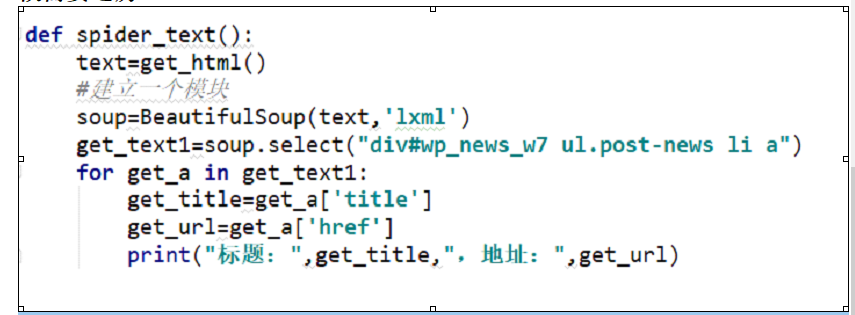
接着上次的python爬虫,今天进阶一哈,局部解析爬取网页数据
*解析网页数据的仓库
用Beatifulsoup基于lxml包
lxml包基于html和xml的标记语言的解析包。可以去解析网页的内容,把我们想要的提取出来。
第二步、先去获取网页的数据
def get_html():
url="http://www.scetc.net"
response=request.get(url)
response.encoding="UTF-8"
return response.text
from bs4 import BeautifulSoup
解析的方式文本格式就是 :
标记#id或者.class,如果有层次标记则空格 在后面加标记就可以了。
请注意一点就是select方法返回的肯定是列表,所以获取数据的时候需要遍历
*下载网上的其他资源
案例就是下载图片资源:
res = requests.get(url+stu_id+".jpg", stream=True)
file=open(stu_id+".jpg",'wb')
for chunk in res.iter_content(chunk_size=32):
file.write(chunk)
file.close()
接着上次的python爬虫,今天进阶一哈,局部解析爬取网页数据的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- [Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息 2018-07-21 23:53:02 larger5 阅读数 4123更多 分类专栏: 网络爬虫 版权声明: ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- 另类爬虫:从PDF文件中爬取表格数据
简介 本文将展示一个稍微不一样点的爬虫. 以往我们的爬虫都是从网络上爬取数据,因为网页一般用HTML,CSS,JavaScript代码写成,因此,有大量成熟的技术来爬取网页中的各种数据.这次, ...
随机推荐
- php数据类型之 NULL类型
空在英文里面表示是null,它是代表没有.空(null)不是false,不是0,也不是空格. [重点]知道null产生的三种情况,学习empty 和 isset两个函数的区别.大理石平台怎么样 主要有 ...
- vue报错 :NavigationDuplicated {_name: "NavigationDuplicated", name: "NavigationDuplicated"}
解决的几种办法 https://blog.csdn.net/weixin_43202608/article/details/98884620 这个适合所有vue的UI框架 在main.js下添加一下代 ...
- BCB6常用快捷键
:: 项目管理类 :: F10 代码窗口全屏显示时切换到BCB的主窗口 Ctrl + F12 打开源文件清单对话框 ...
- shiro 配置注解异常 java.lang.ClassNotFoundException: org.aspectj.util.PartialOrder$PartialComparable
解决方案: pom 文件添加: <!-- 解决shiro注解(shiro 使用 aop) --> <dependency> <groupId>aspectj< ...
- SpringMVC 捕获参数绑定失败时的异常
SpringMVC配置数据验证(JSR-303)中提到了用String类型的域来绑定Ajax中的非法类型的参数. 这样做的目的是一旦发生一种情况,后端可以返回一个自定类的返回值,而不是返回Spring ...
- mysql IFNULL函数和COALESCE函数使用技巧
IFNULL() 函数 IFNULL() 函数用于判断第一个表达式是否为 NULL,如果为 NULL 则返回第二个参数的值,如果不为 NULL 则返回第一个参数的值. IFNULL() 函数 ...
- Entity Framework 一个表多个外键关联另外一张表的相同主键
一. 报错 异常:System.Data.Entity.Infrastructure.DbUpdateException: 更新条目时出错.有关详细信息,请参阅内部异常. ---> System ...
- JAVA基础知识|java虚拟机(JVM)
一.JVM简介 java语言是跨平台的,兼容各种操作系统.实现跨平台的基石就是虚拟机(JVM),虚拟机不是跨平台的,所以不同的操作系统需要安装不同的jdk版本(jre=jvm+类库:jdk=jre+开 ...
- RDD java API使用
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- SpringBoot缓存技术
一.SpringBoot整合Ehhcache 添加maven依赖 <dependency> <groupId>org.springframework.boot</grou ...