootTest(difsales) Title:
Augmented Dickey-Fuller Test Test Results:
PARAMETER:
Lag Order: 1
STATISTIC:
DF: -2.4226
P VALUE:
t: 0.01689
n: 0.2727 Description:
Thu Nov 29 21:50:32 2018 by user: ASUS
白噪声检验 百度百科:传送门
白噪声序列,是指白噪声过程的样本实称,简称白噪声。随机变量X(t)(t=1,2,3……),如果是由一个不相关的随机变量的序列构成的,即对于所有S不等于T,随机变量Xt和Xs的协方差为零,则称其为纯随机过程。对于一个纯随机过程来说,若其期望为0,方差为常数,则称之为白噪声过程。
> #白噪声检验
> Box.test(difsales, type="Ljung-Box") Box-Ljung test data: difsales
X-squared = 11.304, df = 1, p-value = 0.0007734
ARIMA(1,1,0)模型 百度百科:传送门
ARIMA模型全称为自回归积分滑动平均模型,所谓ARIMA模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。
> arima=arima(sales, order=c(1,1,0))
> arima Call:
arima(x = sales, order = c(1, 1, 0)) Coefficients:
ar1
0.6353
s.e. 0.1236 sigma^2 estimated as 5969: log likelihood = -207.84, aic = 419.68
> forecast=forecast(arima, h=5, level=c(99.5))
> forecast
Point Forecast Lo 99.5 Hi 99.5
38 4856.386 4639.508 5073.263
39 4881.405 4465.699 5297.112
40 4897.299 4290.401 5504.198
41 4907.396 4122.477 5692.315
42 4913.810 3964.980 5862.639
R_Studio(时序)Apriori算法寻找频繁项集的方法的更多相关文章
- 手推Apriori算法------挖掘频繁项集
版权声明:本文为博主原创文章,未经博主允许不得转载. Apriori算法: 使用一种称为逐层搜索的迭代方法,其中K项集用于搜索(K+1)项集. 首先,通过扫描数据库,统计每个项的计数,并收集满足最小支 ...
- 关联分析中寻找频繁项集的FP-growth方法
关联分析是数据挖掘中常用的分析方法.一个常见的需求比如说寻找出经常一起出现的项目集合. 引入一个定义,项集的支持度(support),是指所有包含这个项集的集合在所有数据集中出现的比例. 规定一个最小 ...
- FP-growth算法发现频繁项集(一)——构建FP树
常见的挖掘频繁项集算法有两类,一类是Apriori算法,另一类是FP-growth.Apriori通过不断的构造候选集.筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数 ...
- 手推FP-growth (频繁模式增长)算法------挖掘频繁项集
一.频繁项集挖掘为什么会出现FP-growth呢? 原因:这得从Apriori算法的原理说起,Apriori会产生大量候选项集(就是连接后产生的),在剪枝时,需要扫描整个数据库(就是给出的数据),通过 ...
- FP-Growth算法之频繁项集的挖掘(python)
前言: 关于 FP-Growth 算法介绍请见:FP-Growth算法的介绍. 本文主要介绍从 FP-tree 中提取频繁项集的算法.关于伪代码请查看上面的文章. FP-tree 的构造请见:FP-G ...
- FP-growth算法发现频繁项集(二)——发现频繁项集
上篇介绍了如何构建FP树,FP树的每条路径都满足最小支持度,我们需要做的是在一条路径上寻找到更多的关联关系. 抽取条件模式基 首先从FP树头指针表中的单个频繁元素项开始.对于每一个元素项,获得其对应的 ...
- 关联规则—频繁项集Apriori算法
频繁模式和对应的关联或相关规则在一定程度上刻画了属性条件与类标号之间的有趣联系,因此将关联规则挖掘用于分类也会产生比较好的效果.关联规则就是在给定训练项集上频繁出现的项集与项集之间的一种紧密的联系.其 ...
- 【机器学习实战】第12章 使用FP-growth算法来高效发现频繁项集
第12章 使用FP-growth算法来高效发现频繁项集 前言 在 第11章 时我们已经介绍了用 Apriori 算法发现 频繁项集 与 关联规则.本章将继续关注发现 频繁项集 这一任务,并使用 FP- ...
- 【机器学习实战】第12章 使用 FP-growth 算法来高效发现频繁项集
第12章 使用FP-growth算法来高效发现频繁项集 前言 在 第11章 时我们已经介绍了用 Apriori 算法发现 频繁项集 与 关联规则.本章将继续关注发现 频繁项集 这一任务,并使用 FP- ...
随机推荐
- 首探:Ruby on Rails 简单了解
一. 安装 Ruby安装:https://ruby-china.org/wiki/rvm-guide 注:安装了RVM和Gem后 安装rails: gem install rails -v 5.1.4 ...
- python-连接mysql实例
import pymysql # 创建连接 conn = pymysql.connect(host='192.168.71.140', port=3306, user='root', passwd=' ...
- monggoDB添加到windows服务
----------------mongoDB安装------------------------------- 1.下载mongoDB安装包安装完毕后,配置环境变量 D:\Program Files ...
- java中this总结(转载请注明出处)
1:this在构造方法中:this可以进行构造方法中的相互调用,this(参数): 2:this调用方法中,代表调用该方法的对象的地址,例如下面的代码比较 package thisTest; publ ...
- numpy:np.random.seed()
np.random.seed()函数可以保证生成的随机数具有可预测性. 可以使多次生成的随机数相同 1.如果使用相同的seed( )值,则每次生成的随即数都相同: 2.如果不设置这个值,则系统根据时间 ...
- 漏洞:阿里云盾phpMyAdmin <=4.8.1 后台checkPageValidity函数缺陷可导致GETSHELL
阿里云盾提示phpMyAdmin <=4.8.1会出现漏洞有被SHELL风险,具体漏洞提醒: 标题 phpMyAdmin <=4.8.1 后台checkPageValidity函数缺陷可导 ...
- jenkins操作TreeView,展开合并
双击treeview 双击选中的部分,使treeview展开合并 Opt() #include <GUIConstantsEx.au3> #include <GuiTreeView. ...
- 好用的 python 工具集合
图标处理小程序, 妈妈再也不用担心我不会制作图标了 # PythonMargick包可以到Unofficial Windows Binaries for Python Extension Packag ...
- python django网站编程视频教程学习资料下载
“人生苦短,我用python”,学python的小伙伴应该都了解这句话的含义.但是,学python,你真正了了解强大的Django框架吗!?据说Django还是由吉普赛的一个吉他手的名字命名的呢,有木 ...
- 2.(基础)tornado的请求与响应
之前我们介绍了tornado 的基础流程,但是还遗留了一些问题,今天我们就来解决这些遗留问题并学习新的内容 settings,使用tornado.web.Application(handler, ** ...