三 web爬虫,scrapy模块介绍与使用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
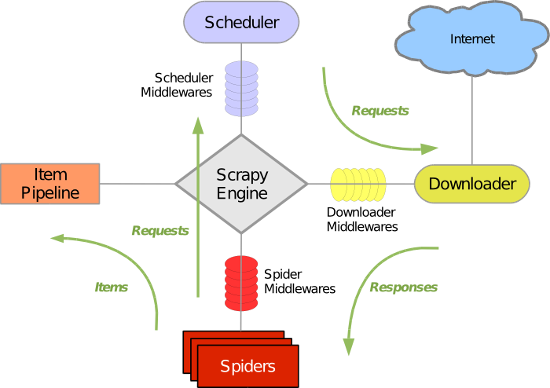
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
创建Scrapy框架项目
Scrapy框架项目是有python安装目录里的Scripts文件夹里scrapy.exe文件创建的,所以python安装目录下的Scripts文件夹要配置到系统环境变量里,才能运行命令生成项目
创建项目
首先运行cmd终端,然后cd 进入要创建项目的目录,如:cd H:\py\14
进入要创建项目的目录后执行命令 scrapy startproject 项目名称
scrapy startproject pach1
项目创建成功
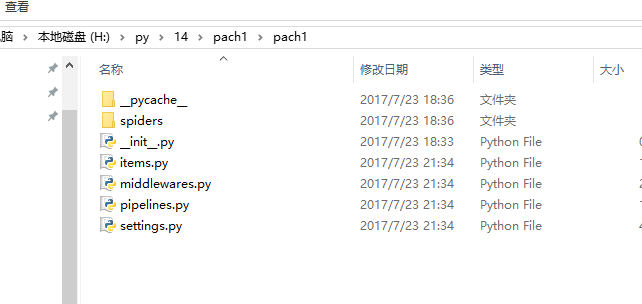
项目说明
目录结构如下:
├── firstCrawler
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
scrapy.cfg: 项目的配置文件tems.py: 项目中的item文件,用来定义解析对象对应的属性或字段。pipelines.py: 负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库)settings.py: 项目的设置文件.- spiders:实现自定义爬虫的目录
- middlewares.py:Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。

创建第一个爬虫
创建爬虫文件在spiders文件夹里创建
1、创建一个类必须继承scrapy.Spider类,类名称自定义
类里的属性和方法:
name属性,设置爬虫名称
allowed_domains属性,设置爬取的域名,不带http
start_urls属性,设置爬取的URL,带http
parse()方法,爬取页面后的回调方法,response参数是一个对象,封装了所有的爬取信息
response对象的方法和属性
response.url获取抓取的rul
response.body获取网页内容字节类型
response.body_as_unicode()获取网站内容字符串类型

# -*- coding: utf-8 -*-
import scrapy class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['www.shaimn.com']
start_urls = ['http://www.shaimn.com/xinggan/'] def parse(self, response):
current_url = response.url #获取抓取的rul
body = response.body #获取网页内容字节类型
unicode_body = response.body_as_unicode() #获取网站内容字符串类型
print(unicode_body)
爬虫写好后执行爬虫,cd到爬虫目录里执行scrapy crawl adc --nolog命令,说明:scrapy crawl adc(adc表示爬虫名称) --nolog(--nolog表示不显示日志)
也可以在PyCharm执行命令

三 web爬虫,scrapy模块介绍与使用的更多相关文章
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 爬虫-windows下安装Scrapy及scrapy模块介绍
一:安装wheel wheel介绍 二:安装twisted twisted是由python编写的一款基于事件驱动的网络引擎,使用twisted模块将python的异步请求(异步模型介绍)成为可能且简 ...
- 爬虫scrapy模块
首先下载scrapy模块 这里有惊喜 https://www.cnblogs.com/bobo-zhang/p/10068997.html 创建一个scrapy文件 首先在终端找到一个文件夹 输入 s ...
- python 爬虫 urllib模块介绍
一.urllib库 概念:urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urll ...
- python 爬虫 urllib模块 目录
python 爬虫 urllib模块介绍 python 爬虫 urllib模块 url编码处理 python 爬虫 urllib模块 反爬虫机制UA python 爬虫 urllib模块 发起post ...
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
随机推荐
- Andrew Ng机器学习编程作业:Anomaly Detection and Recommender Systems
作业文件 machine-learning-ex8 在本次练习,第一节我们将实现异常检测算法,并把它应用到检测网络故障服务器上.在第二部分,我们将使用协同过滤来构建电影推荐系统. 1. 异常检测 在这 ...
- 0505-Hystrix保护应用-Turbine集群状态监控
https://cloud.spring.io/spring-cloud-static/Edgware.SR3/single/spring-cloud.html#_turbine
- Django:学习笔记(4)——请求与响应
Django:学习笔记(4)——请求与响应 0.URL路由基础 Web应用中,用户通过不同URL链接访问我们提供的服务,其中首先经过的是一个URL调度器,它类似于SpringBoot中的前端控制器. ...
- React:快速上手(3)——列表渲染
React:快速上手(3)——列表渲染 使用map循环数组 了解一些ES6 ES6, 全称 ECMAScript 6.0 ,是 JaveScript 的下一个版本标准,2015.06 发版.ES6 主 ...
- Mac OS X下搭建Android开发环境(包括SDK和NDK)
资源准备: JDK Eclipse Android SDK Android NDK ADT CDT ANT 搭建Android SDK开发环境: 1.JDK安装,要求版本>1.5, Mac O ...
- Loopback接口的作用
Loopback接口是虚拟接口,是一种纯软件性质的虚拟接口.任何送到该接口的网络数据报文都会被认为是送往设备自身的.大多数平台都支持使用这种接口来模拟真正的接口.这样做的好处是虚拟接口不会像物理接口那 ...
- mysql中int(M) tinyint(M)中M的作用
原先对mysql不太理解,但也没有报错.但理解的不够深入.这次补上. 原来以为int(11)是指11个字节,int(10)就是10个字节.我错了. http://zhidao.baidu.com/li ...
- WPF MVVM模式下ComboBox级联效果 选择第一项
MVVM模式下做的省市区的级联效果.通过改变ComboBox执行命令改变市,区. 解决主要问题就是默认选中第一项 1.首先要定义一个属性,继承自INotifyPropertyChanged接口.我这里 ...
- sql 中 in 与 exist 的区别
可以 通过 where 条件 把 null的情况 筛选掉,已避免出现上述的情况. 1, exist 返回 true or false: in 返回 true unknow. not之后 not ...
- overflow应用场景
overflow属性可以设置的值有5种: (1)visible 默认值,内容不会裁剪,呈现在元素框之外: (2)hidden 内容会被裁剪,并且子元素内容是不可见的: (3)scroll 内容会被裁 ...