hive学习笔记之五:分桶
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
《hive学习笔记》系列导航
本篇概览
本文是《hive学习笔记》的第五篇,前文学习了分区表,很容易发现分区表的问题:
- 分区字段的每个值都会创建一个文件夹,值越多文件夹越多;
- 不合理的分区会导致有的文件夹下数据过多,有的过少;
此时可以考虑分桶的方式来分解数据集,分桶原理可以参考MR中的HashPartitioner,将指定字段的值做hash后,根据桶的数量确定该记录放在哪个桶中,另外,在join查询和数据取样时,分桶都能提升查询效率;
- 接下来开始实战;
配置
- 执行以下设置,使得hive根据桶的数量自动调整上一轮reducers数量:
set hive.enforce.bucketing = true;
- 如果不执行上述设置,您需要自行设置mapred.reduce.tasks参数,以控制reducers数量,本文咱们配置为hive自动调整;
准备数据
接下来先准备外部表t13,往里面添加一些数据,将t13作为后面分桶表的数据源:
- 表名t13,只有四个字段:
create external table t13 (name string, age int, province string, city string)
row format delimited
fields terminated by ','
location '/data/external_t13';
- 创建名为013.txt的文件,内容如下:
tom,11,guangdong,guangzhou
jerry,12,guangdong,shenzhen
tony,13,shanxi,xian
john,14,shanxi,hanzhong
- 将013.txt中的四条记录载入t13:
load data
local inpath '/home/hadoop/temp/202010/25/013.txt'
into table t13;
分桶
- 创建表t14,指定字段分桶,桶数量为16:
create table t14 (name string, age int, province string, city string)
clustered by (province, city) into 16 buckets
row format delimited
fields terminated by ',';
- 从t13导入数据,注意语法是from t13开始,要用overwrite关键字:
from t13
insert overwrite table t14
select name, age, province, city;
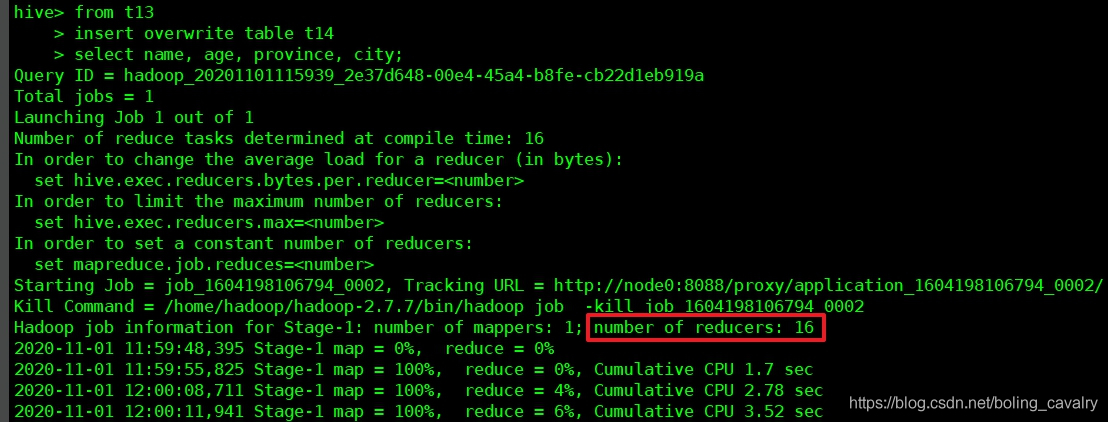
- 导入过程如下图所示,可见reducer数量已被自动调整为桶数量:
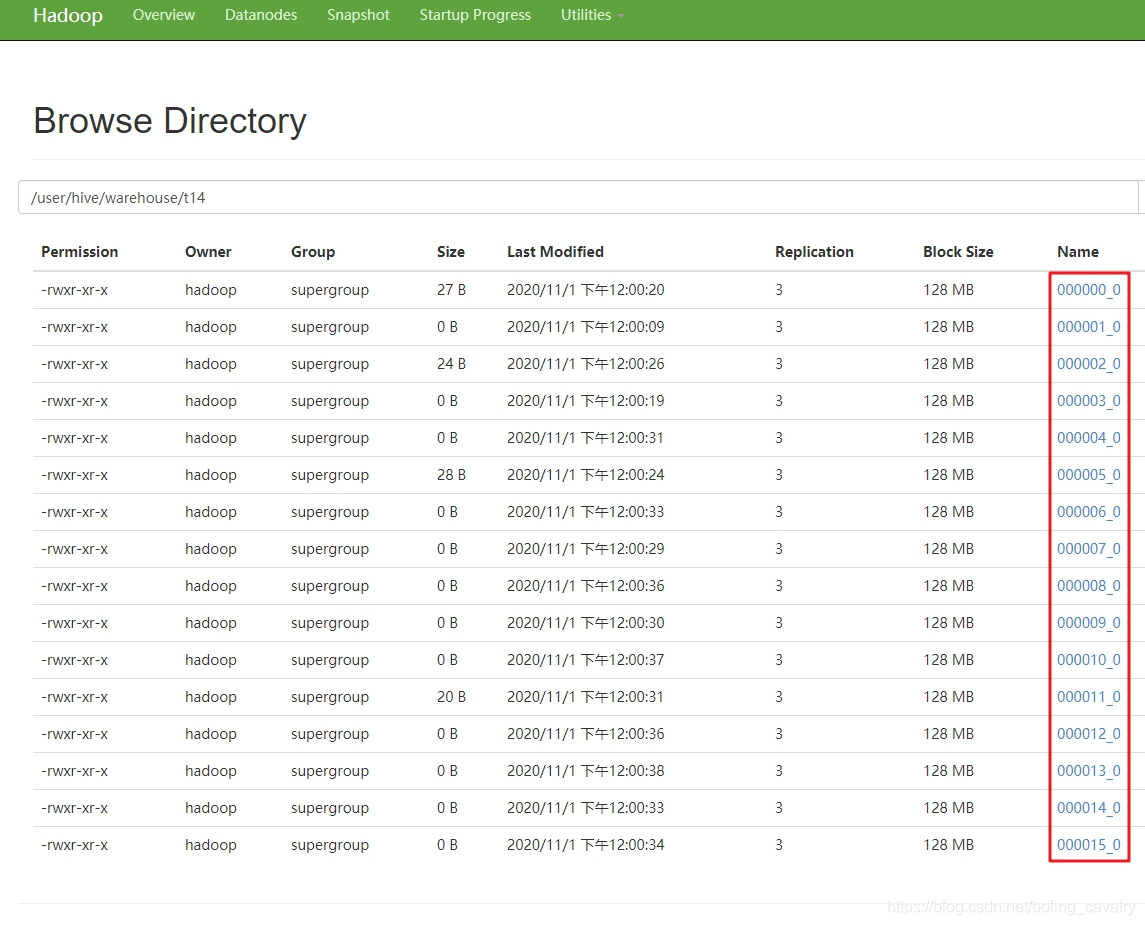
- 导入后,查看hdfs,可见被分为16个文件,(和分区对比一下,分区是不同的文件夹):
取样
执行以下语句,取样查看t14的数据:
hive> select * from t14 tablesample(bucket 1 out of 2 on province, city);
OK
tom 11 guangdong guangzhou
john 14 shanxi hanzhong
Time taken: 0.114 seconds, Fetched: 2 row(s)
- 至此,分桶操作就完成了,基础知识的实践已经完成,接下来开始一些进阶实践;
你不孤单,欣宸原创一路相伴
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
hive学习笔记之五:分桶的更多相关文章
- hive学习笔记之一:基本数据类型
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之三:内部表和外部表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之四:分区表
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之六:HiveQL基础
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之七:内置函数
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- hive学习笔记之九:基础UDF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Hive动态分区和分桶(八)
Hive动态分区和分桶 1.Hive动态分区 1.hive的动态分区介绍 hive的静态分区需要用户在插入数据的时候必须手动指定hive的分区字段值,但是这样的话会导致用户的操作复杂度提高,而且在 ...
- hive学习笔记之十:用户自定义聚合函数(UDAF)
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是<hive学习笔记>的第十 ...
- hive学习笔记之十一:UDTF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- 使用Optional处理null
一.聊聊NullPointerException 相比做Java开发的,见到NullPointerException肯定不陌生吧,可以说见到它深恶痛绝.在开发时认为不会出现NullPointerE ...
- 关于flask的模板注入的学习
flask模板注入的学习 关于flask模版注入,之前不太理解,看了很多文章才弄懂,主要原理就是渲染函数的参数用户可控就造成了模板注入 就会使用户构造恶意的代码进行逃逸从而进行攻击 flask模板渲染 ...
- 把el-element的日期格式改为CRON
在日常的开发当中,经常会遇到格式的不匹配造成的困扰. 在日期管理上,el-element也是贴心的准备了相关的日期选择器,但是在取值的时候发现,el-element所给出的值格式可能并不是我们常用的. ...
- Ubuntu 18.04 进入单用户模式修改密码
Ubuntu 18.04 使用单用户模式修改密码 操作步骤 启动Ubuntu 18.04 ,长按 Shift 键(有的可能按 Esc 键:绝大多数按 Shift 键)进入单用户视图,选中 Ubuntu ...
- 【转载】CentOS 7 系统区域(语言)和键盘设置
CentOS 7 系统区域(语言)和键盘设置 即使是在window中,平常说的语言设置这一项也是归类为系统区域,CentOS可以通过修改/etc/locale.conf配置文件或使用localec ...
- IT菜鸟之计算机硬件
现在的人们几乎无时无刻都会碰到计算机!不管是桌面计算机.笔记本电脑.平板计算机.智能型手机等等,这些东西都算计算机.虽然接触的怎么多,但是,我们一般很少会专门了解计算机内部的构成,下面就是自己在听课结 ...
- docker存储驱动
http://www.sohu.com/a/101016494_116235 https://success.docker.com/article/compatibility-matrix Red H ...
- Linux 系统日志和系统信息常用命令介绍
日志文件 日 志 文 件 说 明 /var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一 /var/log/secure 与安全相关的日志信息 / ...
- unity项目字符串转为Vector3和Quaternion
运用环境:一般在读取csv表格的数据时是string类型转为Vector3或者Quaternion类型 字符串格式:x,x,x /x,x,x,x (英文逗号) 方法: /// <summary& ...
- 重新整理 .net core 实践篇————配置系统——军令(命令行)[六]
前言 前文已经基本写了一下配置文件系统的一些基本原理.本文介绍一下命令行导入配置系统. 正文 要使用的话,引入Microsoft.extensions.Configuration.commandLin ...