Python 爬虫-Requests库入门
2017-07-25 10:38:30
response = requests.get(url, params=None, **kwargs)
- url : 拟获取页面的url链接∙ params : url中的额外参数,字典或字节流格式,可选
- params参数是字典或字节序列,作为参数增加到url中
kv = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.request('GET', 'http://python123.io/ws', params=kv)
>>> print(r.url)
http://python123.io/ws?key1=value1&key2=value2
- **kwargs: 12个控制访问的参数

headers:字典,HTTP定制头
hd = {'user‐agent': 'Chrome/10'}
r = requests.request('POST', 'http://python123.io/ws', headers=hd)
timeout : 设定超时时间,秒为单位
r = requests.request('GET', 'http://www.baidu.com', timeout=10)
proxies : 字典类型,设定访问代理服务器,可以增加登录认证
>>> pxs = { 'http': 'http://user:pass@10.10.10.1:1234'
'https': 'https://10.10.10.1:4321' }
>>> r = requests.request('GET', 'http://www.baidu.com', proxies=pxs)
使用举例:
import requests # r:response 右侧get: requests
r = requests.get('http://jwc.seu.edu.cn/')
一、返回值Response对象的属性
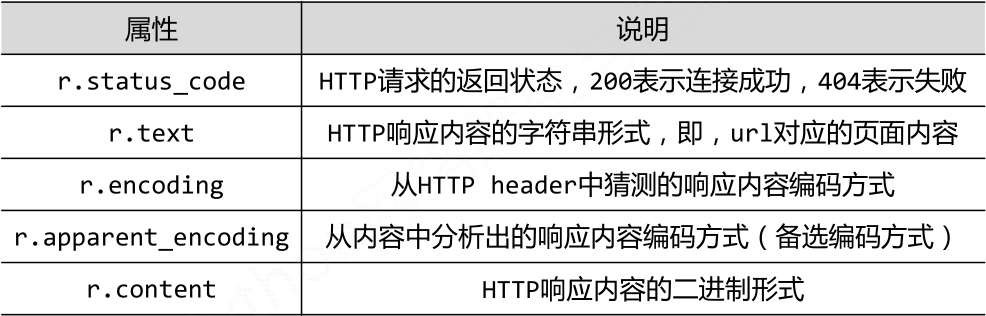


二、爬取网页的通用代码框架
import requests def gethtml(url):
# 打开网页有风险,需要使用try-except语句进行风险控制
try:
r = requests.get(url)
r.raise_for_status() # 如果打开失败,则会抛出一个HttpError异常
# encoding是从header中分析出来的编码方式,apparent_encoding是 从内容分析出的编码方式
r.encoding=r.apparent_encoding
return r.text
except:
print("打开失败")
三、requests库的方法和HTTP协议
- HTTP协议:超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:http://host[:port][path]
HTTP协议对资源的操作方法:

其中get,head方法是从服务器取回数据,post,put,patch,delete方法是向服务器写入或者修改数据。
patch 和 put 的区别:patch 是局部更新,而put 是全部更新。patch节省网络带宽,是HTTP协议改良后的新增指令。
HTTP的指令和requests 的方法一一对应。
- Requests 的七个主要方法

Python 爬虫-Requests库入门的更多相关文章
- Python爬虫—requests库get和post方法使用
目录 Python爬虫-requests库get和post方法使用 1. 安装requests库 2.requests.get()方法使用 3.requests.post()方法使用-构造formda ...
- Python爬虫--Requests库
Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,requests是python实现的最简单易用的HTTP库, ...
- 【Python成长之路】Python爬虫 --requests库爬取网站乱码(\xe4\xb8\xb0\xe5\xa)的解决方法【华为云分享】
[写在前面] 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\ ...
- Python爬虫 requests库基础
requests库简介 requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支 ...
- python爬虫---requests库的用法
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下 ...
- Python爬虫---requests库快速上手
一.requests库简介 requests是Python的一个HTTP相关的库 requests安装: pip install requests 二.GET请求 import requests # ...
- python爬虫——requests库使用代理
在看这篇文章之前,需要大家掌握的知识技能: python基础 html基础 http状态码 让我们看看这篇文章中有哪些知识点: get方法 post方法 header参数,模拟用户 data参数,提交 ...
- Python爬虫的简单入门(一)
Python爬虫的简单入门(一) 简介 这一系列教学是基于Python的爬虫教学在此之前请确保你的电脑已经成功安装了Python(本教程使用的是Python3).爬虫想要学的精通是有点难度的,尤其是遇 ...
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
随机推荐
- C++编译器模板机制剖析
思考:为什么函数模板可以和函数重载放在一块.C++编译器是如何提供函数模板机制的? 一.编译器编译原理 什么是gcc gcc(GNU C Compiler)编译器的作者是Richard Stallma ...
- zw版【转发·台湾nvp系列Delphi例程】HALCON SmallestRectangle2
zw版[转发·台湾nvp系列Delphi例程]HALCON SmallestRectangle2 procedure TForm1.Button1Click(Sender: TObject);var ...
- 【译】在Asp.Net中操作PDF - iTextSharp - 利用列进行排版(转)
[译]在Asp.Net中操作PDF - iTextSharp - 利用列进行排版 在使用iTextSharp通过ASP.Net生成PDF的系列文章中,前面的文章已经讲述了iTextSharp所涵盖 ...
- 安装rocketmq-console
一.alibaba版本 使用rocketmq命令查看集群状态,查看topic信息时比较麻烦,而且不直观,这个时候可以使用一些web页面来管理rocketmq. 以前曾使用过一个老版本的工具,适用于al ...
- linux常用命令(替换)
1. vi 模式下的替换命令: s 表示替换(substitute),g表示全局搜索(global search) :s/vivian/sky/ 替换当前行第一个 vivian 为 sky :s/vi ...
- web前端----JavaScript的DOM(三)
一.JS中for循环遍历测试 for循环遍历有两种 第一种:是有条件的那种,例如 for(var i = 0;i<ele.length;i++){} 第二种:for (var i in l ...
- MySQL数据库----事务
事务 -- 事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,-- 即可回滚到原来的状态,从而保证数据库数据完整性.-- 事务也就是要么都成功,要么都不成功-- 事务就是由一堆sql ...
- TED #10# A rite of passage for late life
Bob Stein: A rite of passage for late life Collection I grew up white, secular and middle class in 1 ...
- Jquery获取敲击回车时光标所在的位置
$(document).keyup(function(event){ ){ //是否是回车 var el = event.srcElement || event.target; var input_t ...
- jquery的click无法触发事件
一个页面需要在加载后勾选table中所有行的checkbox,于是就这样写 $("table thead tr th input[type='checkbox']").click( ...