python网络爬虫笔记(八)
一、pthon 序列化json格式
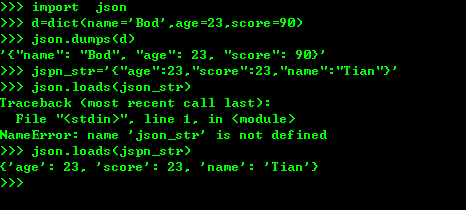
1、将python内置对象转换成json 模块,dumps()方法返回的是一个str,内容是标准的JSON,dump()方法可以直接吧JSON写入一个file-like-object,要把JSON反序列化为python对象,使用loads()或者对立的方法,
2、多线程和多进程 (multiprocessing)
3、常见的模块
datetime模块包含一个datetime的类。通过 from datetime import datetime 导入的才是datetime 这个类
from datetime import datetime dt=datetime(215,4,15,21,12) dt.timestamp()
collections模块 ,namedtuple是一个函数,它用来创建一个定义的tuple对象,规定了tuple的元素个数,并可以使用属性而不是缩影来引用tuple的元素。
from collextions import namedtuple Point=namedtuple("Point",['x','y']) p=Point(a,2) p.x
deque函数,为了实高效的插入和删除双向列表,适合队列和栈:
from collections import deque q=deque(['a','v','f']) q.append('x') q.appendleft('f') deque 实现了appendleft() 和popleft()
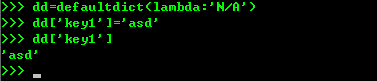
defaultdict使用dict时如果 可以不存在,就会抛出keyError,
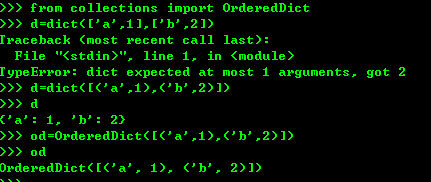
使用dict的时候。key是无序的 ,但是对dict做迭代,无法确定key的顺序,如果要保持key的顺序,使用OrderedDict
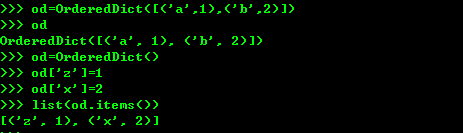
OrderedDict的key会按照插入的顺序排列,不是key本身排列
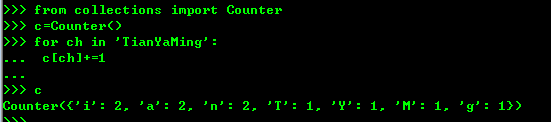
counter是一个简单的计数器,统计字符出现的个数
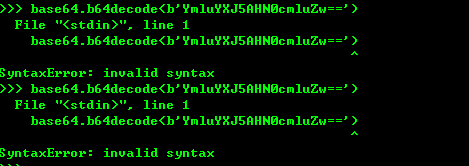
base64编码机制,标准的base64编码可能出现字符+ 或者—号,在URl中不允许出现,所以又有一种url safe的base64编码 把+ 或者-号编程-和_
struct模块提供了一个解决bytes其他二进制数据类型转换 ,struct的pack函数把任意的数据类型转换成bytes....。pack的第一个参数是处理指令,I表示4字节无符号整数,后面的参数个数和要处理的指令一致。unpack把bytes变成相应的数据类型

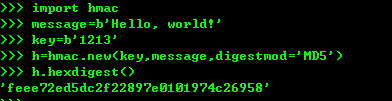
4、python提供了常见的MD5和SHA1 等算法,摘要算法又叫哈希算法 散列算法。它是把任意长度的数据转换成一个固定长度的数据通常用十六进制的字符串表示。摘要算法是通过摘要函数f() 对任意长度的数据data 计算出长度固定的digest目的就是防止原始数据被人篡改。,而且对原始数据做了一个bit的修改,就会导致计算出来摘要完全不同。

如果数据较大可以多次调用hashlib模块中的MD5函数计算结果是一样的。

5、python内的模块itertools提供了操作迭代对象的函数,
import itertools naturals=itertools.count(1)
for n in naturals: print(n)
因为count()函数会创建一个无限的迭代器,上述计算会无限的迭代下去。
另一个函数循环迭代的就是cycle()函数。
import itertools
cs=itertools.sycle('ABC')
for c in cs: print(c) 这样就会一直持续循环输出ABC
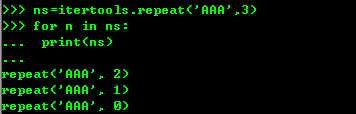
还有一个重复函数就是repeat函数。
ns=itertools.repeat('A',3)
for n in ns:
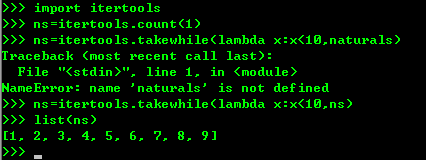
无限循环只有在for迭代时候才会无限制的迭代下去,如果只是创建一个迭代对象,他不会实现把无限个元素 生成出来,是时候是哪个也不会在内存中创建无限循环的元素,但是通常使用takewhile()函数对判断条件截取出一个有限的循环。
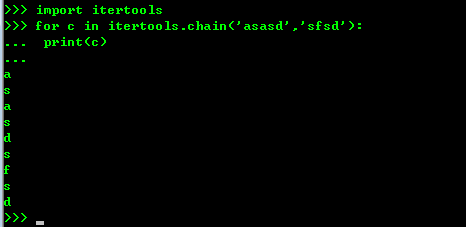
chain()函数可以把一组迭代对象串联起来,形成一个更大的迭代器。
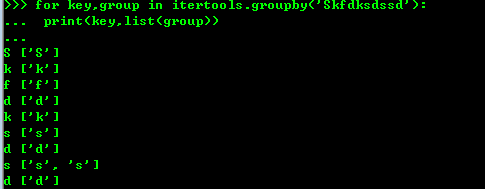
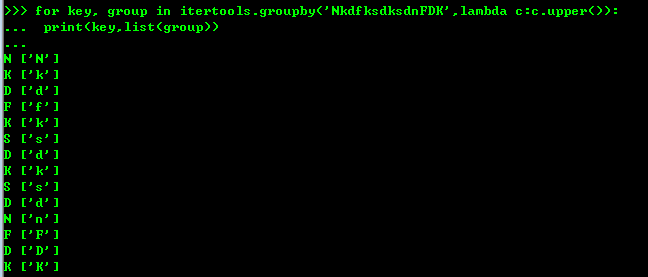
groupby()函数把迭代器中相邻的重复的元素挑出来放到一起
6、contextlib模块, 在python中必须关闭文件,但是使用with参数就不用。
try:
f = open('/path/to/file', 'r')
f.read()
finally:
if f:
f.close()
可以直接改写成这样的形式, with open('/path/file','r')as f: f.read() 就可以不必在担心文件的关闭7、简单的网站抓取获得

要是伪装成一台iPhone6区访问网页抓取网页内容


模拟微博登陆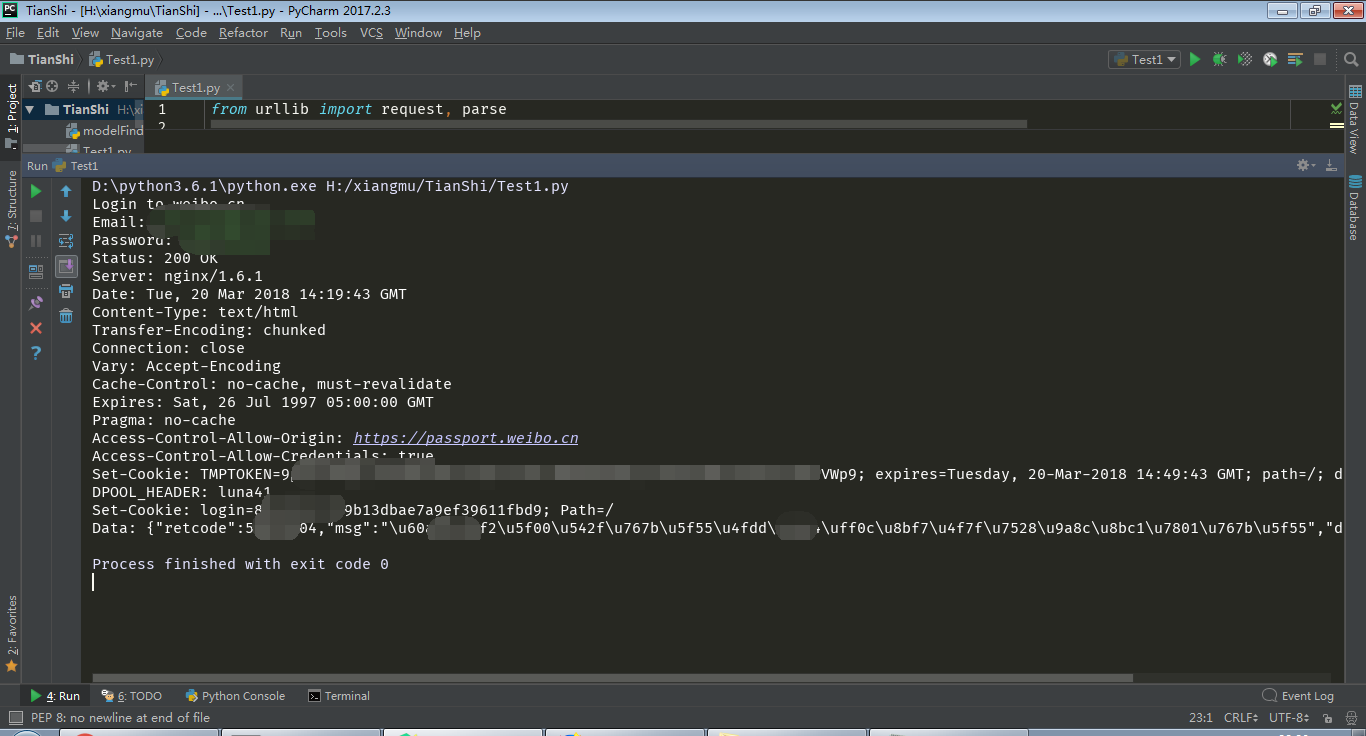
python网络爬虫笔记(八)的更多相关文章
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- [Python]网络爬虫(八):糗事百科的网络爬虫(v0.2)源码及解析
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8932310 项目内容: 用Python写的糗事百科的网络爬虫. 使用方法: 新建一个 ...
- Python网络爬虫笔记(二):链接爬虫和下载限速
(一)代码1(link_crawler()和get_links()实现链接爬虫) import urllib.request as ure import re import urllib.parse ...
- python网络爬虫笔记(九)
4.1.1 urllib2 和urllib是两个不一样的模块 urllib2最简单的就是使用urllie2.urlopen函数使用如下 urllib2.urlopen(url[,data[,timeo ...
- python网络爬虫笔记(六)
1.获取属性如果不存在就返回404,通过内置一系列函数,我们可以对任意python对象进行剖析,拿到其内部数据,但是要注意的是,只是在不知道对象信息的时候,我们可以获得对象的信息. 2.实例属性和类属 ...
- python网络爬虫笔记(五)
一.python的类对象的继承 1.所有的父类都是object类,由于类可以起到模块的作用,因此,可以在创建实例的时候,巴西一些认为必须要绑定的属性填写上去,通过定义一个特殊的方法 __init__, ...
- python网络爬虫笔记(四)
一.python中的高阶函数算法 1.sorted()函数的排序 sorted()函数是一个高阶函数,还可以接受一个key函数来实现自定义的函数排序,key指定的函数作用于每个序列元素上,并根据k ...
- python网络爬虫笔记(三)
一.切片和迭代 1.列表生成式 2.生成器的generate,但是generate保存的是算法,所以可以迭代计算,没有必要,每次调用generate 二.iteration 循环 1.凡是作用于for ...
- python网络爬虫笔记(一)
一.查询数据字典型数据 1.先说说dictionary查找和插入的速度极快,不会随着key的增加减慢速度,但是占用的内存大 2.list查找和插入的时间随着元素的增加而增加,但还是占用的空间小,内存浪 ...
随机推荐
- GitHub贡献第一的公司是谁?微软开源软件列表
参考:http://www.infoq.com/cn/news/2017/03/GitHub-first-Microsoft-open-sour 提起微软公司,不少人第一反应是老牌巨头专注于私有化软件 ...
- linux switch 跳转到 ”跳转至 case 标号“ 的错误
参考链接: http://blog.csdn.net/qustdjx/article/details/8636489
- JAVA进阶3
间歇性混吃等死,持续性踌躇满志系列-------------第3天 1.局部内部类 局部内部类是指在类的方法中定义的内部类,它的作用范围也是在这个方法体内. class SellOutClass{ p ...
- MVC_Route层层深入
1.前期准备 新建一个MVC项目,并添加Home和About两个控制器 在这两个控制器对应添加index页面 namespace Study_MVC_Route.Controllers { publi ...
- linux上安装Docker(非常简单的安装方法)
Docker的三大核心概念:镜像.容器.仓库 镜像:类似虚拟机的镜像.用俗话说就是安装文件. 容器:类似一个轻量级的沙箱,容器是从镜像创建应用运行实例, 可以将其启动.开始.停止.删除.而这些容器都是 ...
- python练习 之 实践出真知 中心扩展法求最大回文子串 (leetcode题目)
1 问题,给定一个字符串,求字符串中包含的最大回文子串,要求O复杂度小于n的平方. 首先需要解决奇数偶数的问题,办法是:插入’#‘,aba变成#a#b#a#,变成奇数个,aa变成#a#a#,变成奇数个 ...
- 第二节,surf特征检测关键点,实现图片拼接
初级的图像拼接为将两幅图像简单的粘贴在一起,仅仅是图像几何空间的转移和合成,与图像内容无关:高级图像拼接也叫做基于特征匹配的图像拼接,拼接时消去两幅图像相同的部分,实现拼接全景图. 实现步骤: 1.采 ...
- macbook install mysql
安装Homebrew,详细步骤参见Homebrew官网. brew doctor确认brew在正常工作. brew update更新包. brew install mysql 安装mysql.log如 ...
- 【转】Python之正则表达式(re模块)
[转]Python之正则表达式(re模块) 本节内容 re模块介绍 使用re模块的步骤 re模块简单应用示例 关于匹配对象的说明 说说正则表达式字符串前的r前缀 re模块综合应用实例 参考文档 提示: ...
- 嵌入式系统C编程之堆栈回溯【转】
转自:https://www.cnblogs.com/clover-toeic/p/3949896.html 前言 在嵌入式系统C语言开发调试过程中,常会遇到各类异常情况.一般可按需添加打印信息,以便 ...