《爬虫学习》(四)(使用lxml,bs4库以及正则表达式解析数据)
1.XPath:
XPath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。
工具:扩展商店里搜索:XPath Helper(我是QQ浏览器)

XPath的语法:

使用举例:

2. lxml库:
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据
下载:pip install lxml
基本使用:在lxml中使用xpath语法

3.bs4库的使用:
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM(Document Object Model)的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。
安装:pip install bs4
bs4的简单使用:
from bs4 import BeautifulSoup html = """ 一段HTML代码 """ #创建 Beautiful Soup 对象
# 使用lxml来进行解析
soup = BeautifulSoup(html,"lxml") print(soup.prettify())
举例使用:
# bs4库的使用
# from bs4 import BeautifulSoup
# html = 'xxxx'
# bs4底层由lxml实现
# bs = BeautifulSoup(html, 'lxml')
# .获取所有span标签
# spans = bs.find_all('span')
# for span in spans:
# print(span)
# .获取前二个span标签(limit=)中的第二个span标签([]) 下标:从0开始
# span = bs.find_all('span', limit=)[]
# print(span)
# .获取所有dl中class等于bottom的标签
# dls = bs.find_all('dl', class_='bottom')
# for dl in dls:
# print(dl)
# 或者使用attrs标签(attrs=一个字典)
# dls = bs.find_all('dl', attrs={'class':'bottom'})
# for dl in dls:
# print(dl)
# .获取所有a标签的href属性
# aList = bs.find_all('a')
# for a in aList:
# # .使用下标方法(推荐)
# href = a['href']
# # .使用attrs方式
# href2 = a.attrs['href']
# print(href2)
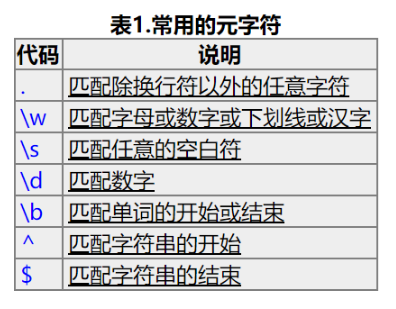
4.还有一种方法解析数据:正则表达式
以下内容从别人博客转载,方便复习



《爬虫学习》(四)(使用lxml,bs4库以及正则表达式解析数据)的更多相关文章
- 爬虫(四):BeautifulSoup库的使用
一:beautifulsoup简介 beautifulsoup是一个非常强大的工具,爬虫利器. beautifulSoup “美味的汤,绿色的浓汤” 一个灵活又方便的网页解析库,处理高效,支持多种解析 ...
- 爬虫学习(十一)——bs4基础学习
ba4的介绍: bs4是第三方提供的库,可以将网页生成一个对象,这个网页对象有一些函数和属性,可以快捷的获取网页中的内容和标签 lxml的介绍 lxml是一个文件的解释器,python自带的解释器是: ...
- Python爬虫学习==>第八章:Requests库详解
学习目的: request库比urllib库使用更加简洁,且更方便. 正式步骤 Step1:什么是requests requests是用Python语言编写,基于urllib,采用Apache2 Li ...
- python之爬虫(四)之 Requests库的基本使用
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- (转)Python爬虫学习笔记(2):Python正则表达式指南
以下内容转自CNBLOG:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html 1. 正则表达式基础 1.1. 简单介绍 正则表达式并 ...
- 一只简单的网络爬虫(基于linux C/C++)————利用正则表达式解析页面
我们向一个HTTP的服务器发送HTTP的请求后,服务器会返回可能一个HTML页面(当然也可以是其他的资源),我们可以利用返回的HTML页面,在其中寻找其他的Url,例如我们可以这样在浏览器上查看一下H ...
- 一起来开发Android的天气软件(四)——使用Gson解析数据
离上一篇文章过去才4.5天,我们赶紧趁热打铁继续完毕该系列的天气软件的开发. 承接上一章的内容使用Volley实现网络的通信.返回给我们的是这一串Json数据{"weatherinfo&qu ...
- python网络爬虫学习笔记(二)BeautifulSoup库
Beautiful Soup库也称为beautiful4库.bs4库,它可用于解析HTML/XML,并将所有文件.字符串转换为'utf-8'编码.HTML/XML文档是与“标签树一一对应的.具体地说, ...
随机推荐
- 前端导出&配置问题
<button class="search" onclick="method5('dataTable');">导出</button> 在 ...
- 2019-3-8-为何使用-DirectComposition
title author date CreateTime categories 为何使用 DirectComposition lindexi 2019-3-8 8:56:9 +0800 2018-04 ...
- HDU 6623 Minimal Power of Prime(数学)
传送门 •题意 给你一个大于 1 的正整数 n: 它可以分解成不同的质因子的幂的乘积的形式,问这些质因子的幂中,最小的幂是多少. •题解 把[1,10000]内的素数筛出来,然后对于每个素$P$数遍历 ...
- NuGet 如何设置图标
在找 NuGet 的时候可以看到有趣的库都有有趣的图标,那么如何设置一个 NuGet 的图标 在开始之前,请在nuget官方网站下载 NuGet.exe 同时设置环境变量 环境变量设置的方法就是将 N ...
- UVA live 6667 三维严格LIS
UVA live 6667 三维严格LIS 传送门:https://vjudge.net/problem/UVALive-6667 题意: 每个球都有三个属性值x,y,z,要求最长的严格lis的长度和 ...
- BZOJ 3166
BZOJ3196: Tyvj 1730 二逼平衡树 传送门:https://www.lydsy.com/JudgeOnline/problem.php?id=3196 题意: 1.查询k在区间内的排名 ...
- Math类入门学习
Math类 Math类包含用于执行基本的数字运算等基本指数.对数.平方根法.三角函数. import java.lang.*; public class TestMath { public stati ...
- 第二阶段:4.商业需求文档MRD:3.PRD-页面结构图
这也是功能结构以及优先级 这是页面层级 页面结构图 再细分某一个频道或者子页面 层层细分 用mind做的页面结构图 里面也包含了功能
- 使用Gson中的JsonElement所遇到的坑
使用Gson中的JsonElement所遇到的坑 原文链接: https://blog.csdn.net/weixin_30326515/article/details/98196013 声明:此博客 ...
- Callable,阻塞队列,线程池问题
一.说说Java创建多线程的方法 1. 通过继承Thread类实现run方法 2. 通过实现Runnable接口 3. 通过实现Callable接口 4. 通过线程池获取 二. 可以写一个Call ...