Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理
源代码如下:
# 改进版, 增加了 .strip()方法的使用
# coding=utf-8
# urllib是用于获取网络资源的库,python3自带
# 此处的request是由Request类创建的一个实例对象
import urllib.request # 调用request对象的urlopen()方法 , 传入url参数
file = urllib.request.urlopen("http://www.baidu.com")
# readlines()方法逐行读取整个文件到一个列表
# 注意: .readlines()方法会把字符串前后的空白字符都抓进来, 可用.strip()方法去掉
file_list = file.readlines()
# 用for循环和if条件语句来遍历读取列表的前200个元素
i = 0
for file_per in file_list:
i += 1
if i <= 200:
print(file_per.strip()) # str.strip(): 去掉字符串前后的空白字符
else:
break
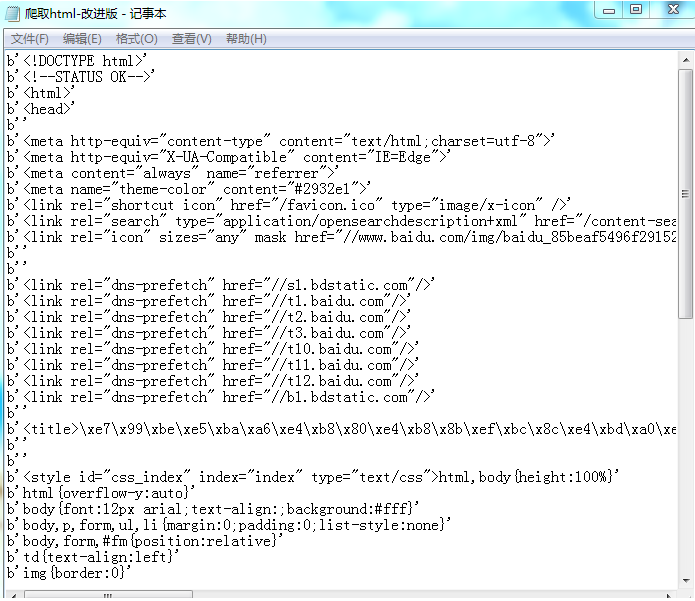
Python爬虫 - 爬取百度html代码前200行的更多相关文章
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- Python爬虫爬取百度贴吧的帖子
同样是参考网上教程,编写爬取贴吧帖子的内容,同时把爬取的帖子保存到本地文档: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urlli ...
- Python爬虫爬取百度贴吧的图片
根据输入的贴吧地址,爬取想要该贴吧的图片,保存到本地文件夹,仅供参考: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urllib2i ...
- Python爬虫爬取百度翻译之数据提取方法json
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统 说明:本例为实现输入中文翻译为英文的小程序,适合Python爬虫的初学者一起学习,感兴趣的可以做英文翻译为中文的 ...
- Python爬虫-爬取百度贴吧帖子
这次主要学习了替换各种标签,规范格式的方法.依然参考博主崔庆才的博客. 1.获取url 某一帖子:https://tieba.baidu.com/p/3138733512?see_lz=1&p ...
- python --爬虫--爬取百度翻译
import requestsimport json class baidufanyi: def __init__(self, trans_str): self.lang_detect_url = ' ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
随机推荐
- android studio——Failed to set up SDK
最近使用android studio ,在IDE里面使用Gradle构建的时候,一直出现构建失败,失败信息显示Failed to set up SDK.然后 提示无法找到andriod-14平台,我更 ...
- 程序员高效Windows环境配置
个人比较追求高效.效率.以下是我常用的windows配置希望对大家有帮助.(身为程序员,我特别喜欢mac pro的retina屏,在那编程简直是一种享受.等我买了mac pro在发一篇 ...
- UNIX网络编程——套接字选项(SO_REUSEADDR)
1.一般来说,一个端口释放后会等待两分钟之后才能再被使用,SO_REUSEADDR是让端口释放后立即就可以被再次使用. SO_REUSEADDR用于对TCP套接字处于TIME_WAIT状态下的sock ...
- Android进阶(二十四)Android UI---界面开发推荐颜色
Android UI---界面开发推荐颜色 在Android开发过程中,总要给app添加一些背景,个人认为使用纯色调便可以达到优雅的视觉效果. 补充一些常用的颜色值:colors.xml < ...
- 存储那些事儿(三):OpenStack的块存储Cinder与商业存储的融合
OpenStack是一个美国国家航空航天局和Rackspace合作研发的云端运算软件,以Apache许可证授权,并且是一个自由软件和开放源代码项目.OpenStack是IaaS(基础设施即服务)软 ...
- 解决 RtlCreateActivationContext() failed 0xc000000d
gtest 示例的Debug版启动报错: Debug输出如下: 'sample1_unittest.exe': Loaded 'D:\LibSrc\gtest_1.7.0_build\Debug\sa ...
- 推荐一个计算机视觉图书:python计算机视觉编程
编辑部的主页:好像没啥用 http://shop.oreilly.com/product/0636920022923.do 每章的代码,github上面的:中文版 https://github.com ...
- MinerHtmlThread.java 爬取页面线程
MinerHtmlThread.java 爬取页面线程 package com.iteye.injavawetrust.miner; import org.apache.commons.logging ...
- Css详解之(选择器)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- H5学习之旅-H5的块标签的使用(9)
块元素的基本语法 1. Html块元素 ,块元素在开始时候通常以新行开始,比如h1,p,ul 2.内联元素,通常不会以新行开始,比如a,b,img 3.html的div元素,div也被称为块元素,其主 ...