基于Caffe的DeepID2实现(中)
小喵的唠叨话:我们在上一篇博客里面,介绍了Caffe的Data层的编写。有了Data层,下一步则是如何去使用生成好的训练数据。也就是这一篇的内容。
小喵的博客:http://www.miaoerduo.com
博客原文:http://www.miaoerduo.com/deep-learning/基于caffe的deepid2实现(中).html
二、精髓,DeepID2 Loss层
DeepID2这篇论文关于verification signal的部分,给出了一个用于监督verification的loss。

其中,fi和fj是归一化之后的特征。
当fi和fj属于同一个identity的时候,也就是yij=1时,loss是二者的L2距离,约束使得特征更为相近。
当fi和fj不属于同一个identity的时候,即yij=-1,这时的loss表示什么呢?参数m又表示什么?
m在这里是margin的意思,是一个可以自行设置的参数,表示期望的不同identity的feature之间的距离。当两个feature的大于margin时,说明网络已经可以很好的区分这两个特征,因此这是loss为0,当feature间的距离小于margin时,loss则为(m-|fi - fj|)^2,表示还需要两个特征能够更好的区分。因此这个loss函数比较好的反应了我们的需求,也就是DeepID2的算法思想。
这个Loss层实现起来似乎并不麻烦,前馈十分的简单。至于后馈,求导也非常简单。但是Caffe加入新层,需要在caffe.proto文件中,做一些修改,这也是最困扰小喵的地方。
不过有个好消息就是:Caffe官网增加了ContrastiveLossLayer这个层!
官网的文件描述如下:
Computes the contrastive loss
where
. This can be used to train siamese networks.
和我们的需要是一样的。因此我们不需要自己实现这个层。
喜大普奔之余,小喵也专门看了Caffe的文档,以及这里提到了siamese network,发现这个网络使用ContrastiveLossLayer的方式比较独特,Caffe项目中的examples中有例子,感兴趣可以看看。
ContrastiveLossLayer的输入,也就是bottom有三部分,feature1、feature2、label,feature1和feature2是分别对应的两组feature,而label则表示该对feature是否是属于同一个identity,是的话,则为1,不是则为0。而且该层还提供一个参数margin,也就是论文的公式里面的m。
最终的结论就是,虽然我们不需要自己写Loss层,但是还是必须增加一些额外的层。
主要有2个,用于将特征归一化的NormalizationLayer以及用于将feature层转换成ContrastiveLossLayer的输入的层,不妨命名为ID2SliceLayer。
三、小问题,大智慧之Normalization Layer
这个归一化的层用于将输入的feature map进行归一化。Caffe官网并没有提供相关的层,因此我们必须自己实现(或者从网上找),这里我们还是选择自己来实现,顺便学习一下Caffe加层的技巧。
Normalization层的前馈非常的简单,输入为一个向量x,输出为归一化之后的向量:
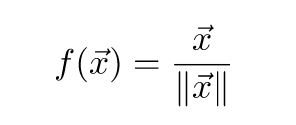
至于后馈,需要求导,计算稍微有点复杂,小喵在推导4遍之后才给出如下表达式:
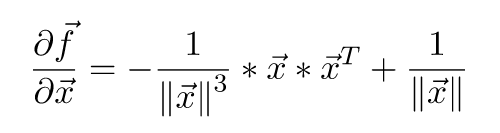
其中x为输入的特征向量,为列向量。这里是将整个feature map看做一个列向量。
知道了前馈后馈的计算规则,那么很容易编写自己的层了,这里小喵建议大家找个Caffe已经有了的内容相近的层,照着改写。比如这个Normalization层,没有任何层的参数,所以照着ReLU类似的层就很好编写。
之后就祭出我们的code:
// create by miao
// 主要实现了feature的归一化
#ifndef CAFFE_NORMALIZATION_LAYER_HPP_
#define CAFFE_NORMALIZATION_LAYER_HPP_ #include <vector> #include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h" #include "caffe/layers/neuron_layer.hpp" namespace caffe { template <typename Dtype>
class NormalizationLayer : public NeuronLayer<Dtype> {
public:
explicit NormalizationLayer(const LayerParameter& param)
: NeuronLayer<Dtype>(param) {}
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline const char* type() const { return "Normalization"; }
virtual inline int ExactNumBottomBlobs() const { return ; }
virtual inline int ExactNumTopBlobs() const { return ; } protected:
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
Blob<Dtype> norm_val_; // 记录每个feature的模
}; } // namespace caffe #endif // CAFFE_NORMALIZATION_LAYER_HPP_
这个层的头文件异常的简单,和ReLU的仅有的区别就是类的名字不一样,而且多了个成员变量norm_val_,用来记录每个feature的模值。
// create by miao
#include <vector>
#include <cmath>
#include "caffe/layers/normalization_layer.hpp"
#include "caffe/util/math_functions.hpp" namespace caffe { template <typename Dtype>
void NormalizationLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
NeuronLayer<Dtype>::LayerSetUp(bottom, top);
CHECK_NE(top[], bottom[]) << this->type() << " Layer does not "
"allow in-place computation.";
norm_val_.Reshape(bottom[]->shape(), , , ); // 申请norm的内存
} template <typename Dtype>
void NormalizationLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { Dtype *norm_val_cpu_data = norm_val_.mutable_cpu_data();
for (int n = ; n < bottom[]->shape(); ++ n) {
// 计算每个c * h * w的区域的模
norm_val_cpu_data[n] = std::sqrt(static_cast<float>(
caffe_cpu_dot<Dtype>(
bottom[]->count(),
bottom[]->cpu_data() + bottom[]->offset(n),
bottom[]->cpu_data() + bottom[]->offset(n)
)
));
// 将每个bottom归一化,输出到top
caffe_cpu_scale<Dtype>(
top[]->count(),
. / norm_val_cpu_data[n],
bottom[]->cpu_data() + bottom[]->offset(n),
top[]->mutable_cpu_data() + top[]->offset(n)
);
}
} template <typename Dtype>
void NormalizationLayer<Dtype>::Backward_cpu(
const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) { const Dtype *norm_val_cpu_data = norm_val_.cpu_data();
const Dtype *top_diff = top[]->cpu_diff();
Dtype *bottom_diff = bottom[]->mutable_cpu_diff();
const Dtype *bottom_data = bottom[]->cpu_data(); caffe_copy(top[]->count(), top_diff, bottom_diff); for (int n = ; n < top[]->shape(); ++ n) {
Dtype a = - ./(norm_val_cpu_data[n] * norm_val_cpu_data[n] * norm_val_cpu_data[n]) * caffe_cpu_dot<Dtype>(
top[]->count(),
top_diff + top[]->offset(n),
bottom_data + bottom[]->offset(n)
);
Dtype b = . / norm_val_cpu_data[n];
caffe_cpu_axpby<Dtype>(
top[]->count(),
a,
bottom_data + bottom[]->offset(n),
b,
bottom_diff + top[]->offset(n)
);
}
}
#ifdef CPU_ONLY
STUB_GPU(NormalizationLayer);
#endif INSTANTIATE_CLASS(NormalizationLayer);
REGISTER_LAYER_CLASS(Normalization); } // namespace caffe
最后就是GPU部分的代码,如果不在乎性能的话,直接在CUDA的前后馈里面调用CPU版的前后馈就行。当然如果了解CUDA的话,完全可以写一份GPU版的代码。小喵这里就偷懒了一下。。。
// create by miao
#include <vector>
#include <cmath>
#include "caffe/layers/normalization_layer.hpp"
#include "caffe/util/math_functions.hpp" namespace caffe { template <typename Dtype>
void NormalizationLayer<Dtype>::Forward_gpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
this->Forward_cpu(bottom, top);
} template <typename Dtype>
void NormalizationLayer<Dtype>::Backward_gpu(
const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
this->Backward_cpu(top, propagate_down, bottom);
}
INSTANTIATE_LAYER_GPU_FUNCS(NormalizationLayer);
} // namespace caffe
这样,我们就写完了Normalization层的所有代码。
对于比较老版本的Caffe,还需要修改/caffe_root/src/caffe/caffe.proto文件。而新版的Caffe只要在新增参数的情况下才需要修改。我们的这个Normalization层并没有用到新的参数,因此并不需要修改caffe.proto文件。
至于新版的Caffe为什么这么智能,原因其实就在这两行代码:
INSTANTIATE_CLASS(NormalizationLayer);
REGISTER_LAYER_CLASS(Normalization);
宏INSTANTIATE_CLASS在/caffe_root/include/caffe/common.hpp中定义。
宏REGISTER_LAYER_CLASS在/caffe_root/include/caffe/layer_factory.hpp中定义。
感兴趣可以自行查阅。
如果您觉得本文对您有帮助,那请小喵喝杯茶吧~~O(∩_∩)O~~

转载请注明出处~
基于Caffe的DeepID2实现(中)的更多相关文章
- 基于Caffe的DeepID2实现(下)
小喵的唠叨话:这次的博客,真心累伤了小喵的心.但考虑到知识需要巩固和分享,小喵决定这次把剩下的内容都写完. 小喵的博客:http://www.miaoerduo.com 博客原文: http://ww ...
- 基于Caffe的DeepID2实现(上)
小喵的唠叨话:小喵最近在做人脸识别的工作,打算将汤晓鸥前辈的DeepID,DeepID2等算法进行实验和复现.DeepID的方法最简单,而DeepID2的实现却略微复杂,并且互联网上也没有比较好的资源 ...
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- 人脸识别(基于Caffe)
人脸识别(基于Caffe, 来自tyd) 人脸识别(判断是否为人脸) LMDB(数据库, 为Caffe支持的分类数据源) mkdir face_detect cd face_detect mkdir ...
- Caffe系列4——基于Caffe的MNIST数据集训练与测试(手把手教你使用Lenet识别手写字体)
基于Caffe的MNIST数据集训练与测试 原创:转载请注明https://www.cnblogs.com/xiaoboge/p/10688926.html 摘要 在前面的博文中,我详细介绍了Caf ...
- 人脸检测数据源制作与基于caffe构架的ALEXNET神经网络训练
本篇文章主要记录的是人脸检测数据源制作与ALEXNET网络训练实现检测到人脸(基于caffe). 1.数据获取 数据获取: ① benchmark是一个行业的基准(数据库.论文.源码.结果),例如WI ...
- 基于Caffe ResNet-50网络实现图片分类(仅推理)的实验复现
摘要:本实验主要是以基于Caffe ResNet-50网络实现图片分类(仅推理)为例,学习如何在已经具备预训练模型的情况下,将该模型部署到昇腾AI处理器上进行推理. 本文分享自华为云社区<[CA ...
- 基于Vivado HLS在zedboard中的Sobel滤波算法实现
基于Vivado HLS在zedboard中的Sobel滤波算法实现 平台:zedboard + Webcam 工具:g++4.6 + VIVADO HLS + XILINX EDK + ...
随机推荐
- 07.LoT.UI 前后台通用框架分解系列之——轻巧的文本编辑器
LoT.UI汇总:http://www.cnblogs.com/dunitian/p/4822808.html#lotui 上次说的是强大的百度编辑器 http://www.cnblogs.com/d ...
- Python的单元测试(一)
title: Python的单元测试(一) author: 青南 date: 2015-02-27 22:50:47 categories: Python tags: [Python,单元测试] -- ...
- 如何正确使用日志Log
title: 如何正确使用日志Log date: 2015-01-08 12:54:46 categories: [Python] tags: [Python,log] --- 文章首发地址:http ...
- Mysql事务探索及其在Django中的实践(一)
前言 很早就有想开始写博客的想法,一方面是对自己近期所学知识的一些总结.沉淀,方便以后对过去的知识进行梳理.追溯,一方面也希望能通过博客来认识更多相同技术圈的朋友.所幸近期通过了博客园的申请,那么今天 ...
- 启用 Open vSwitch - 每天5分钟玩转 OpenStack(127)
Linux Bridge 和 Open vSwitch 是目前 OpenStack 中使用最广泛的两种虚机交换机技术. 前面各章节我们已经学习了如何用 Linux Bridge 作为 ML2 mech ...
- 【夯实PHP基础】UML序列图总结
原文地址 序列图主要用于展示对象之间交互的顺序. 序列图将交互关系表示为一个二维图.纵向是时间轴,时间沿竖线向下延伸.横向轴代表了在协作中各独立对象的类元角色.类元角色用生命线表示.当对象存在时,角色 ...
- BPM Domino集成解决方案
一.需求分析 Lotus Notes/Domino是IBM的协同办公平台,在国内有广泛的用户. 但由于推出年头较早.采用文档数据库等特点, 导致其流程集成能力弱.统计分析难.不支持移动办公等问题,很多 ...
- git远程库GitHub
首先,注册一个GitHub(github.com)帐号,免费获得Git远程仓库 由于本地Git仓库和GitHub仓库之间的传输是通过SSH加密的,所以,需要一点设置: 第1步:创建SSH Key.在用 ...
- git和pycharm管理代码
首先明白三个概念,服务器代码库,本地代码库,和正在coding的项目. coding完毕后,先通过commit提交到本地代码库,然后通过push再提交server的代码库 git步骤 git c ...
- 初学DirectX11, 留个纪恋。
以前学的是openGL, 最近才开始学DirectX11,写了个很垃圾的代码,怀念以前的glPushMatrix(), glPopMatrix(), glBegin(), glEnd(), 多简单啊, ...