scrapy框架原理学习
Scrapy框架原理:
参考出处:https://cuiqingcai.com/3472.html
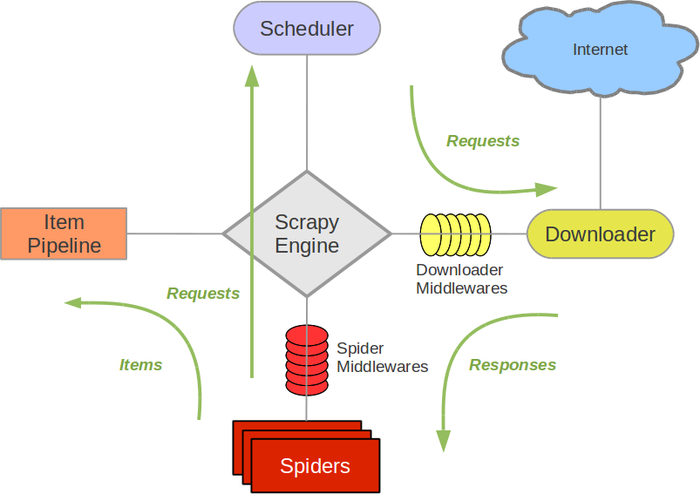
整个Scrapy的架构图:
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?)
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
数据在整个Scrapy的流向:
程序运行的时候,
引擎:Hi!Spider, 你要处理哪一个网站?
Spiders:我要处理23wx.com
引擎:你把第一个需要的处理的URL给我吧。
Spiders:给你第一个URL是XXXXXXX.com
引擎:Hi!调度器,我这有request你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request给我,
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照下载中间件的设置帮我下载一下这个request
下载器:好的!给你,这是下载好的东西。(如果失败:不好意思,这个request下载失败,然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载。)
引擎:Hi!Spiders,这是下载好的东西,并且已经按照Spider中间件处理过了,你处理一下(注意!这儿responses默认是交给def parse这个函数处理的)
Spiders:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,这是我需要跟进的URL,将它的responses交给函数 def xxxx(self, responses)处理。还有这是我获取到的Item。
引擎:Hi !Item Pipeline 我这儿有个item你帮我处理一下!调度器!这是我需要的URL你帮我处理下。然后从第四步开始循环,直到获取到你需要的信息,
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy会重新下载。)
scrapy框架原理学习的更多相关文章
- scrapy爬虫学习系列五:图片的抓取和下载
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列四:portia的学习入门
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy再学习与第二个实例
这周对于Scrapy进一步学习,知识比较零散,需要爬取的网站因为封禁策略账号还被封了/(ㄒoㄒ)/~~ 一.信息存储 1.log存储命令:scrapy crawl Test --logfile=tes ...
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
- 自己的Scrapy框架学习之路
开始自己的Scrapy 框架学习之路. 一.Scrapy安装介绍 参考网上资料,先进行安装 使用pip来安装Scrapy 在开始菜单打开cmd命令行窗口执行如下命令即可 pip install Scr ...
- #0 scrapy爬虫学习中遇到的坑记录
python 基础学习中对于scrapy的使用遇到了一些问题. 首先进行的是对Amazon.cn的检索结果页进行爬取,很顺利,无碍. 下一个目标是对baidu的搜索结果进行爬取 1,反爬虫 1.1 我 ...
随机推荐
- Objective-C简介
1.OC简介 全称:Objective-C,是扩充C的面向对象编程语言,主要用于iOS和Mac OS开发. C语言的基础上,增加了一层最小的面向对象语法 完全兼容C语言 可以在OC代码中混入C语言代码 ...
- php5.4新功能Traits
php5.4新功能Traits介绍 1. traits Traits是在5.4中新增的一个用于实现代码重用的方法. php是一种单一继承的语言,我们无法像java一样在一个class中extends多 ...
- Linux下完全删除用户
实验环境:Centos7虚拟机 首先创建一个普通用户gubeiqing. [root@localhost ~]# useradd gubeiqing [root@localhost ~]# passw ...
- June 7. 2018 Week 23rd Thursday
Half is worse than none at all. 一知半解比一无所知更痛苦. From Westworld. If we go looking for the truth, get th ...
- February 22nd, 2018 Week 8th Thursday
Confine yourself to the present. 着眼当下. The morning wind spreads its fresh smell, we should get up an ...
- 2.02-request_header_two
import urllib.request def load_baidu(): url= "http://www.baidu.com" #添加请求头的信息 #创建请求对象 requ ...
- 关于Swift中的指针的那些事
前言 在Objective-c的世界中,一切对象都是指针.它是一种运行时语言,具体指针的对象类型将会在运行时,由系统分配.这样虽然自由,但是却并不安全. Swift世界就不一样了,Swift的世界很安 ...
- CUDA Fortran for Scientists and Engineers第二版翻译
下午听朋友说,NV把<CUDA Fortran for Scientists and Engineers>的出版权卖给了国内某出版商.第一反应是我们三翻译的岂不是白翻译了.第二 ...
- 生成对抗网络(GAN)
GAN的全称是 Generative Adversarial Networks,中文名称是生成对抗网络.原始的GAN是一种无监督学习方法,巧妙的利用“博弈”的思想来学习生成式模型. 1 GAN的原理 ...
- spring boot启动报错
Exception encountered during context initialization - cancelling refresh attempt: org.springframewor ...