python+requests爬取百度文库ppt
实验网站:https://wenku.baidu.com/view/c7752014f18583d04964594d.html
在下面这种类型文件中的请求头的url打开后会得到一个页面
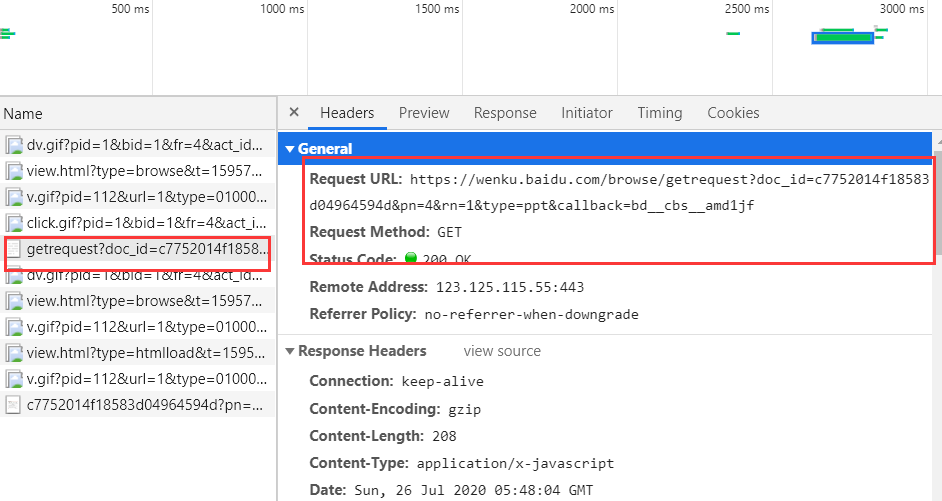
你会得到如下图一样的页面

你将页面上zoom对应的值在一个新的网页打开之后会发现,这个就是ppt中的图片
你可以多打开几个“getrequest?doc_id”类型的请求头看一下它们的Request URL,你会发现我们只需要改变pn对应的数字就能得到文库中对应的PPT图片

知道了这个我们就可以先把图片url弄出来,然后再依次访问这些url,并下载至本地
要注意的是,如下面的url地址
https:\/\/wkretype.bdimg.com\/retype\/zoom\/c7752014f18583d04964594d?pn=4&raww=1080&rawh=810&o=jpg_6&md5sum=046b21875cb4e60170f5521eea9253dc&sign=22044930c7&png=102985-135328&jpg=219095-369954
你如果复制之后粘贴在浏览器的地址框里面,浏览器会把这个地址转化成下面这个类型之后再去访问
https://wkretype.bdimg.com//retype//zoom//c7752014f18583d04964594d?pn=4&raww=1080&rawh=810&o=jpg_6&md5sum=046b21875cb4e60170f5521eea9253dc&sign=22044930c7&png=102985-135328&jpg=219095-369954
所以在我们得到地址之后用一些函数处理一下就可以了
因为代码不太复杂,所以就不再详细叙述了
import requests class Spider:
def __init__(self):
#定义url前缀
self.url_pre = "https://wenku.baidu.com/browse/getrequest?doc_id=c7752014f18583d04964594d&pn="
#定义url后缀
self.url_suf = "&rn=1&type=ppt&callback=bd__cbs__sv0n59"
#请求头
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
} def Create_url(self):
num = input('输入爬取ppt总页数:')
for i in range(1,int(num)+1):
#构建对应页数PPT的url地址
self.url = self.url_pre+str(i)+self.url_suf
#请求后得到页面源码
response = requests.get(self.url,headers=self.headers)
html = response.text
#因为我们需要从页面源码中拿到PPT中图片对应地址,所以可以通过字符串匹配等方式得到,这里我就用数组查找就行
#找出图片地址在源码中起始和终止位置
start = html.find(':"http') + 2
end = html.find('","')
#切割字符串
url_pic = html[start:end]
#将图片url字符串,转化为可访问的url地址
url_pic=url_pic.replace('\\','')
#print(url_pic)
self.request_pic(url_pic,i) def request_pic(self,url_pic,num):
#print(url_pic)
response = requests.get(url_pic, headers=self.headers)
num = str(num)+'.png'
with open(num,'wb') as f:
f.write(response.content) if __name__ == '__main__':
spider = Spider()
spider.Create_url()
python+requests爬取百度文库ppt的更多相关文章
- python+selenium爬取百度文库不能下载的word文档
有些时候我们需要用到百度文库的某些文章时,却发现需要会员才能下载,很难受,其实我们可以通过爬虫的方式来获取到我们所需要的文本. 工具:python3.7+selenium+任意一款编辑器 前期准备:可 ...
- python+selenium+bs4爬取百度文库内文字 && selenium 元素可以定位到,但是无法点击问题 && pycharm多行缩进、左移
先说一下可能用到的一些python知识 一.python中使用的是unicode编码, 而日常文本使用各类编码如:gbk utf-8 等等所以使用python进行文字读写操作时候经常会出现各种错误, ...
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- requests爬取百度音乐
使用requests爬取百度音乐,我想把当前热门歌手的音乐信息爬下来. 首先进行url分析,可以看到: 歌手网页: 薛之谦网页: 可以看到,似乎这些路劲的获取一切都很顺利,然后可以写代码: # -*- ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
随机推荐
- SQL中的主键,候选键,外键,主码,外码
1.码=超键:能够唯一标识一条记录的属性或属性集. 标识性:一个数据表的所有记录都具有不同的超键 非空性:不能为空 有些时候也把码称作"键" 2.候选键=候选码:能够唯一标识一条记 ...
- Kaggle泰坦尼克-Python(建模完整流程,小白学习用)
参考Kernels里面评论较高的一篇文章,整理作者解决整个问题的过程,梳理该篇是用以了解到整个完整的建模过程,如何思考问题,处理问题,过程中又为何下那样或者这样的结论等! 最后得分并不是特别高,只是到 ...
- zabbix 监控的数据
/usr/local/zabbix/bin/zabbix_sender --zabbix-server 192.168.1.10 --port 10051 --input-file /var/log/ ...
- 【Oracle】substr()函数详解
Oracle的substr函数简单用法 substr(字符串,截取开始位置,截取长度) //返回截取的字 substr('Hello World',0,1) //返回结果为 'H' *从字符串第一个 ...
- allator 对springBoot进行加密
1.对springboot项目添加jar包和xml文件 allatori.xml: <config> <input> <jar in="target/sprin ...
- innodb引擎的4大特性
一:插入缓冲 二:二次写 三:自适应哈希 四:预读 1.插入缓冲(insert buffer)插入缓冲(Insert Buffer/Change Buffer):提升插入性能,change buffe ...
- 对象存储 COS 帮您轻松搞定跨域访问需求
背景 早期为了避免 CSRF(跨站请求伪造) 攻击,浏览器引入了 "同源策略" 机制.如果两个 URL 的协议,主机名(域名/IP),端口号一致,则视为这两个 URL " ...
- 分布式事务 Seata Saga 模式首秀以及三种模式详解 | Meetup#3 回顾
https://mp.weixin.qq.com/s/67NvEVljnU-0-6rb7MWpGw 分布式事务 Seata Saga 模式首秀以及三种模式详解 | Meetup#3 回顾 原创 蚂蚁金 ...
- Lucene 查询原理 传统二级索引方案 倒排链合并 倒排索引 跳表 位图
提问: 1.倒排索引与传统数据库的索引相比优势? 2.在lucene中如果想做范围查找,根据上面的FST模型可以看出来,需要遍历FST找到包含这个range的一个点然后进入对应的倒排链,然后进行求并集 ...
- Go is more about software engineering than programming language research.
https://talks.golang.org/2012/splash.article Go at Google: Language Design in the Service of Softwar ...