ORM执行SQL 双下划线查询 ORM外键字段创建 外键字段相关操作 ORM跨表查询 跨表查询进阶操作
ORM执行SQL语句
有时候ORM的操作效率比原生SQL效率低 django支持我们自己编写SQL语句。
如何在django中使用原生SQL?
方式1:使用pymysql模块
方式2:使用raw方法
models.User.objects.raw('select * from app01_user;')
得到RawQuerySet对象:
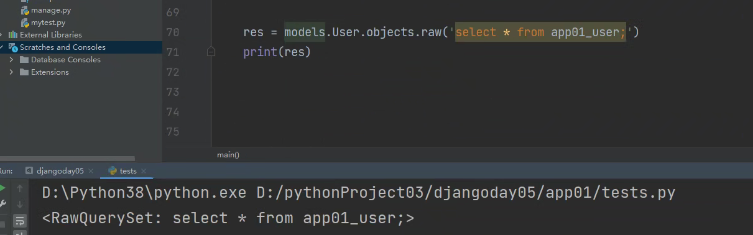
使用query方法查看SQL:
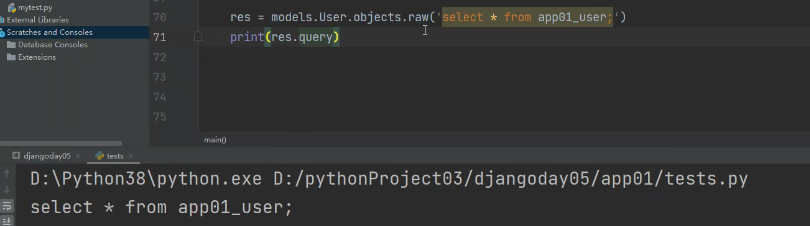
使用for循环才能打印,raw方法查询到的数据值:
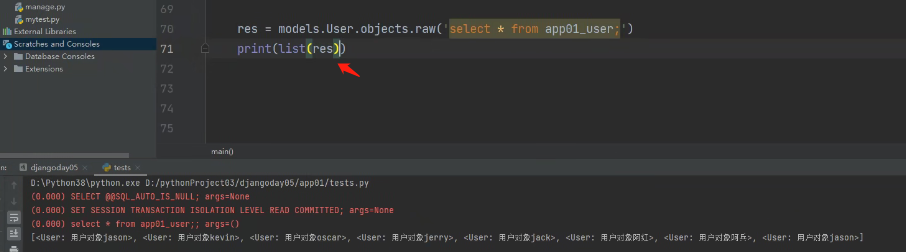
list底层就是for循环。
方式3:django connection
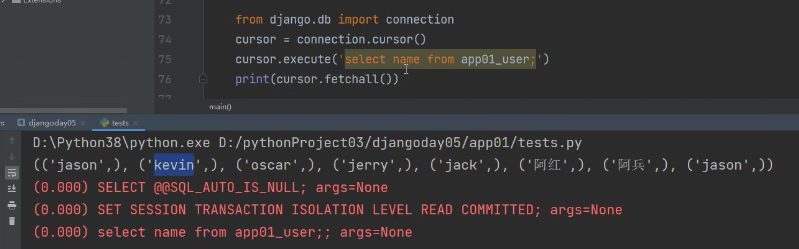
from django.db import connection
cursor = connection.cursor()
cursor.execute('select name from app01_user;')
print(cursor.fetchall())
使用django自带模块,类似pymysql。(这个模块底层也是使用了pymysql)
还有第四种方式extra,省略。
双下划线查询
'''
只要还是queryset对象就可以无限制的点queryset对象的方法
queryset.filter().values().filter().values_list().filter()...
'''
# 查询年龄大于18的用户数据
# res = models.User.objects.filter(age__gt=18)
# print(res)
# 查询年龄小于38的用户数据
# res = models.User.objects.filter(age__lt=38)
# print(res)
# 大于等于 小于等于
# res = models.User.objects.filter(age__gte=18)
# res = models.User.objects.filter(age__lte=38)
# 查询年龄是18或者28或者38的数据
# res = models.User.objects.filter(age__in=(18, 28, 38))
# print(res)
# 查询年龄在18到38范围之内的数据
# res = models.User.objects.filter(age__range=(18, 38))
# print(res)
# 查询名字中含有字母j的数据
# res = models.User.objects.filter(name__contains='j') # 区分大小写
# print(res)
# res = models.User.objects.filter(name__icontains='j') # 不区分大小写
# print(res)
# 查询注册年份是2022的数据
# res = models.User.objects.filter(register_time__year=2022)
# print(res)
'''针对django框架的时区问题 是需要配置文件中修改的 后续bbs讲解'''
__gt(>) __lt(<)
以题目来学习如何使用双下划线查询。
- 查询年龄大于十八岁的用户数据
我们的filter函数不支持大于号小于号。

这样写会报错。
此时就可以使用__gt:
注意:这里的age是user表内的一个字段名。
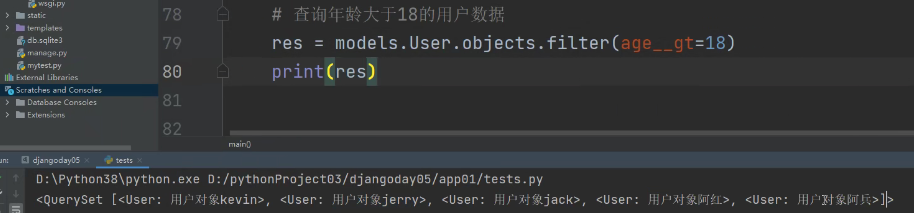
gt表示大于,lt表示小于。这里就查询出来了年龄大于十八的用户对象。
查询年龄小于三十八的用户:

queryset对象特性
只要还是queryset对象就可以无限制的点queryset对象的方法。

如这里,我们筛选处理年龄大于18的用户对象,可以再点values拿到这些用户中的字段。先筛选数据,再决定拿什么字段。
甚至可以继续点:
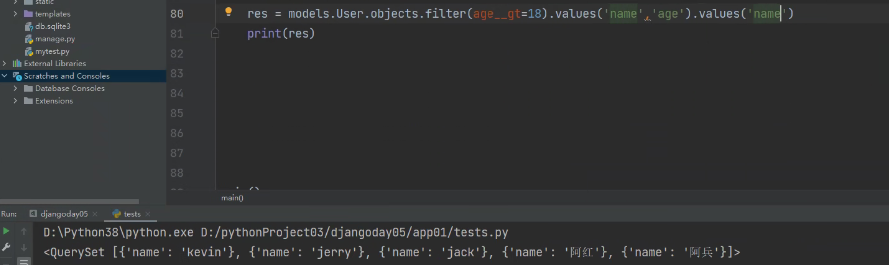
把queryset理解成一个结果集,每次点就是加限制条件,从中筛选出一部分。
queryset的特性展示2:
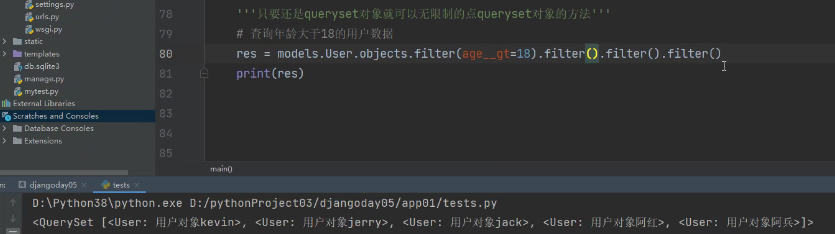
多次点filter方法也没事,结果跟点一次相同。
__gte(≥) __lte(≤)
在__gt的基础上加个e,就变成了大于等于。小于等于也同理。

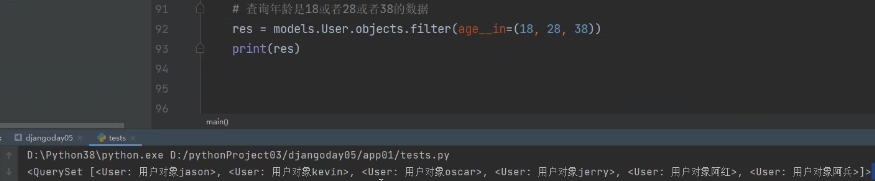
__in
查询年龄是18或者28或者38的数据:
__range
查询年龄在18到38范围之内的数据:
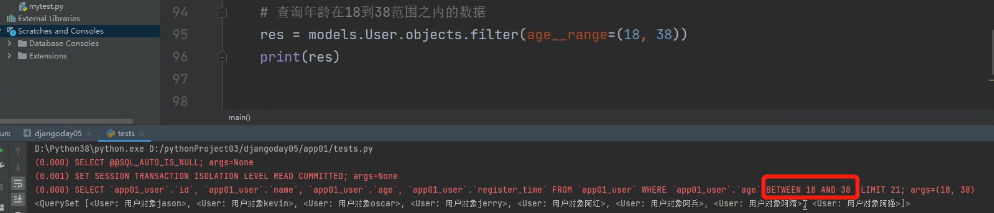
相当于原生SQL中的between。
__contains __icontains
查询名字中含有字母j的数据:
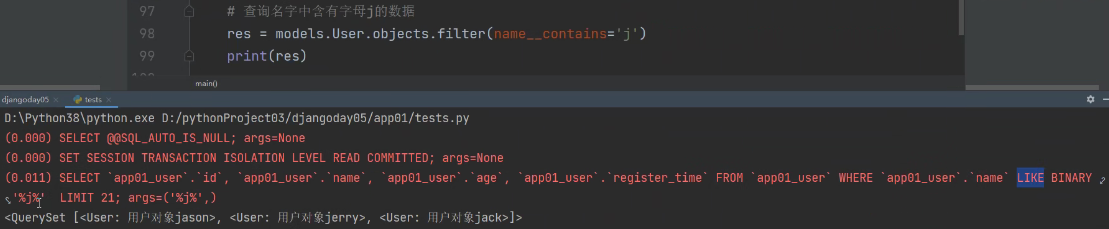
相当于原生SQL中的模糊查询(like)
使用__contains能不能区分大小写:(可以)
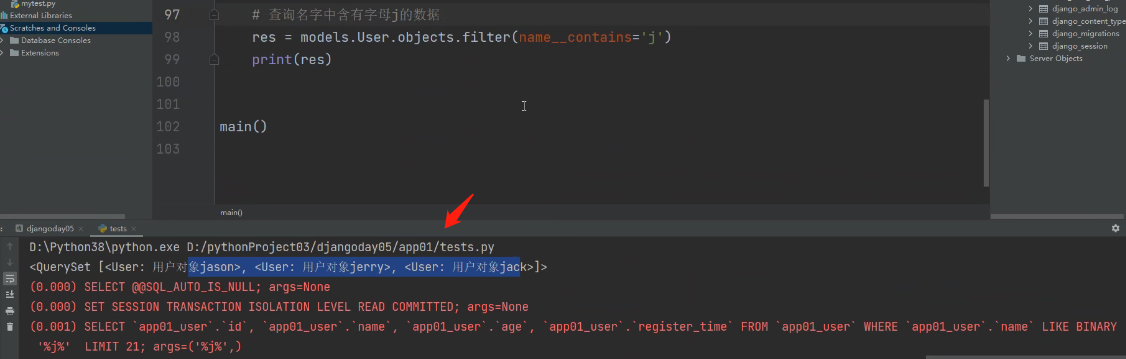
这里不会查找名字中含有大写J的数据。
如果想要其不区分大小写,可以使用:__icontains:

查看结果:

__year
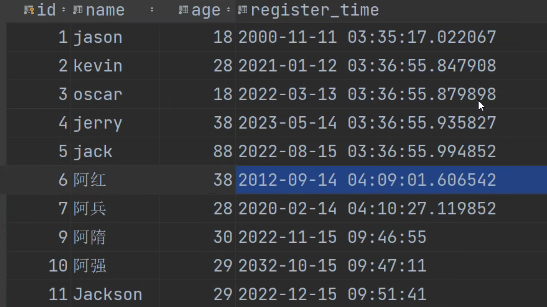
查看我们的数据表:
查询出注册年份是2022年的数据:(只按照年份筛
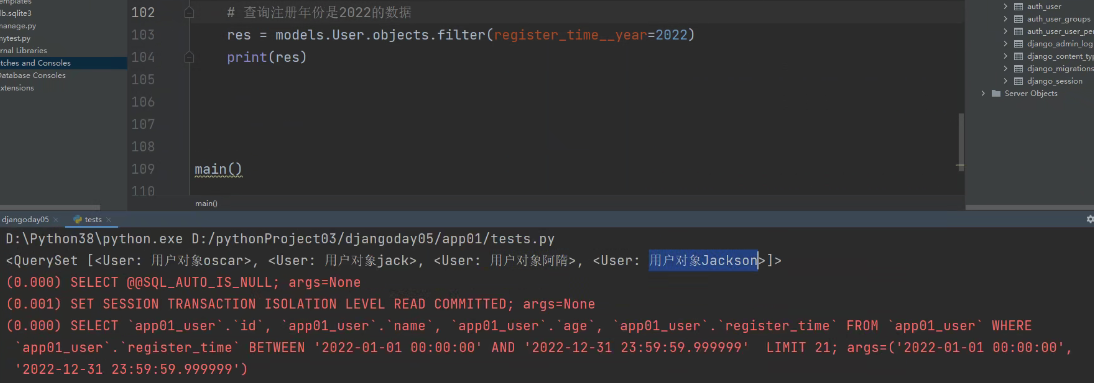
注意:register_time是User表的字段名。
查询注册月份是12月的数据:
还可以按照时间字段的月份筛,但是要改配置,后续bbs讲解这个问题。
要在setting配一下 TIME_ZONE。

关于按照时间字段筛查还有很多方法:
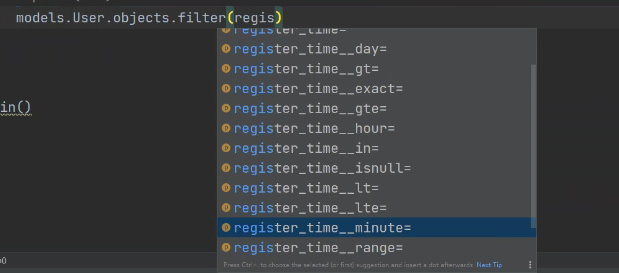
年份和月份结合一起查询也可以。
ORM外键字段的创建
回顾外键表关系
'''
复习MySQL外键关系
一对多
外键字段建在多的一方
多对多
外键字段统一建在第三张关系表
一对一
建在任何一方都可以 但是建议建在查询频率较高的表中
ps:关系的判断可以采用换位思考原则 熟练的之后可以瞬间判断
'''
1.创建基础表
创建的表有:书籍表、出版社表、作者表、作者详情
创建图书表:

decimalfield 浮点型高精度字段
创建出版社表:

创建作者表:

创建作者详情表:

这里手机号是13位 integerfield存不下。所以用bigintegerfield。
2.确定外键关系
书籍表与出版社表(一对多)
书籍与出版社是一对多关系。
一对多 ORM与MySQL一致。
外键字段建在多的一方,也就是建立在书籍表。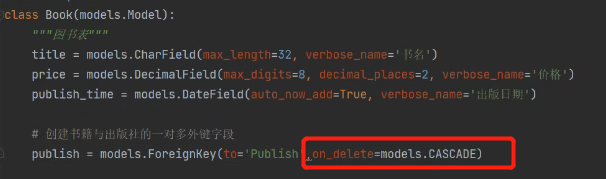
ForeignKey:创建一对多外键。
to:这里的to相当于原生SQL的reference。也就是在book表创建一个publish字段 关联publish表的主键。to后面也可以传一个出版社类,这样ORM也会知道你这个外键字段是要跟这个类绑定,只不过这个列就必须写在to所在类的上面。
示例:
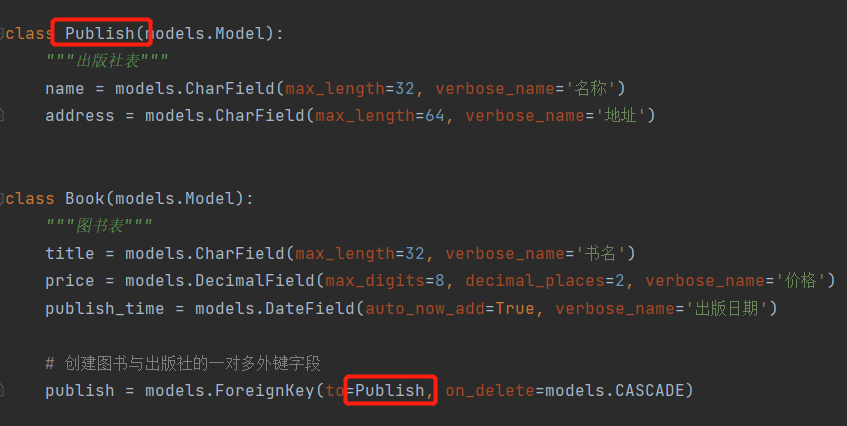
on_delete:这里的表示的是级联删除,级联更新。注意有如下版本区别:
django1.x版本:所有外键字段默认都是级联更新级联删除
django2.x版本:需要自己声明。也就是添加on_delete=models.CASCADE
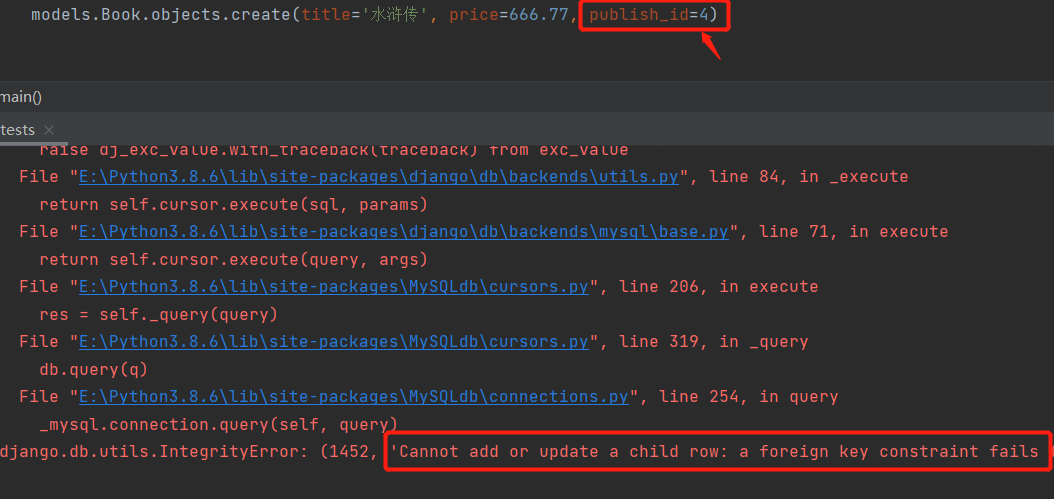
如果不申明会报错:
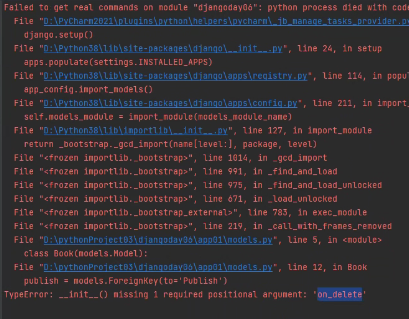
这里还需要注意:
针对一对多和一对一同步到表中之后会自动加_id的后缀
publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE)
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
比如这个一对多外键字段叫publish:
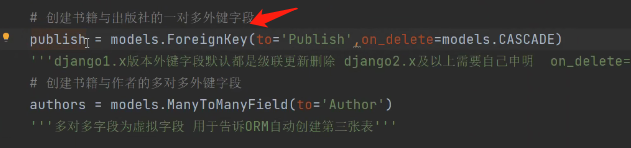
而我们在mysql中创出的表中的字段叫publish_id:

书籍表与作者表(多对多)
书籍表与作者表是多对多关系。
这里建议把外键建立在查询频率较高的书籍表。
在书籍表创建多对多外键字段,使用ManyToManyField方法:
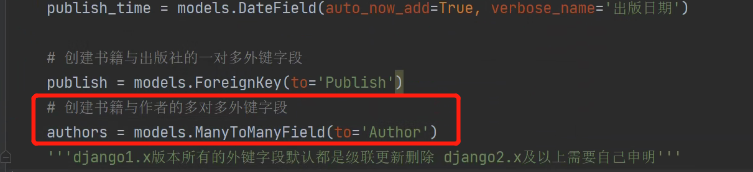
多对多字段为虚拟字段,会告诉Mysql自动创建第三张表,他不会在自己所处的表Book,创建一个新字段author。
除了这种使用虚拟字段创第三张表的方式,还可以自己手动在书籍库创第三张表。且自己手动创也具备一定优势。
作者表与作者详情表(一对一)
由于作者表访问次数较多,所以我们在作者表创建一对一外键字段,使用OneToOneField:
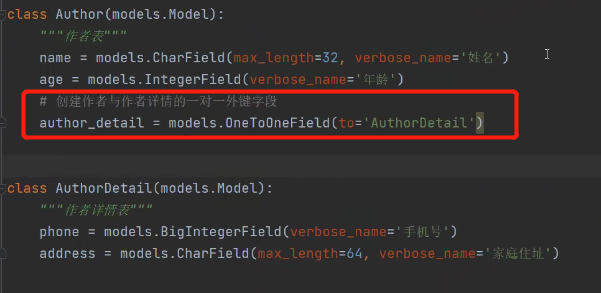
关于一对一、一对多,都需要添加级联删除,也就是需要给上图加一个on_delete=models.CASCADE。
3.表的查看
查看表:
第三张外键表
app01_book_author就是django自动帮你创建的第三张外键表。
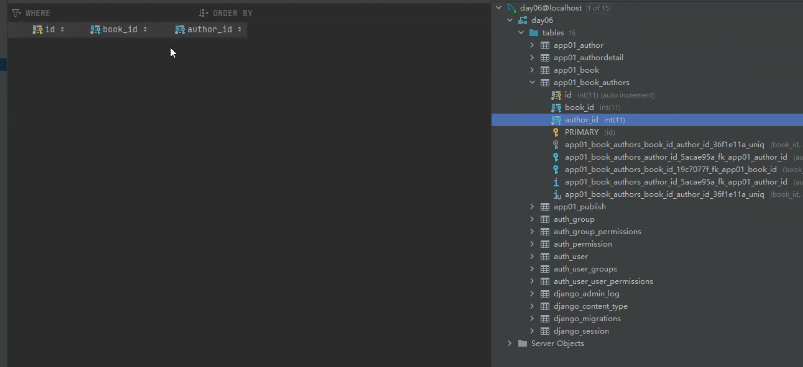
上面的蓝色表示外键字段。可见里面有两个是外键相关联字段。
数据的录入
表的录入顺序:先从没有外键字段的表开始填 除了book表不录 其他表都可以录
作者详情表 --- > 作者表
出版社 ---> 图书表
要先给作者详情表添加数据,再给作者表添加数据。
先给出版社表添加数据,再给图书表添加数据。
外键字段相关操作
建立外键关系
针对一对多关系绑定 create
方式1:直接填写数据库中的实际字段
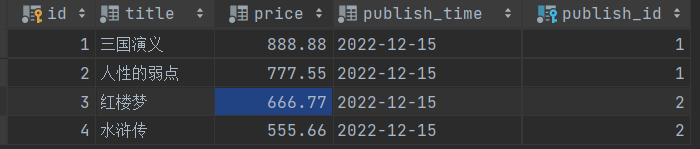
图书表:
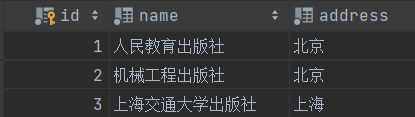
出版社表:
如何在图书表创建新书籍?使用create方法创建新书籍。
models.Book.objects.create(title='三国演义', price=888.88, publish_id=1)
# 这也就是将'三国演义'这本书和'人民教育出版社绑定了'
models.Book.objects.create(title='人性的弱点', price=777.55, publish_id=1)
请注意最后一个参数:publish_id=1
他的意思:数据库中的外键字段 = 被关联表主键值
- publish_id是当前要添加数据的表book的外键字段,注意这个外键字段在类中是publish。
而在mysql中是publish_id(这是因为建表时,orm会自动这么做)
我们在添加书籍时,要使用publish_id - 而publish右边的1,指的是出版社表的主键,由于出版社只有3个,所以当前只能填1、2、3。这里填其他的会报错。
方式2:使用被关联表的对象
publish_obj = models.Publish.objects.filter(pk=1).first()
models.Book.objects.create(title='水浒传', price=555.66, publish=publish_obj)
这里通过查询publish表可以得到出版社对象,这里是'人民教育出版社',也就建立了水浒传--->人民教育出版社的绑定。指定哪个出版社对象,这本书就和哪个出版社绑定。底层是会通过对象自动拿到主键值。
请注意最后一个参数:publish=publish_obj
他的意思:book类中的外键关联字段 = 出版社对象
ps:一对一、一对多的规律是一样的。即可以传数据库中实际字段,也可以传类中字段。
针对多对多关系绑定
使用虚拟字段 add
方法1:给虚拟字段传主键
书籍表:(有虚拟字段)
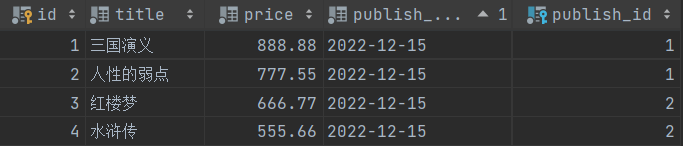
作者表:

多对多关系,我们想在第三张表添加联系。但是这第三张表只存在于数据库,我们无法通过点的方式调用。
还记得虚拟字段吗?
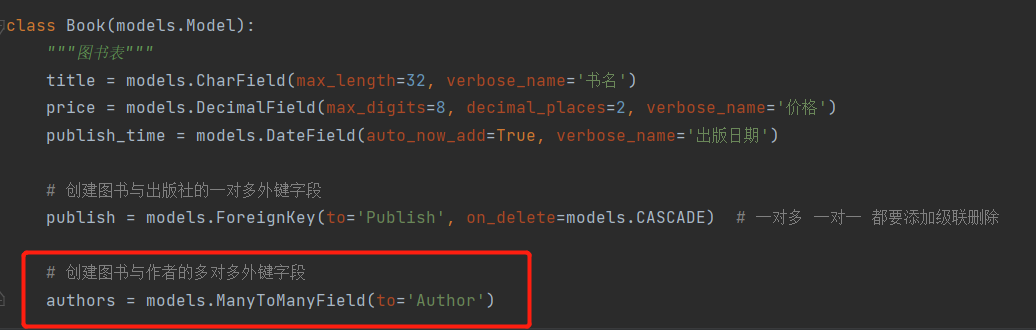
我们拿到书籍对象,书籍对象中有虚拟字段authors。
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.add(1) # 在第三张关系表中给当前书籍绑定作者
book_obj.authors.add(2, 3)
请注意:book_obj.authors.add(2, 3)
相当于:书籍对象.book类中虚拟字段.add(作者2,作者3)
这里的2、3传的是作者表的主键。
可以一次性给书籍添加多个作者。
方法2:给虚拟字段传对象
book_obj = models.Book.objects.filter(pk=4).first()
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
book_obj.authors.add(author_obj1)
book_obj.authors.add(author_obj1, author_obj2)
如上面代码我们还是先获取book类中的虚拟字段,然后使用add方法。只不过这次传递的是作者对象。作者对象中肯定也有一定的信息嘛,可以让我们建立外键联系。
book_obj.authors.add(author_obj1, author_obj2):
书籍对象 和 (作者1,作者2) 建立了外键联系。
修改外键关系
针对多对多绑定 set
通过给虚拟字段传主键
修改外键关系的原理是:将原来的外键关系删除,再新建外键关系。
也就是说,你也可以直接使用set方法建立外键联系。
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.set((1, 3)) # 修改关系 # 将book pk=1 绑定给作者1、作者3
book_obj.authors.set([2, ]) # 修改关系 # 将book pk=1 绑定给作者2
注意:set里需要放入一个可被for循环的对象。
通过给虚拟字段传对象
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
book_obj.authors.set((author_obj1,))
book_obj.authors.set((author_obj1, author_obj2))
原理跟之前类似,通过作者对象获取作者主键值。
删除外键关系
针对多对多绑定
这个删除也是针对多对多的。原理跟之前一样。
book_obj.authors.remove(2) # 删除书籍对象 与 作者2 的外键联系
book_obj.authors.remove(1, 3) # # 删除书籍对象 与 作者1, 作者3 的外键联系
book_obj.authors.remove(author_obj1,)
book_obj.authors.remove(author_obj1,author_obj2)
clear
book_obj.authors.clear():clear可以清除当前对象所有的外键关系。
总结
add()\remove() 多个位置参数(数字 对象)
set() 可迭代对象(元组 列表) 数字 对象
clear() 清除当前数据对象的关系
ORM跨表查询理论
MySQL跨表查询复习
"""
复习MySQL跨表查询的思路
子查询
分步操作:将一条SQL语句用括号括起来当做另外一条SQL语句的条件
连表操作
先整合多张表之后基于单表查询即可
inner join 内连接
left join 左连接
right join 右连接
"""
正反向查询的概念(重要)
正向查询
由外键字段所在的表数据查询关联的表数据 正向
反向查询
没有外键字段的表数据查询关联的表数据 反向
ps:正反向的核心就看外键字段在不在当前数据所在的表中
ORM跨表查询的口诀(重要)
正向查询按外键字段 ()
反向查询按表名小写
基于对象的跨表查询
通过当前类中外键字段
一对多、一对一正向查询
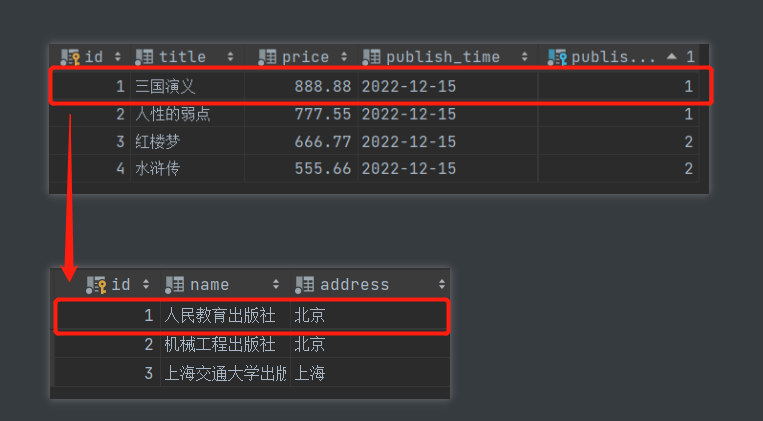
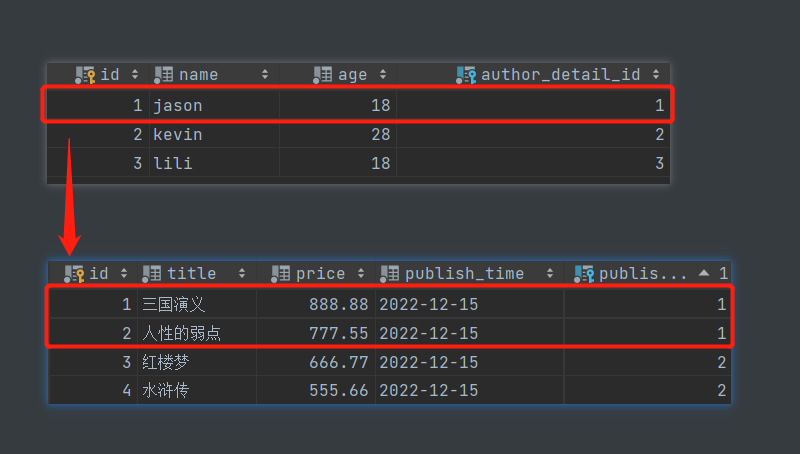
- 查询主键为1的书籍对应的出版社名称
# 先根据条件获取书籍对象
book_obj = models.Book.objects.filter(pk=1).first()
# 再判断正反向的概念 由书查出版社 外键字段在书所在的表中 所以是正向查询
print(book_obj.publish.name)
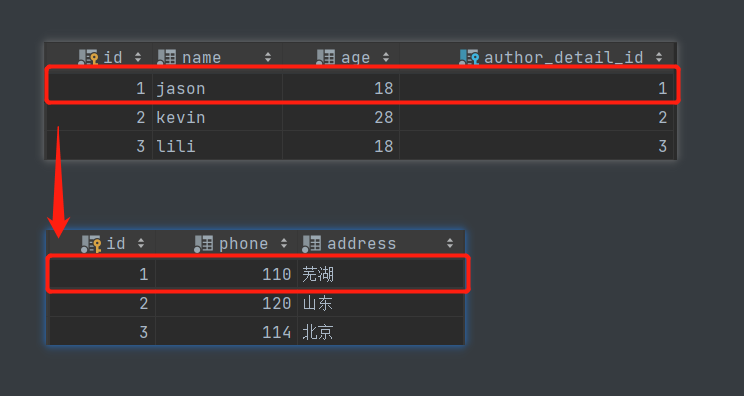
- 查询jason的电话号码
从作者表出发 前往 作者详情表。
外键字段在用户表,所以是一个正向查询。口诀:正向查询按外键字段。类中外键字段是author_detail。
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.author_detail.phone)
多对多正向查询 all
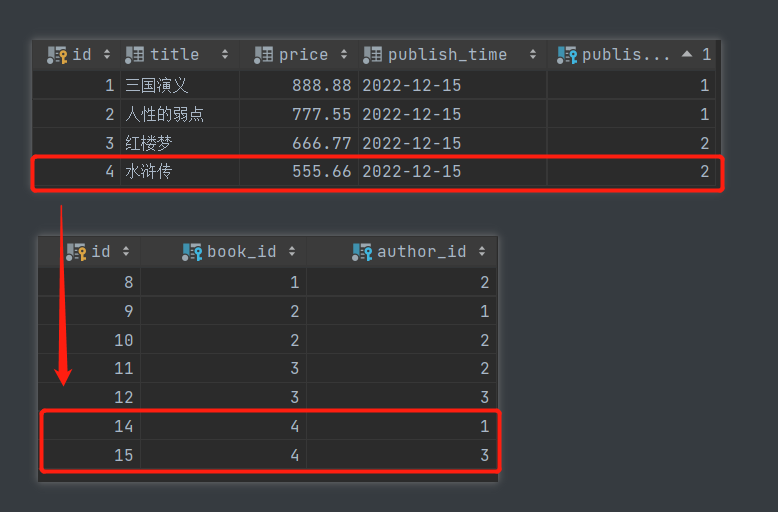
- 查询主键为4的书籍对应的作者姓名
# 先根据条件获取数据对象
book_obj = models.Book.objects.filter(pk=4).first()
# 再判断正反向的概念 由书查作者 外键字段(虚拟字段authors)在书所在的表中 所以是正向查询
print(book_obj.authors) # app01.Author.None
print(book_obj.authors.all())
print(book_obj.authors.all().values('name'))
通过表名小写
多对多反向查询 __set
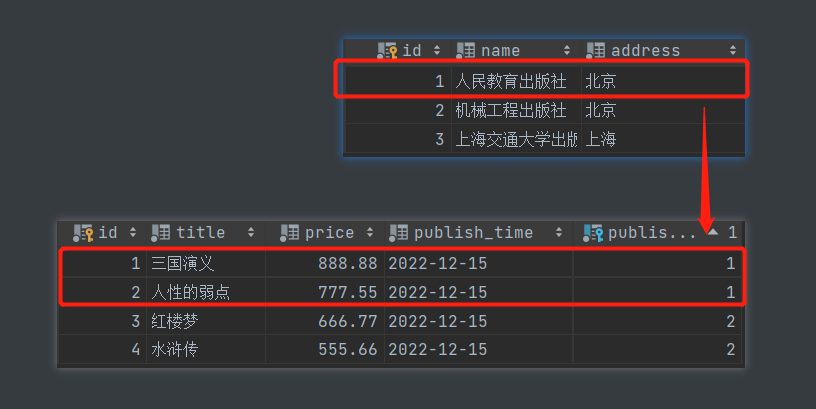
- 查询人民教育出版社出版过的书籍
从出版社出发 前往 书籍表。
由于外键字段在书籍表。所以是反向查询。
口诀:反向查询按表名小写__set。注意这个表名是book,也就是我们的目的地。
由于一个出版社可以发行多本书,所以查询的结果应该是多个。所以这里才要加set。set表示集合,有包含多个的意思。
publish_obj = models.Publish.objects.filter(name='人民教育出版社').first()
print(publish_obj.book_set) # app01.Book.None
print(publish_obj.book_set.all())
- 查询jason写过的书籍
从作者表出发 前往 书籍表。
由于外键字段在书籍表。所以是反向查询。
口诀:反向查询按表名小写__set。
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.book_set) # app01.Book.None
print(author_obj.book_set.all())
一对一、一对多反向查询
- 查询电话号码是110的作者姓名
从作者详情表出发 前往 作者表。
由于外键字段在作者表。所以是反向查询。
口诀:反向查询按表名小写。由于查询的结果是一个,所以不需要用__set
author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()
print(author_detail_obj.author)
print(author_detail_obj.author.name)
基于下划线的跨表查询
- 查询主键为1的书籍对应的出版社名称
从书籍表出发 前往 出版社表。
由于外键字段在书籍表。所以是正向查询。
口诀:正向查询按照类中外键字段。
书籍类中字段为publish。在values支持使用正反向口诀,通过value('publish')可以跳到出版社表,再通过__name获取name字段。
res = models.Book.objects.filter(pk=1).values('publish__name')
print(res)
res1 = models.Book.objects.filter(pk=1).values('publish__name','title') # 也可以拿本地表的数据:书籍的标题(title)
print(res=1)
- 查询主键为4的书籍对应的作者姓名
从书籍表出发 前往 作者表。
由于外键字段在书籍表。所以是正向查询。
口诀:正向查询按照类中外键字段。authors是book类外键字段,通过此外键字段跳转到作者表。
res = models.Book.objects.filter(pk=4).values('title', 'authors__name')
print(res)
- 查询jason的电话号码
从作者表出发 前往 作者详情表。
由于外键字段在作者表。所以是正向查询。
口诀:正向查询按照类中外键字段。
author_detail是作者类外键字段,通过此外键字段跳转到作者详情表。
res = models.Author.objects.filter(name='jason').values('author_detail__phone')
print(res)
- 查询北方出版社出版过的书籍名称和价格
从出版社表出发 前往 书籍表。
由于外键字段在书籍表。所以是反向查询。
口诀:反向查询按照类名小写。我们想去book表,所以values填写book。
res = models.Publish.objects.filter(name='北方出版社').values('book__title','book__price','name')
print(res)
- 查询jason写过的书籍名称
从作者表出发 前往 书籍表。
由于外键字段在书籍表。所以是反向查询。
口诀:反向查询按照类名小写
res = models.Author.objects.filter(name='jason').values('book__title', 'name')
print(res)
- 查询电话号码是110的作者姓名
从作者详情表出发 前往 作者表。
由于外键字段在作者表。所以是反向查询。
口诀:反向查询按照类名小写。我们要去作者表,所以类名小写是author.
res = models.AuthorDetail.objects.filter(phone=110).values('phone', 'author__name')
进阶操作
我们这次反向出发。
- 查询主键为1的书籍对应的出版社名称
从出版社出发 前往 书籍表。
由于外键字段在书籍表。所以是反向查询。
口诀:反向查询按照类名小写。因为要去书籍表所以是book。
注意这里拿到的是出版社对象。
res = models.Publish.objects.filter(book__pk=1).values('name')
print(res)
这里的意思是:查询 出版了 主键为1的书籍 的出版社
2. 查询主键为4的书籍对应的作者姓名
从作者表出发 前往 书籍表。
由于外键字段在书籍表。所以是反向查询。
口诀:反向查询按照类名小写。
res = models.Author.objects.filter(book__pk=4).values('name','book__title')
print(res)
- 查询jason的电话号码
从作者详情表出发 前往 作者表。
由于外键字段在作者表。所以是反向查询。
口诀:反向查询按照类名小写。所以用author.
res = models.AuthorDetail.objects.filter(author__name='jason').values('phone')
print(res)
查询北方出版社出版过的书籍名称和价格
从书籍表出发 前往 出版社表。
由于外键字段在书籍表。所以是正向向查询。
口诀:正向查询按照类中字段。所以是publish。res = models.Book.objects.filter(publish__name='北方出版社').values('title','price')
print(res)查询jason写过的书籍名称
从书籍表出发 前往 作者表。
由于外键字段在书籍表。所以是正向查询。
口诀:正向查询按照类中字段。所以是authors。
res = models.Book.objects.filter(authors__name='jason').values('title')
print(res)
- 查询电话号码是110的作者姓名
从作者表出发 前往 作者详情表。
由于外键字段在作者表。所以是正向查询。
口诀:正向查询按照类中字段。所以是author_detail。
res = models.Author.objects.filter(author_detail__phone=110).values('name')
print(res)
最高境界
orm支持连续跨表
- 查询主键为4的书籍对应的作者的电话号码
res = models.Book.objects.filter(pk=4).values('authors__author_detail__phone')
print(res) # 书籍表 --正向-> 作者表 --正向-> 作者详情表
res = models.AuthorDetail.objects.filter(author__book__pk=4).values('phone')
print(res) # 作者详情表 --反向-> 作者表 ---> 拿到作者详情表对象
res = models.Author.objects.filter(book__pk=4).values('author_detail__phone')
print(res) # 作者表 --反向-> 书籍表 ---> 拿到作者表对象
# 作者表 --正向-> 作者详情表
ORM执行SQL 双下划线查询 ORM外键字段创建 外键字段相关操作 ORM跨表查询 跨表查询进阶操作的更多相关文章
- python面向对象双下划线方法与元类
目录 双下划线方法(__) 元类简介 产生类的两种表现形式 元类的基本使用 元类进阶操作 __new__方法 双下划线方法(__) 面向对象中的双下方法也有一些人称之为是魔法方法,有些双下方法不需要刻 ...
- ORM执行sql语句 双下划线 外键字段创建 ORM跨表查询
目录 模型层之ORM执行SQL语句 方式1一 方式二 方式三 神奇的双下划线查询 ORM外键字段的创建 1.创建基础表 2.确定外键关系 3.表的查看 数据的录入 外键字段相关操作 针对一对多 ''' ...
- ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作
今日内容 ORM执行SQL语句 有时候ROM的操作效率可能偏低 我们是可以自己编写sql的 方式1: models.User.objects.raw('select * from app01_user ...
- ORM执行SQL语句,神奇的双下划线查询,ORM外键字段的创建,外键字段数据的操作,多表查询
ORM执行SQL语句,神奇的双下划线查询,ORM外键字段的创建,外键字段数据的操作,多表查询 一.ORM执行SQL语句 有时候ORM的操作效率较低,我们是可以自己来编写SQL语句的 方式一: res ...
- 12月15日内容总结——ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作
目录 一.ORM执行SQL语句 二.神奇的双下划线查询 三.ORM外键字段的创建 复习MySQL外键关系 外键字段的创建 1.创建基础表(书籍表.出版社表.作者表.作者详情) 2.确定外键关系 3.O ...
- ORM( ORM查询13种方法3. 单表的双下划线的使用 4. 外键的方法 5. 多对多的方法 ,聚合,分组,F查询,Q查询,事务 )
必知必会13条 <1> all(): 查询所有结果 <2> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或 ...
- Django框架之第六篇(模型层)--单表查询和必知必会13条、单表查询之双下划线、Django ORM常用字段和参数、关系字段
单表查询 补充一个知识点:在models.py建表是 create_time = models.DateField() 关键字参数: 1.auto_now:每次操作数据,都会自动刷新当前操作的时间 2 ...
- 测试脚本配置、ORM必知必会13条、双下划线查询、一对多外键关系、多对多外键关系、多表查询
测试脚本配置 ''' 当你只是想测试django中的某一个文件内容 那么你可以不用书写前后端交互的形式而是直接写一个测试脚本即可 脚本代码无论是写在应用下的test.py还是单独开设py文件都可以 ' ...
- python之路50 ORM执行SQL语句 操作多表查询 双下线方法
ORM执行查询SQL语句 有时候ORM的操作效率可能偏低 我们是可以自己编写SQL的 方式1: models.User.objects.raw('select * from app01_user;') ...
- django ORM模型表的一对多、多对多关系、万能双下划线查询
一.外键使用 在 MySQL 中,如果使用InnoDB引擎,则支持外键约束.(另一种常用的MyIsam引擎不支持外键) 定义外键的语法为fieldname=models.ForeignKey(to_c ...
随机推荐
- Petals
------------恢复内容开始------------ 打开发现一堆地址冒红 滑倒后面发现E8,根据经验应该是花指令考点 然后D-->nop-->C-->P得到正常结果 然后第 ...
- GitHub Actions 入门指南
前言 GitHub Actions 可以构建一组自动化的工作流程,并提供了拉取请求.合并分支等事件来触发他们.一般成熟的开源项目会在每个版本发布时提供 releases ,它就是通过 Actions ...
- TechEmpower 22轮Web框架 性能评测:.NET 8 战绩斐然
自从2022年7月第21轮公布的测试以后,一年后 的2023年10月17日 发布了 TechEmpower 22轮测试报告 刚刚发布:Round 22 results - TechEmpower Fr ...
- MySQL数据库的四大语言
DDL数据定义语言 DDL(Data Definition Languages) : 数据定义语言,用来定义数据库的对象(数据库,表,字段)建改库建改表 DDL代码演示 DML数据操作语言 DML(D ...
- typora写作
平时写博客,一般采用typora,但是字体颜色和上传到博客园的图片大小和居中问题,总是很糟糕,偶然发现输入法里面还有自定义的短语,能够解决这个问题. <p><img src=&quo ...
- liunx系统sed命令使用
增 sed '$行数i 新增内容' 文件名在文件里某行上面新增内容 sed '$行数a 新增内容' 文件名在文件里某行下面新增内容 -i.bak对源文件进行修改并备份修改之前源文件 #在文件里第5行上 ...
- liunx二进制包安装5.6MySQL数据库
官网下载对应的二进制版本安装包 https://downloads.mysql.com/archives/community/ # 解压二进制压缩包 [root@localhost ~]# wget ...
- Spring Framework系统架构
- CICD实践1:环境安装篇
一.CICD技术选型 配置管理工具 工具 需求管理工具 使用禅道 代码管理工具 使用Gitlab 编译构建工具 搭建Jenkins,使用Jenkinsfile 制品库工具 nexus 文档管理工具 C ...
- Jenkins 系列:Jenkins 安装(Windows、Mac、Centos)和简介
目录 简介 发展历史 应用场景 Jenkins 安装部署 先决条件 硬件要求 软件包下载 war 包部署 linux 系统部署 mac 系统部署 windows 系统部署 安装后基本配置 解锁 自定义 ...