scrapy框架原理学习
Scrapy框架原理:
参考出处:https://cuiqingcai.com/3472.html
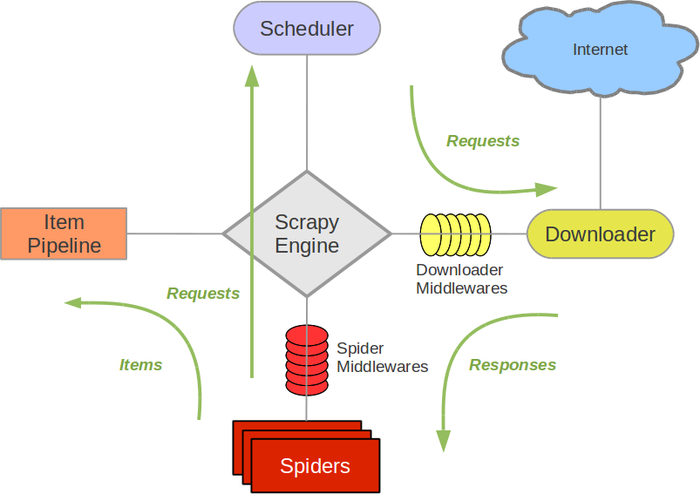
整个Scrapy的架构图:
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?)
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
数据在整个Scrapy的流向:
程序运行的时候,
引擎:Hi!Spider, 你要处理哪一个网站?
Spiders:我要处理23wx.com
引擎:你把第一个需要的处理的URL给我吧。
Spiders:给你第一个URL是XXXXXXX.com
引擎:Hi!调度器,我这有request你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request给我,
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照下载中间件的设置帮我下载一下这个request
下载器:好的!给你,这是下载好的东西。(如果失败:不好意思,这个request下载失败,然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载。)
引擎:Hi!Spiders,这是下载好的东西,并且已经按照Spider中间件处理过了,你处理一下(注意!这儿responses默认是交给def parse这个函数处理的)
Spiders:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,这是我需要跟进的URL,将它的responses交给函数 def xxxx(self, responses)处理。还有这是我获取到的Item。
引擎:Hi !Item Pipeline 我这儿有个item你帮我处理一下!调度器!这是我需要的URL你帮我处理下。然后从第四步开始循环,直到获取到你需要的信息,
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy会重新下载。)
scrapy框架原理学习的更多相关文章
- scrapy爬虫学习系列五:图片的抓取和下载
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列四:portia的学习入门
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy爬虫学习系列三:scrapy部署到scrapyhub上
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- scrapy再学习与第二个实例
这周对于Scrapy进一步学习,知识比较零散,需要爬取的网站因为封禁策略账号还被封了/(ㄒoㄒ)/~~ 一.信息存储 1.log存储命令:scrapy crawl Test --logfile=tes ...
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
- 自己的Scrapy框架学习之路
开始自己的Scrapy 框架学习之路. 一.Scrapy安装介绍 参考网上资料,先进行安装 使用pip来安装Scrapy 在开始菜单打开cmd命令行窗口执行如下命令即可 pip install Scr ...
- #0 scrapy爬虫学习中遇到的坑记录
python 基础学习中对于scrapy的使用遇到了一些问题. 首先进行的是对Amazon.cn的检索结果页进行爬取,很顺利,无碍. 下一个目标是对baidu的搜索结果进行爬取 1,反爬虫 1.1 我 ...
随机推荐
- 大话C#之委托
开篇先来扯下淡,上篇博客LZ在结尾说这篇博客会来说说C#中的事件.但是当LZ看完事件之后发现事件是以委托为基础来实现的,于是LZ就自作主张地在这篇博客中先来说说委托,还烦请各位看官见谅!!!另外关于委 ...
- oracle 分组函数执行分析
先上例了: select job as "JOB1", avg(sal) as "avg sal" from scott.emp group by " ...
- VS快捷键失效问题
VS作为宇宙最强IDE,为我们提供了强大的快捷键组合,熟练的使用这些快捷键能极大提高我们的编码效率,但是在我们实际使用的过程中经常会遇到某个快捷键组合失效的问题. 问题原因: 一般都是VS的快捷键与电 ...
- jQuery -- 光阴似箭(一):初见 jQuery -- 基本用法,语法,选择器
jQuery -- 知识点回顾篇(一):初见jQuery -- 基本用法,语法,选择器 1. 使用方法 jQuery 库位于一个 JavaScript 文件中,其中包含了所有的 jQuery 函数. ...
- creo2.0安装方法和图文详解教程
Creo2.0是由PTC公司2012年8月底推出的全新CAD设计软件包,整合了PTC公司的三个软件Pro/Engineer的参数化技术.CoCreate的直接建模技术和ProductView的三维可视 ...
- Custom partition assignment and migration kafka集群扩充迁移指定partition
The partition reassignment tool can also be used to selectively move replicas of a partition to a sp ...
- Angular 开发小妙招1:提交表单数据验证不通过,更改输入组件的样式
开发表单时,客户端数据完整性校验是必不可少的,在jquery 时代出现了无数的数据验证插件也很好用,开发Angular 应用时,angular 内置了一些常用的数据验证指令.今天要讲的不是这些指令如何 ...
- 面试----你可以手写一个promise吗
参考:https://www.jianshu.com/p/473cd754311f <!DOCTYPE html> <html> <head> <meta c ...
- UVA12188-Inspector's Dilemma(欧拉回路+连通性判断)
Problem UVA12188-Inspector's Dilemma Time Limit: 3000 mSec Problem Description In a country, there a ...
- WPF中修改DataGrid单元格值并保存
编辑DataGrid中的单元格的内容然后保存是非常常用的功能.主要涉及到的方法就是DataGrid的CellEditEnding 和BeginningEdit .其中BeginningEdit 是当 ...