KafKa简介和利用docker配置kafka集群及开发环境
KafKa的基本认识,写的很好的一篇博客:https://www.cnblogs.com/sujing/p/10960832.html
问题:
1、kafka是什么?
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能、持久化、多副本备份、横向扩展能力。
2、kafka的工作原理[去耦合]
Kafka采用的是订阅-发布的模式,消费者主动的去kafka集群拉取消息,与producer相同的是,消费者在拉取消息的时候也是找leader去拉取。
3、kafka存在的意义:去耦合、异步、中间件的消息系统。
- kafka节点之间如何复制备份的?
- kafka消息是否会丢失?为什么?[ACK机制]
- kafka最合理的配置是什么?
- kafka的leader选举机制是什么?
- kafka对硬件的配置有什么要求?
- kafka的消息保证有几种方式?
- kafka为什么会丢消息?
1 Kafka简介
Kafka:是一个高吞吐量、分布式的发布-订阅消息系统。kafka是一款开源的、轻量级的、分布式、可分区和具有复制备份[Replicated]的、基于Zookeeper协调管理的分布式流平台的功能强大的消息系统。
1.1 Kafka特性
- 能够允许发布和订阅流数据
- 存储流数据时提供相应的容错机制
- 当流数据到达时能够被及时处理[近乎实时性的消息处理能力,可以高效地存储消息和查询消息]
1.2 Kafka消息系统最基本的体系结构[kafka的工作模式]
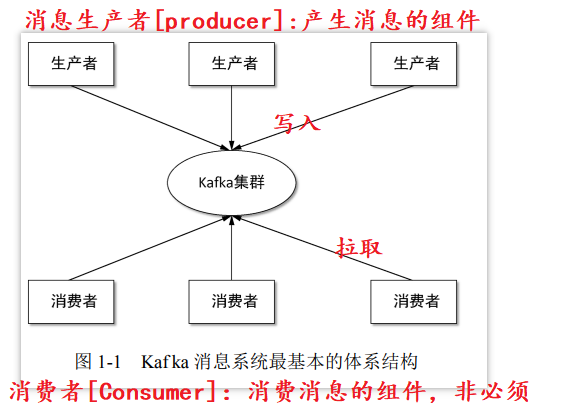
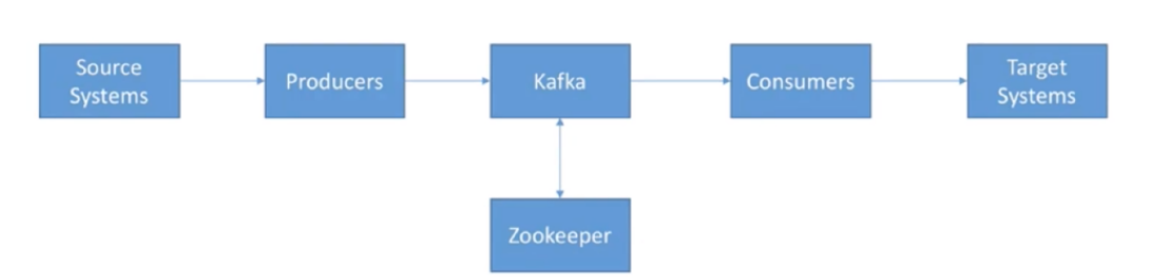
1.3 Kafka生态系统
Kafka Core API:
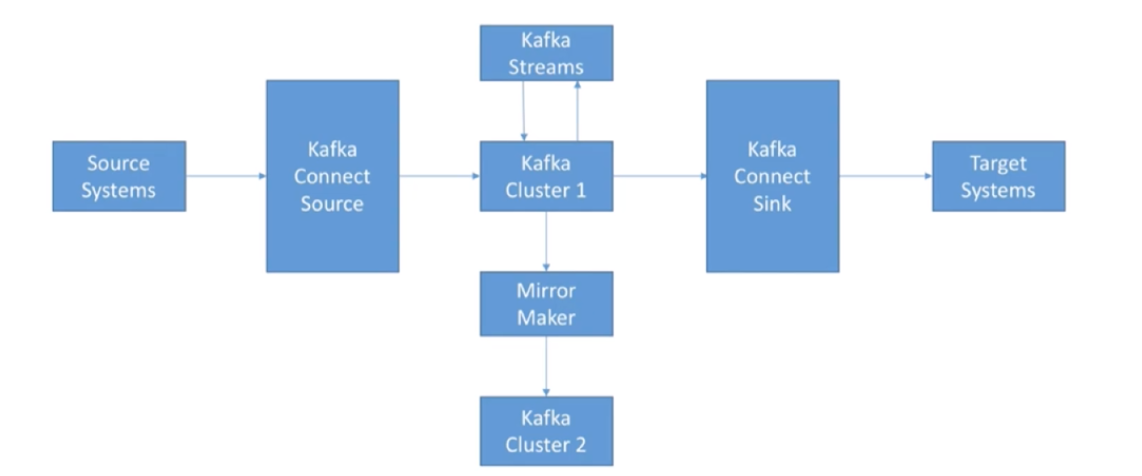
Kafka Extended API:
1.4 Kafka基本概念[核心概念]
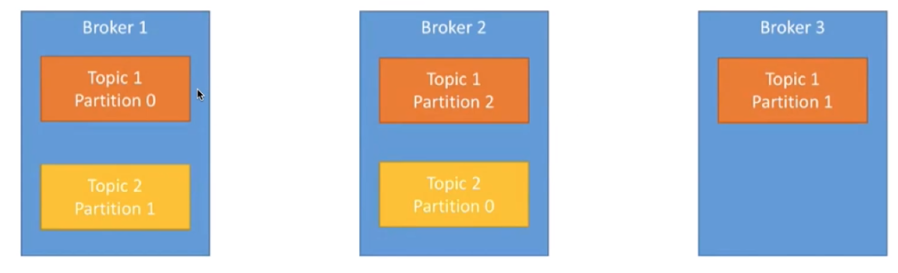
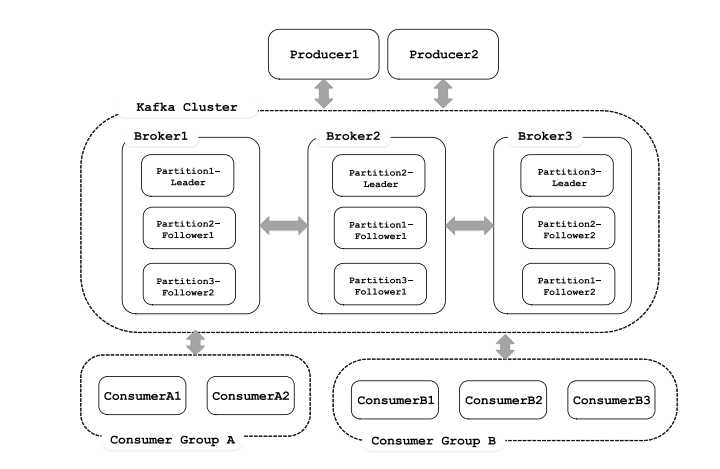
- Topic& 分区 &Log:Topic 是用于存储消息的逻辑概念,可以看作一个消息集合。每个 Topic 可以有多个生产者向其中推送(push)消息,也可以有任意多个消费者消费其中的消息。每个分区[对应一个磁盘的文件夹]由一系列有序、不可变的消息组成,是一个有序队列。Log 由多个 Segment 组成,每个 Segment 对应一个日志文件和索引文件。每个分区在物理上对应为一个文件夹,分区的命名规则为主题名称后接“—”连接符,之 后再接分区编号,分区编号从 0 开始,编号最大值为分区的总数减 1。日志段:一个日志又被划分为多个日志段(LogSegment)[逻辑概念],日志段是 Kafka 日志对象分片的最小单位。一个日志段对应磁盘上一个具体日志文件和 两个索引文件。日志文件是以“.log”为文件名后缀的数据文件,用于保存消息实际数据。两个索引文件分别以“.index”和“.timeindex”作为文件名后缀,分别表示消息偏移量索引文件和消息时间戳索引文件。
Topic与Partition之间的关系:

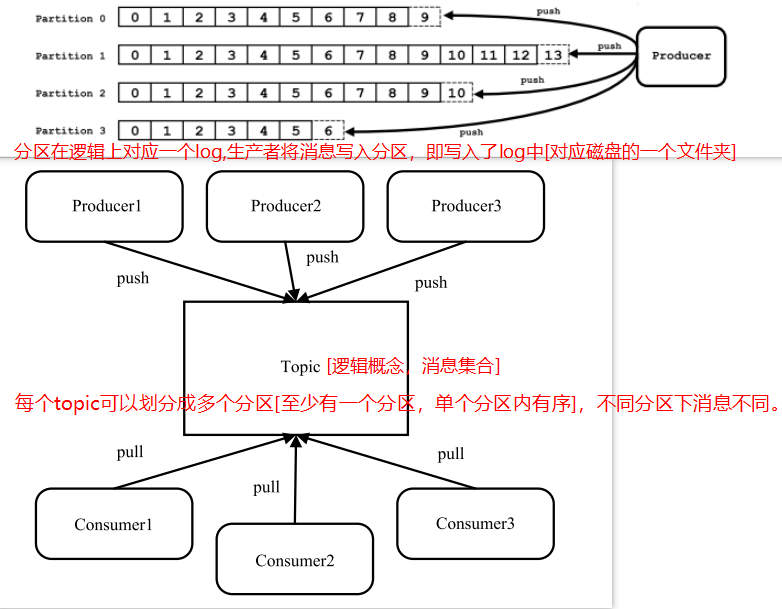
- 消息:Kafka通信的基本单位,消息由一串字节构成,其中主要由 key 和 value 构成,key 和 value 也都是 byte 数组。key的主要作用是根据一定的策略,将此消息路由到指定的分区中,这样就可以保证包含同一 key 的消息全部写入同一分区中,key 可以是 null。消息的真正有效负载是 value 部分的数据。
- 副本:每个 Partition 可以有多个副本,每个副本中包含的消息是一样的。每个分区至少有一个副本,当分区中只有一个副本时,就只有 Leader 副本,没有 Follower 副本。所有的读写请求都由选举出 的 Leader 副本处理,其他都作为 Follower 副本,Follower 副本仅仅是从 Leader 副本处把数据拉取到本地之后,同步更新到自己的 Log 中。Kafka 提供两种删除老数据的策略, 一是基于消息已存储的时间长度,二是基于分区的大小。
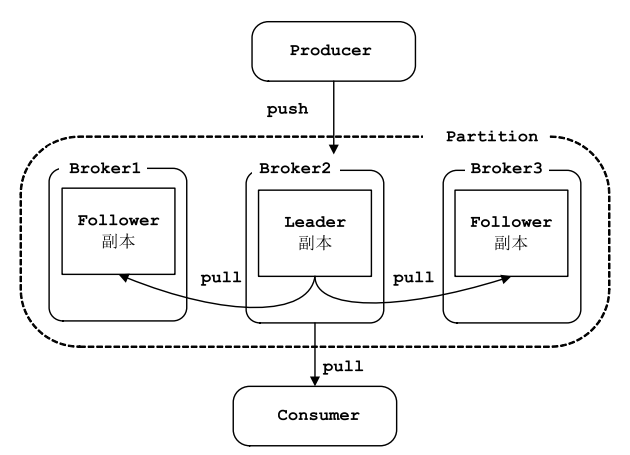
- 偏移量:任何发布到分区的消息会被直接追加到日志文件(分区目录下以“.log”为文件名后缀的 数据文件)的尾部,而每条消息在日志文件中的位置都会对应一个按序递增的偏移量。
- 代理:每一个Kafka实例称为代理(Broker),也称为kafka服务器。Kafka集群一般包含一台或多台服务器,可以在一台服务器上配置一个或多个代理。
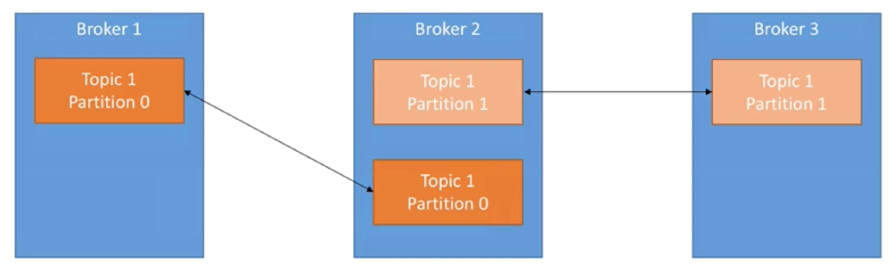
代理和主题之间的关系:
- 生产者:将消息发给代理,也就是向Kafka代理发送消息的客户端。例如:生产者将数据发送到主题。[key-value的形式写入]
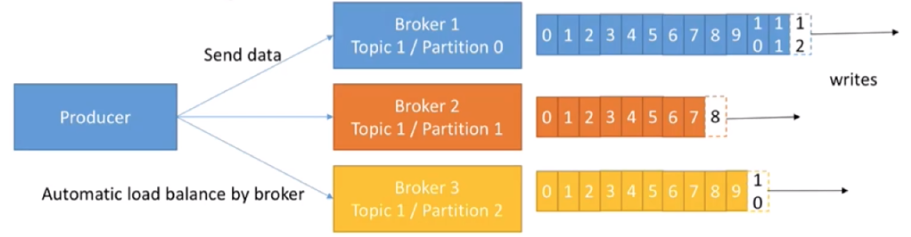
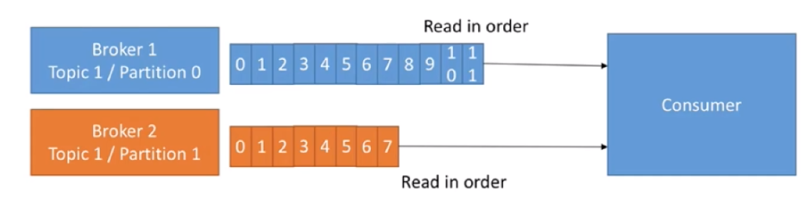
- 消费者和消费组:消费者(Comsumer)以拉取 (pull)方式拉取数据,它是消费的客户端。在 Kafka 中每一 个消费者都属于一个特定消费组(ConsumerGroup),我们可以为每个消费者指定一个消费组, 以 groupId 代表消费组名称,通过 group.id 配置设置。
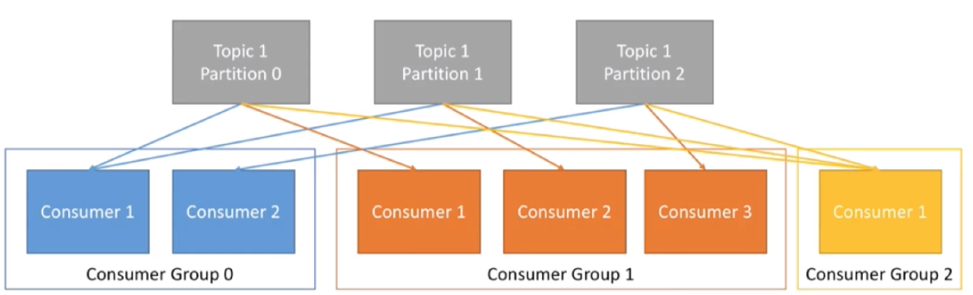
Consumer group 和topic的联动方式:比如这里的topic1有3个分区,Consumer Group 0中有2个Consumer,Consumer 1 拉取分区0和分区1的数据,Consumer 2拉取分区2的数据。
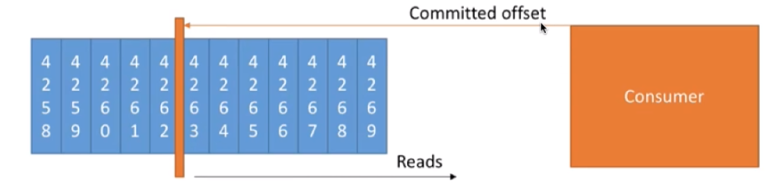
- ISR:Kafka 在 ZooKeeper 中动态维护了一个 ISR(In-sync Replica),即保存同步的副本列表,该列表中保存的是与 Leader 副本保持消息同步的所有副本对应的代理节点id。ISR(In-Sync Replica)集合表示的是目前“可用”(alive)且消息量与 Leader 相差不多的副本集合,这是整个副本集合的一 个子集。
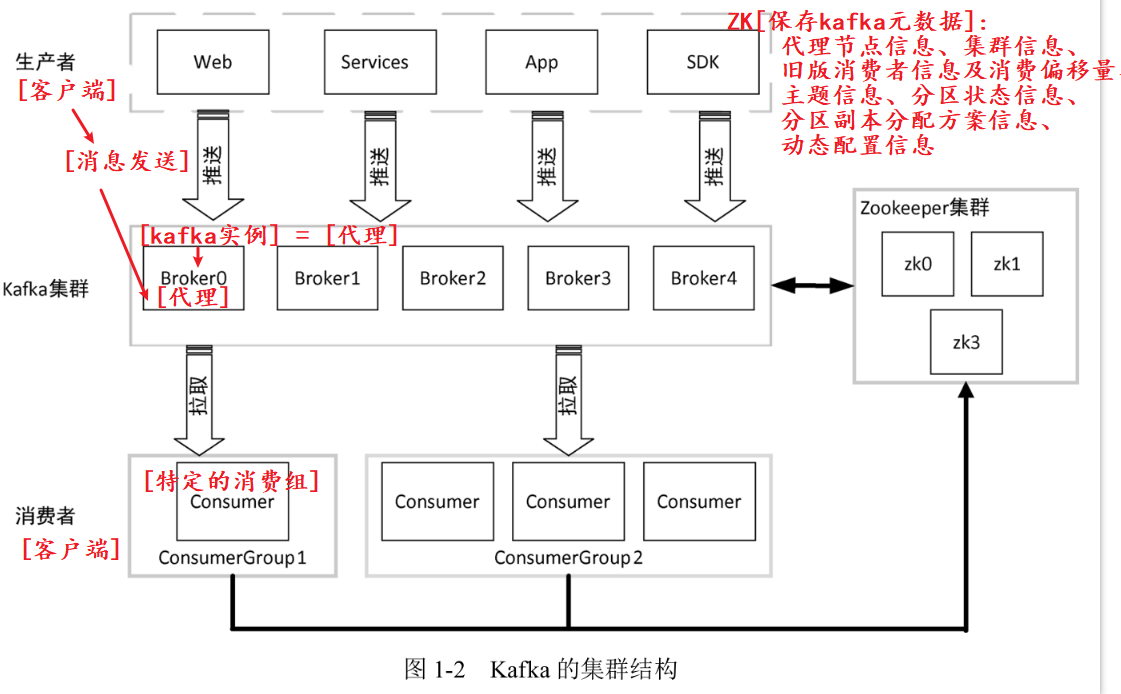
- ZooKeeper[选举算法]:Kafka 利用 ZooKeeper 保存相应元数据信息,Kafka元数据信息包括如代理节点信息、Kafka 集群信息、旧版消费者信息及其消费偏移量信息、主题信息、分区状态信息、分区副本分配方 案信息、动态配置信息等。
1.5 Kafka集群架构
根据业务逻辑产生消息,在根据路由规则将消息发送到指定分区的Leader副本所在的Broker上。
1.6 Kafka设计概述
- 动机:统一、实时处理大规模数据的平台。[类似数据库日志系统]
- (1)具有高吞吐量来支持诸如实时的日志集这样的大规模事件流。
- (2)能够很好地处理大量积压的数据,以便能够周期性地加载离线数据进行处理。
- (3)能够低延迟地处理传统消息应用场景。
- (4)能够支持分区、分布式,实时地处理消息,同时具有容错保障机制。
- 特性:消息持久化、高吞吐量、扩展性、多客户端支持、Kafka Streams、安全机制、数据备份、轻量级、消息压缩。
- (1)消息持久化:Kafka 高度依赖于文件系统来存储和缓存消息。
- (2)高吞吐量:Kafka 将数据写到磁盘,充分利用磁盘的顺序读写。 同时,Kafka 在数据写入及数据同步采用了零拷贝(zero-copy)技术,完全在内核中操作,从而避免了内核缓冲区与用户缓冲区之间数据的拷贝,操作效率极高。Kafka 还支持数据压缩及批量发送,同时 Kafka 将每个主题划分为多个分区。
- (3)扩展性:集群能够自动感知,重新进行负责均衡及数据复制。
- 应用场景:
- (1)消息系统。[在应用系统中可以将kafka作为传统的消息中间件,实现消息队列和消息的发布/订阅]
- (2)应用监控。
- (3)网站用户行为追踪。[用作日志收集中心,多个系统产生的日志统一收集到Kafka中,然后由数据分析平台进行统一处理]
- (4)流处理。
- (5)持久性日志。[Kafka 可以为外部系统提供一种持久性日志的分布式系统。日志可以在多个节点间进行备份,Kafka为故障节点数据恢复提供了一种重新同步的机制。]
- (6)kafka用作系统中的数据总线,将其接入多个子系统中,子系统会将产生的数据发送到kafka中保存,之后流转到目的系统中。
2 配置Kafka集群及开发环境
- 在linux中安装并配置docker并启动kafka开发环境
- 在kafka环境中对topic进行create、delete、list、descr
- 在kafka环境命令行中producer向topic中推送数据
- 在kafka环境命令行中consumer向topic中拉取数据
2.1 在linux中安装并配置docker并启动kafka开发环境
- 1、ubuntu docker安装[使用官方安装脚本自动安装]:https://www.runoob.com/docker/ubuntu-docker-install.html
- 2、如何使用docker在本地建立一个kafka的开发环境:在github官网(https://github.com)中搜索lensesio/fast-data-dev
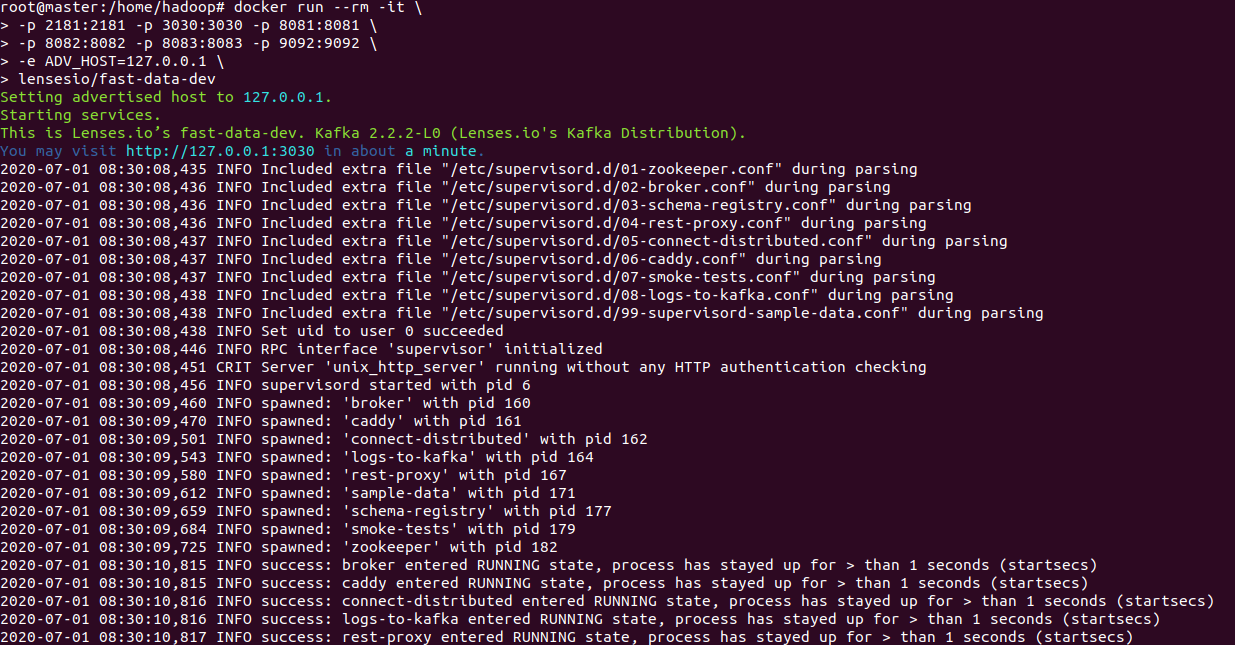
- 3、在浏览器中打开网址:http://localhost:3030/,看到如下界面,表示kafka开发环境启动成功。
#安装curl,目的是使用官网安装docker[linux安装时提示没有该命令,按需安装]
apt install curl #在linux[查看版本使用命令:uname -r]下安装docker
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun #启动kafka开发环境
docker run --rm -it \
-p 2181:2181 -p 3030:3030 -p 8081:8081 \
-p 8082:8082 -p 8083:8083 -p 9092:9092 \
-e ADV_HOST=127.0.0.1 \
lensesio/fast-data-dev
前提是docker已安装成功:
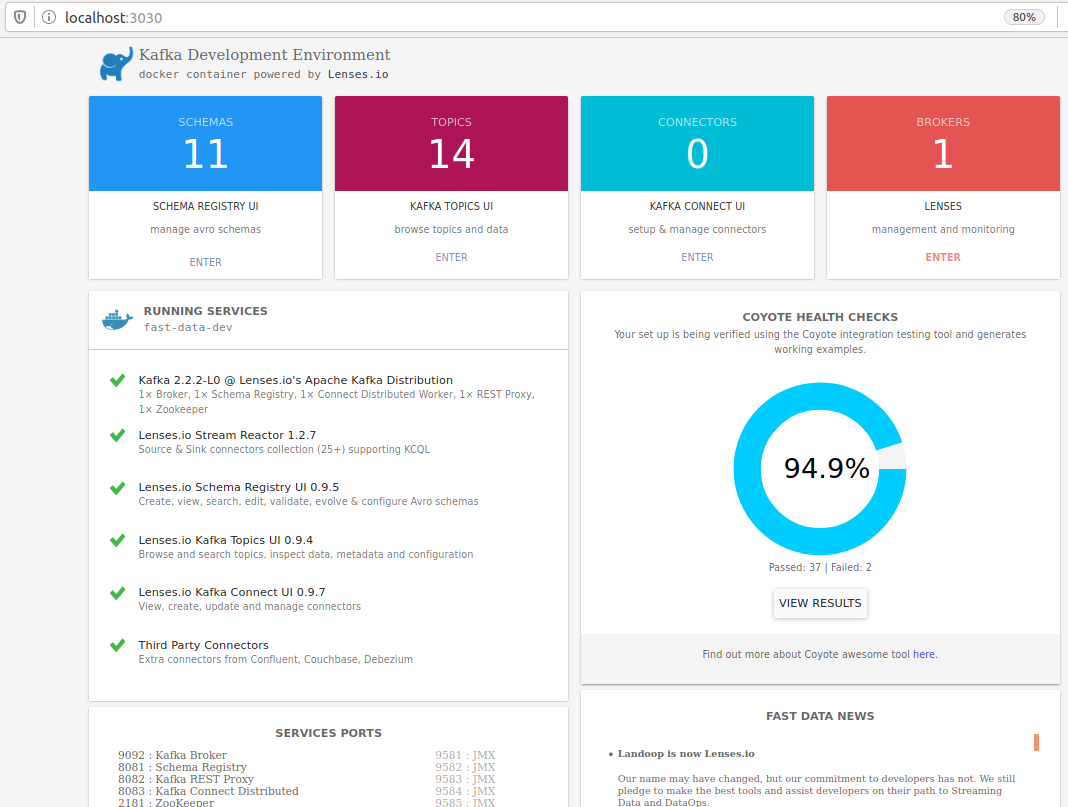
2.2 在kafka环境中对topic进行create、delete、list、descr
#登录到kafka,进行kafca操作
docker run --rm -it --net=host lensesio/fast-data-dev bash #topic对应的参数名称显示
kafka-topics #创建first-topic
kafka-topics --zookeeper 127.0.0.1:2181 --create --topic first_topic --partitions 3 --replication-factor 1 kafka-topics --zookeeper 127.0.0.1:2181 --create --topic second_topic --partitions 3 --replication-factor 1 #列表显示对应的topic
kafka-topics --zookeeper 127.0.0.1:2181 --list #删除topic
kafka-topics --zookeeper 127.0.0.1:2181 --delete --topic first_topic #查看存在的topic
kafka-topics --zookeeper 127.0.0.1:2181 --describe --topic second_topic
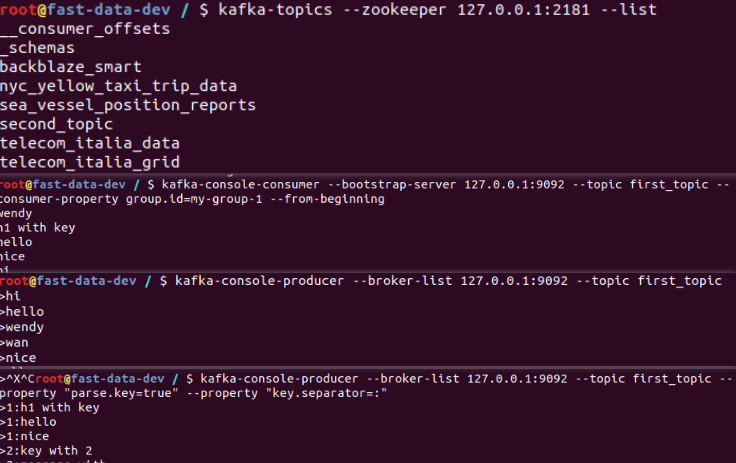
2.3 在kafka环境命令行中producer向topic中推送数据
#登录到kafka,进行kafca操作
docker run --rm -it --net=host lensesio/fast-data-dev bash #用console producer向topic中推送数据
#producer对应的参数名称显示
kafka-console-producer #推送数据hi、hello、today、nice、kafka
[未指定key,value随机指派给分区]
kafka-console-producer --broker-list 127.0.0.1:9092 --topic first_topic
>hi
>hello
[指定key,value指派给对应的分区]
kafka-console-producer --broker-list 127.0.0.1:9092 --topic first_topic --property "parse.key=true" \
--property "key.separator=:"
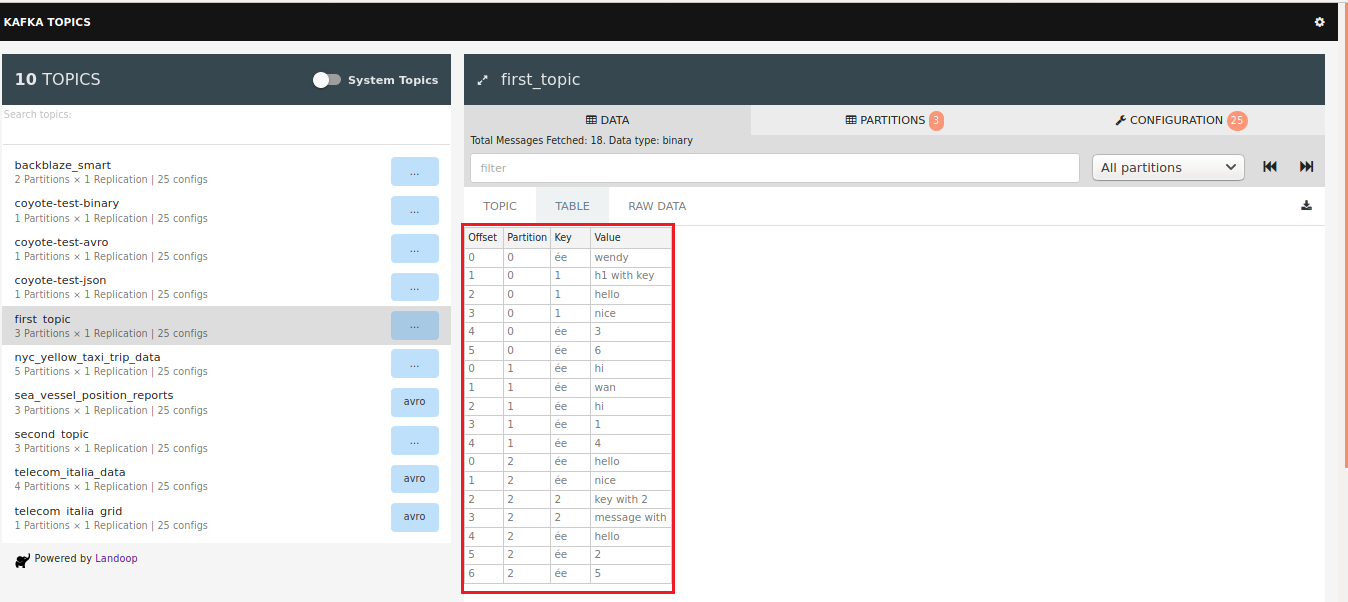
2.4 在kafka环境命令行中consumer向topic中拉取数据
#登录到kafka,进行kafca操作
docker run --rm -it --net=host lensesio/fast-data-dev bash #用console consumer向topic中拉取数据,下列命令可以列出所有需要使用的参数
kafka-console-consumer #创建consumer,从当前位置开始读取
kafka-console-consumer --bootstrap-server 127.0.0.1:9092 --topic first_topic #创建consumer,从起始位置开始读取,my-group-1中的一员
kafka-console-consumer --bootstrap-server 127.0.0.1:9092 --topic first_topic \
--consumer-property group.id=my-group-1 --from-beginning #创建consumer,从起始位置开始读取
kafka-console-consumer --bootstrap-server 127.0.0.1:9092 --topic first_topic --from-beginning
KafKa简介和利用docker配置kafka集群及开发环境的更多相关文章
- 使用docker配置etcd集群
docker配置etcd集群与直接部署etcd集群在配置上并没有什么太大差别. 我这里直接使用docker-compose来实现容器化的etcd部署 环境如下: HostName IP etcd1 1 ...
- 利用Redis实现集群或开发环境下SnowFlake自动配置机器号
前言: SnowFlake 雪花ID 算法是推特公司推出的著名分布式ID生成算法.利用预先分配好的机器ID,工作区ID,机器时间可以生成全局唯一的随时间趋势递增的Long类型ID.长度在17-19位. ...
- ubuntu14.04环境下利用docker搭建solrCloud集群
在Ubuntu14.04操作系统的宿主机中,安装docker17.06.3,将宿主机的操作系统制作成docker基础镜像,之后使用自制的基础镜像在docker中启动3个容器,分配固定IP,再在3个容器 ...
- 利用Docker搭建Redis集群
Redis集群搭建 运行Redis镜像 分别使用以下命令启动3个Redis docker run --name redis-6379 -p 6379:6379 -d hub.c.163.com/lib ...
- 利用docker部署redis集群
目录 一.首先配置redis.conf文件,... 1 1.获取配置文件... 1 2.修改各配置文件的参数... 2 二.下载redis镜像.启动容器... 2 1.创建网络... 2 2.拉取镜像 ...
- 利用 docker 部署 elasticsearch 集群(单节点多实例)
文章目录 1.环境介绍 2.拉取 `elasticserach` 镜像 3.创建 `elasticsearch` 数据目录 4.创建 `elasticsearch` 配置文件 5.配置JVM线程数量限 ...
- Hadoop HA集群 与 开发环境部署
每一次 Hadoop 生态的更新都是如此令人激动 像是 hadoop3x 精简了内核,spark3 在调用 R 语言的 UDF 方面,速度提升了 40 倍 所以该文章肯定得配备上最新的生态 hadoo ...
- Hadoop集群 -Eclipse开发环境设置
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- 在 Ubuntu 上搭建 Hadoop 分布式集群 Eclipse 开发环境
一直在忙Android FrameWork,终于闲了一点,利用空余时间研究了一下Hadoop,并且在自己和同事的电脑上搭建了分布式集群,现在更新一下blog,分享自己的成果. 一 .环境 1.操作系统 ...
随机推荐
- Qt基础之菜单栏
本篇介绍Qt菜单栏相关操作,分为三部分:1.菜单栏相关的类介绍:2.系统菜单的生成和响应:3.弹出菜单的生成和响应:菜单栏通常只有以QMainWindow为基类的程序中才用到,以QWidget为基类的 ...
- rabbitmq-参考
rabbitMQ http://lynnkong.iteye.com/blog/1699684 http://jzhihui.iteye.com/category/195005
- 写博客真的很枯燥,更麻烦的是我还不会MD,排版太不友好了啊。
学习MD 第一标题 #一号标题 ##二号标题 神马啊,博客园居然不支持MD语法
- TP5 RCE
Thinkphp5 RCE 复现 环境: win10+wamp+thinkphp5.1.29 下载地址 源码分析 程序首先跳转到 public目录下的index.php,然后执行 thinkphp/l ...
- gdb 符号表 &信息 &工具
查看二进制文件的编译器版本 strings info.o |grep GCCGCC: (crosstool-NG linaro-1.13.1-2012.02-20120222 - Linaro GC ...
- C语言环境总结
1.虚拟内存下C语言环境 2.main函数调用 3.栈调用 每次函数调用,在栈中分配一个栈帧,寄存器通过持有该栈帧的基地址,并上下偏移,访问形参和本地变量, C语言形参为一个字大小,所以通常传指针,这 ...
- 一:NOSQL
NOSQL =not only SQL 意即为不仅仅是SQL 传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的社交网络服务类型的web2.0纯动态网站已经显得力不从心,出现了很多难以克 ...
- Linux上Mysql数据库 用户权限控制
Linux安装mysql 点我直达 Mysql限制root用户ip地址登录 修改mysql库里边的user表: update mysql.user set host='localhost' where ...
- 通过phpmyadmin拿下webshell
废话: 1.听说网上卖手机的网站很多是诈骗的,搜到一个499元货到付款的手机网站.有点像诈骗,但倒觉得他是在收集用户信息 2.把网站扔到御剑,搜到phpmyadmin的后台,试试下账号密码居然都是默认 ...
- 来吧,展示!Redis的分布式锁及其实现Redisson的全过程
前言 分布式锁是控制分布式系统之间同步访问共享资源的一种方式. 在分布式系统中,常常需要协调他们的动作.如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要 ...