环境篇:Zeppelin
环境篇:Zeppelin
Zeppelin 是什么
Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的开源框架。Zeppelin提供了数据分析、数据可视化等功能。
Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。



如果没有Zeppelin?
数据分析师在数仓中提取数据时,需要自行整理sql,并且不能以图形展示,而且记录需要自己保存,对于常用的一些操作,每天需要去整理一些笔记,做很多繁杂的工作,包括开发工程师在定位问题后也很难将定位过程记录下来,而且在协同工作上需要借助通讯工具传来传去。这个时候就有了Zeppelin,其实就是一个超级笔记本啦。
1 安装
1.1 下载
zeppelin-0.8.2-bin-all
1.2 上传服务器
mkdir /usr/local/src/zeppelin
cd /usr/local/src/zeppelin

1.3 安装
tar -zxvf zeppelin-0.8.2-bin-all.tgz
#修改配置文件
cd zeppelin-0.8.2-bin-all/conf
cp zeppelin-env.sh.template zeppelin-env.sh
vim zeppelin-env.sh
#--->
#修改javahome
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
#修改IP端口
export ZEPPELIN_ADDR=192.168.192.10
export ZEPPELIN_PORT=8080
#修改SPARK_HOME(如果使用本地模式即可不配置)
export MASTER=spark://cdh01.cm:7077
export SPARK_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark
#修改HBASE_HOME
export HBASE_HOME=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase
export HBASE_CONF_DIR=/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/conf
#---<
1.4 启动停止
/usr/local/src/zeppelin/zeppelin-0.8.2-bin-all/bin/zeppelin-daemon.sh start
# /usr/local/src/zeppelin/zeppelin-0.8.2-bin-all/bin/zeppelin-daemon.sh stop
1.5 访问IP:8080端口
2 简单使用
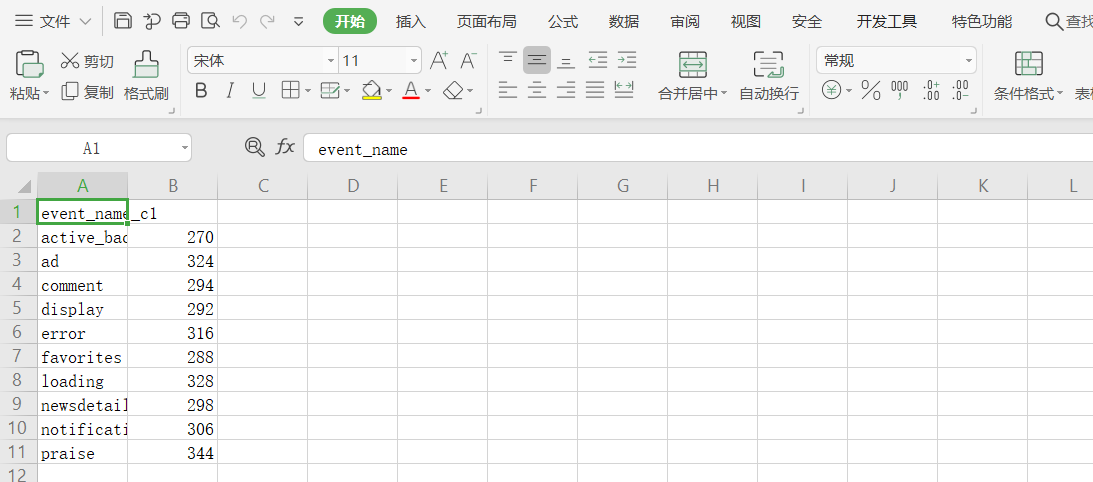
2.1 对接解释器,以hive为例

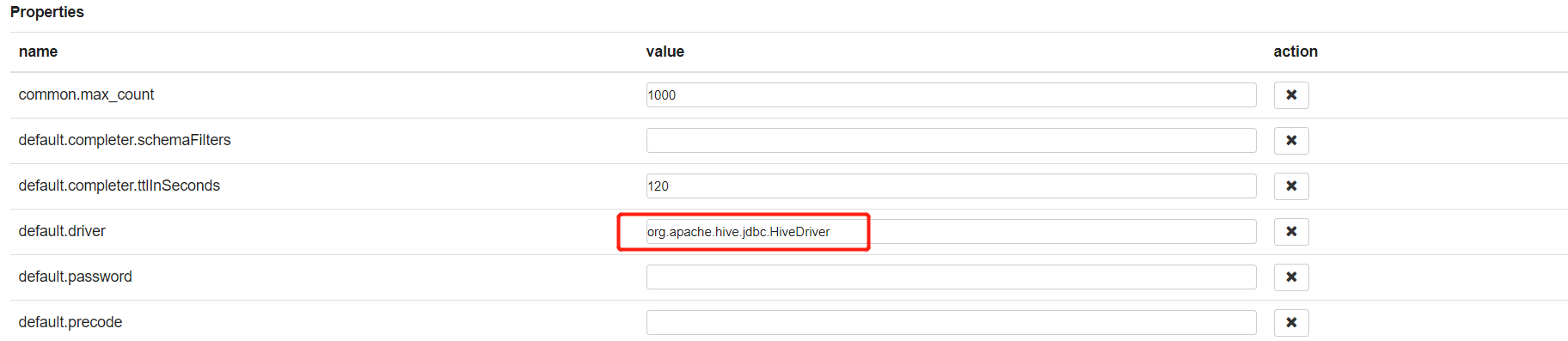
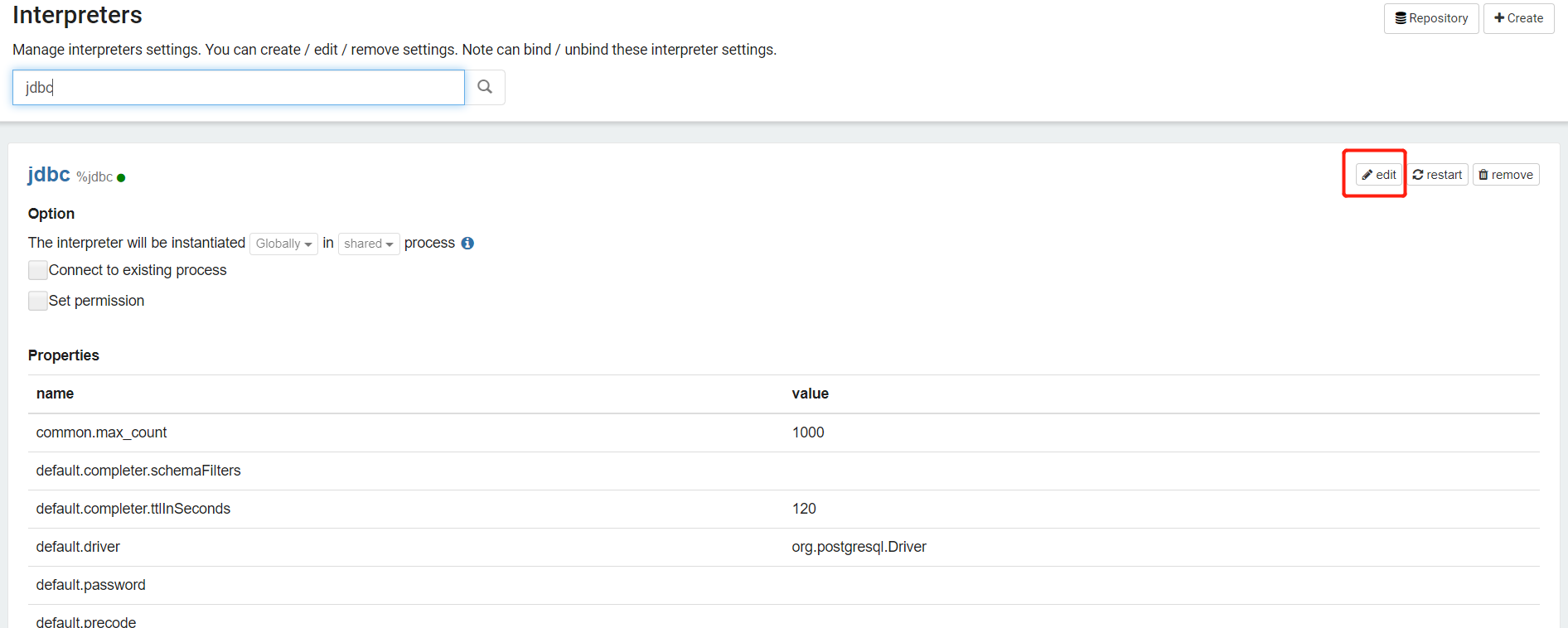

/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-jdbc.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-service-rpc.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-cli.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-service.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-common.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/hive-serde.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/guava-14.0.1.jar
- 使用
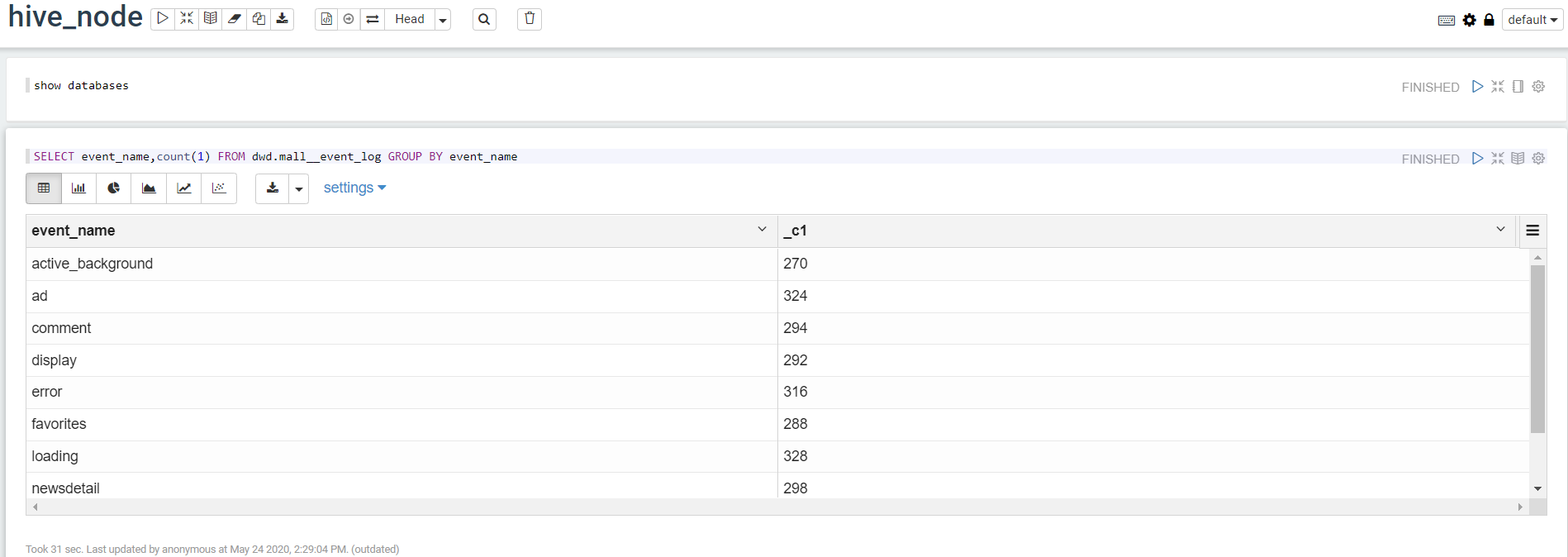
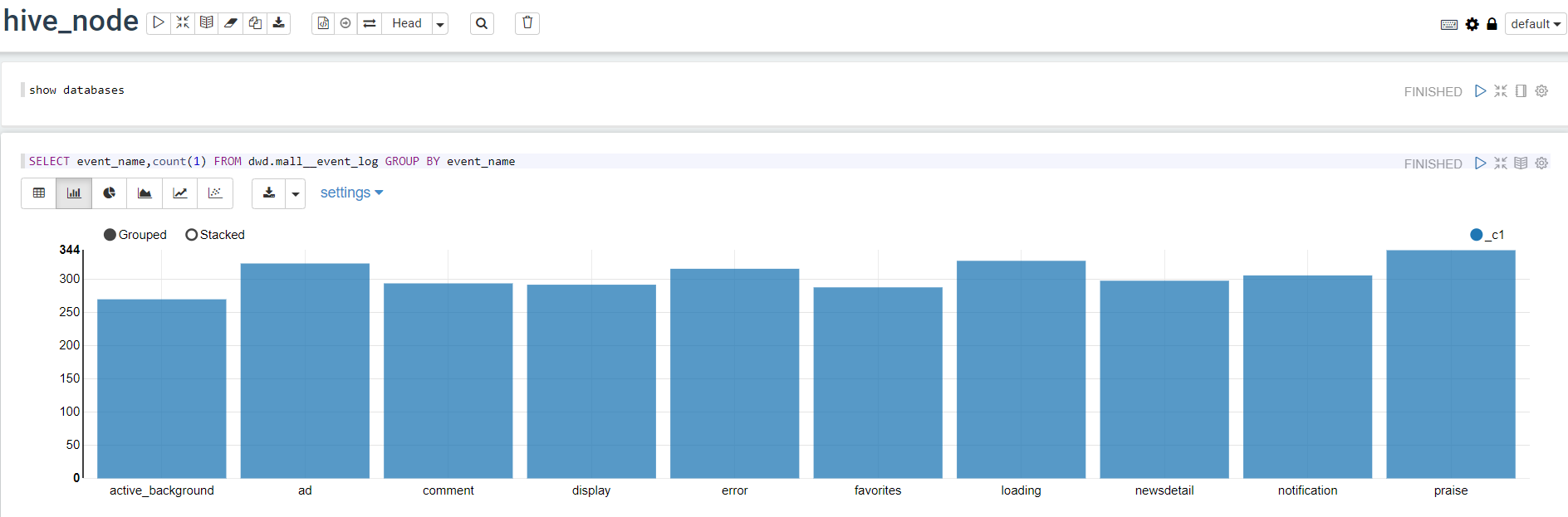
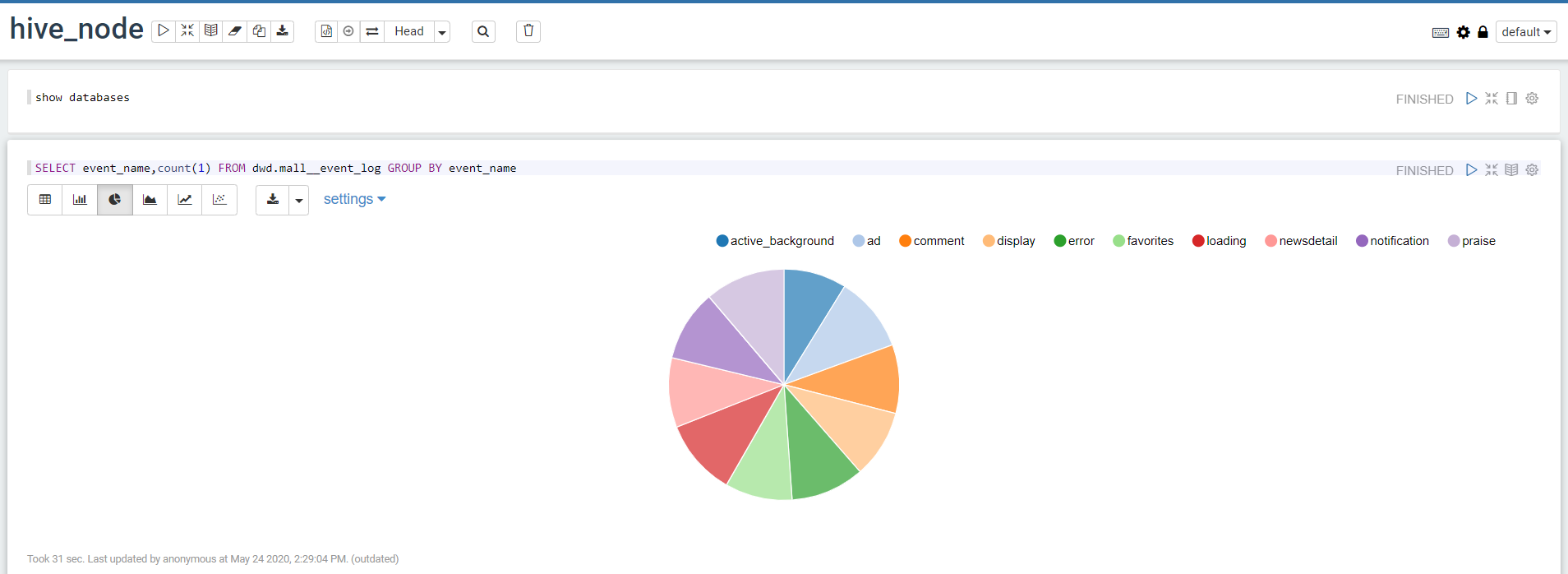



2.2 对接解释器,以Spark为例
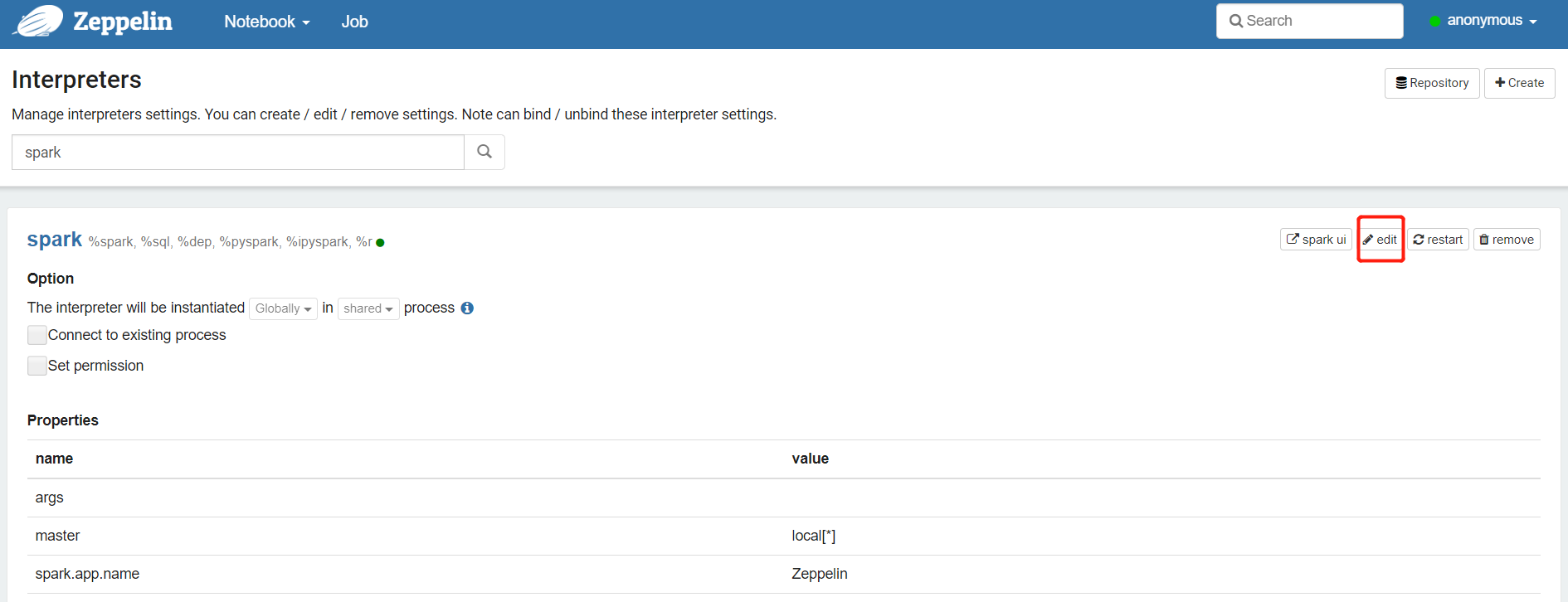
如需要使用集群模式配置
master yarn
spark.submit.deployMode cluster
spark.yarn.queue 列队名
spark.executor.memory 1g

- 使用
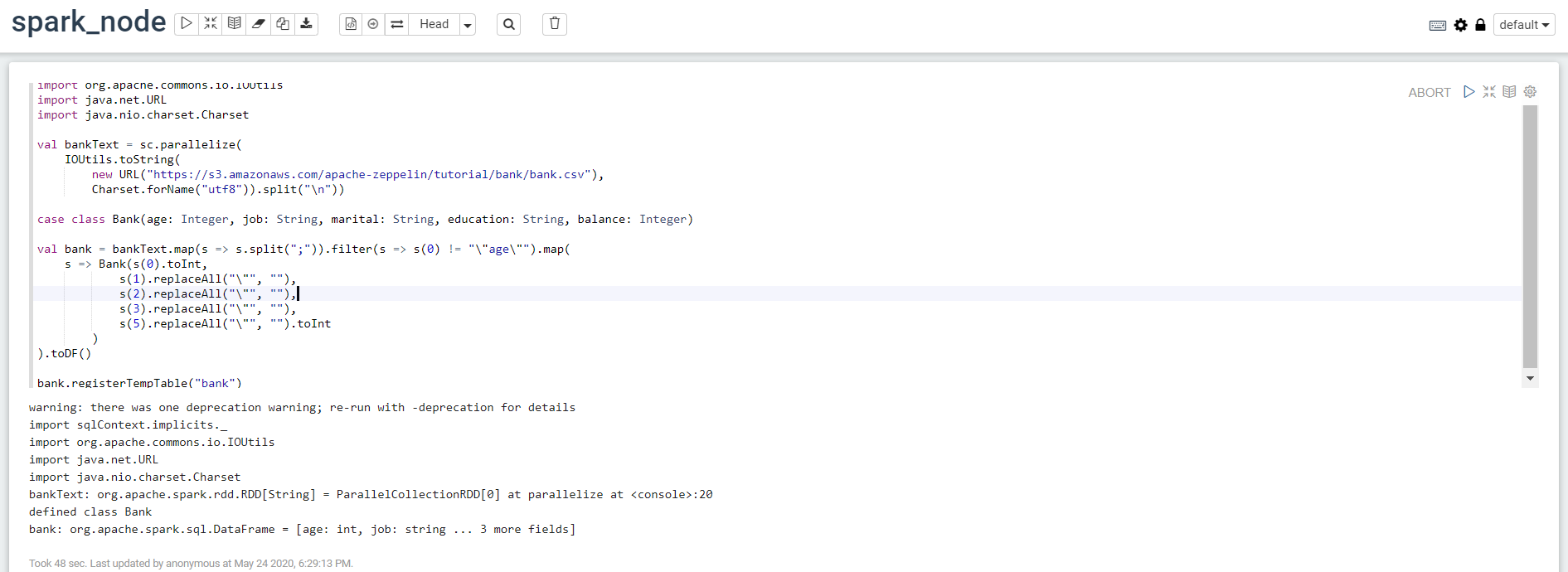
import org.apache.commons.io.IOUtils
import java.net.URL
import java.nio.charset.Charset
val bankText = sc.parallelize(
IOUtils.toString(
new URL("https://s3.amazonaws.com/apache-zeppelin/tutorial/bank/bank.csv"),
Charset.forName("utf8")).split("\n"))
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
val bank = bankText.map(s => s.split(";")).filter(s => s(0) != "\"age\"").map(
s => Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
).toDF()
bank.registerTempTable("bank")
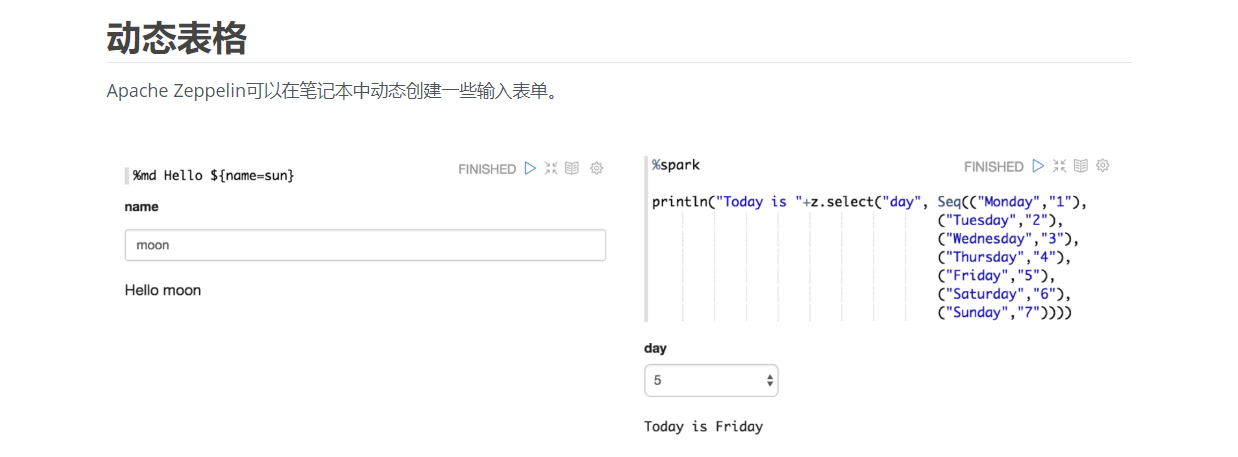
%sql
select age,count(1)
from bank
where age < ${maxAge=30}
group by age
order by age
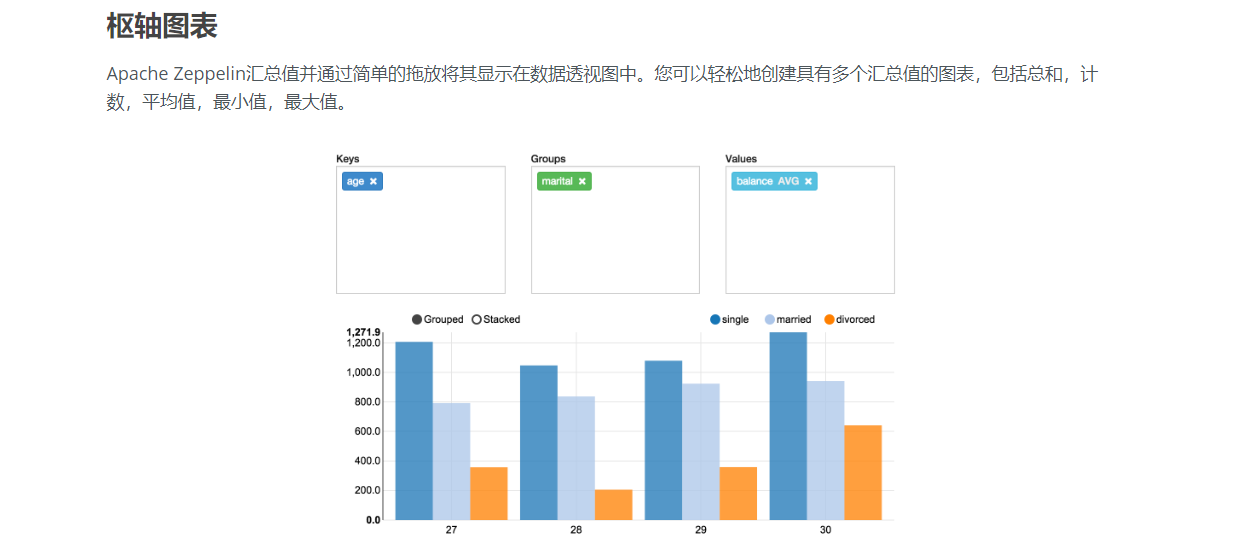
%sql
select age, count(1) value
from bank
where age < 30
group by age
order by age
%sql
select age, count(1) value
from bank
where marital="${marital=single,single|divorced|married}"
group by age
order by age

2.3 对接解释器,以Kylin为例
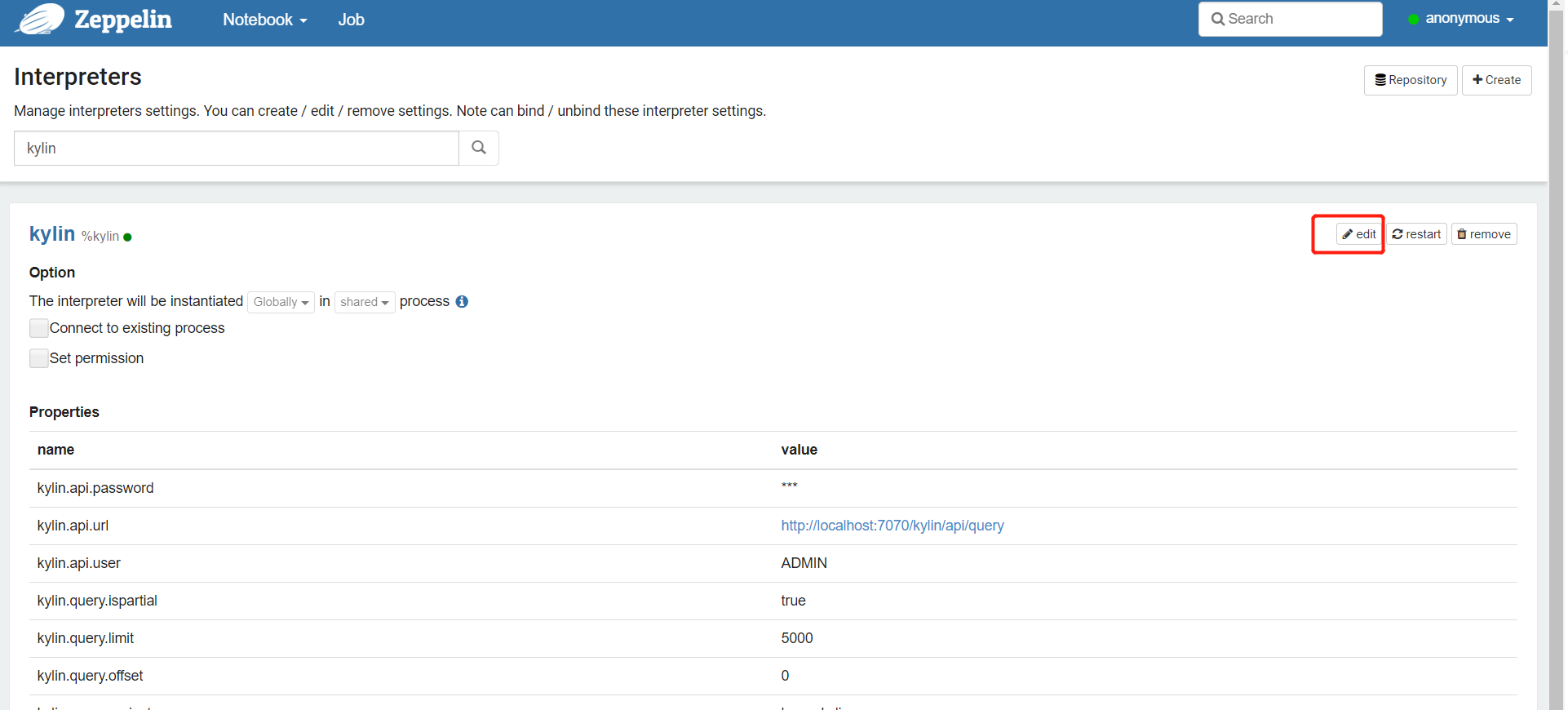
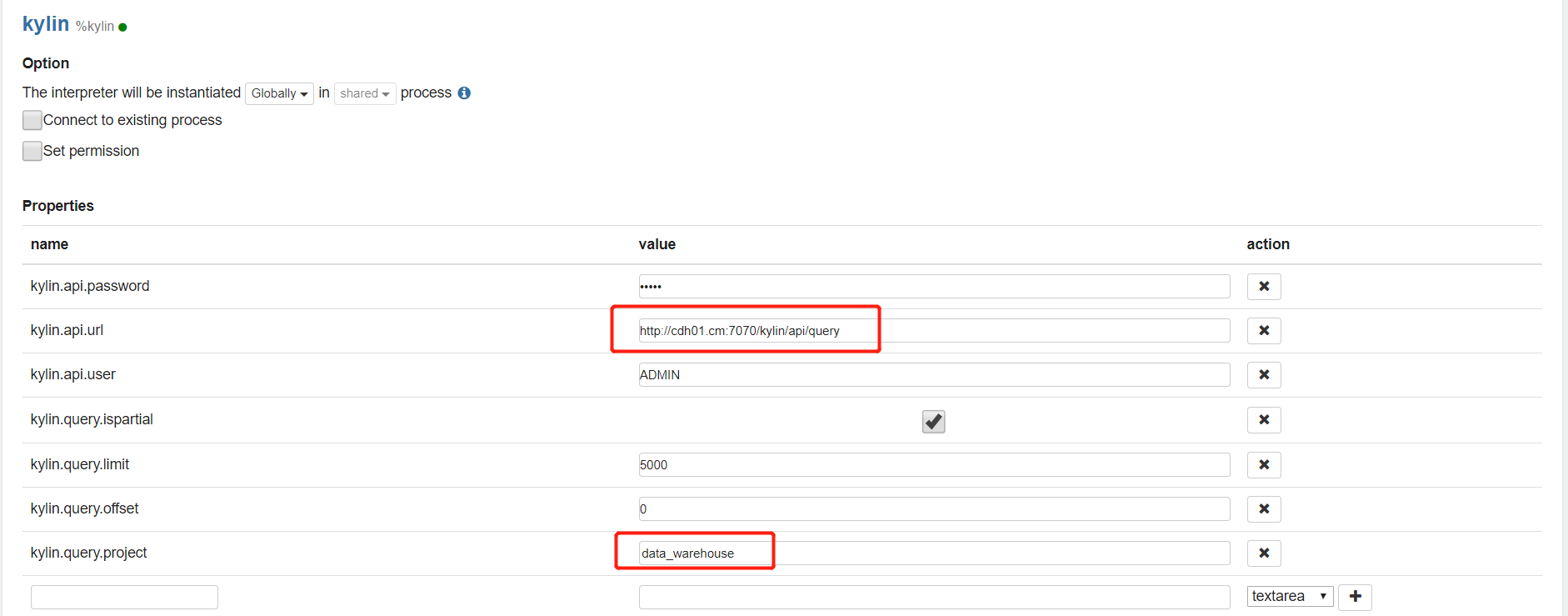
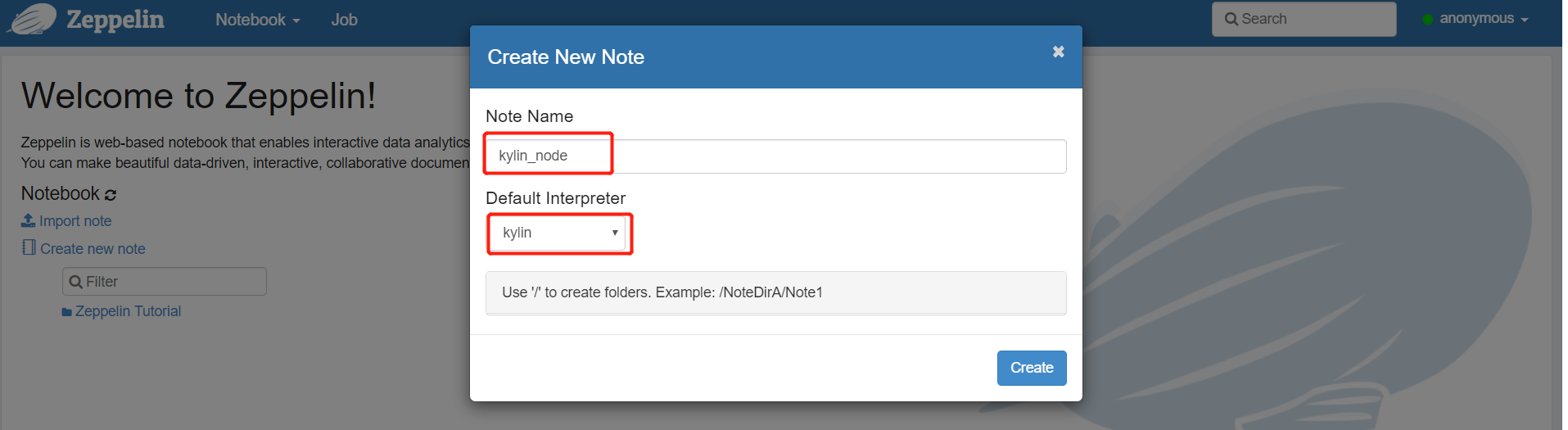
- 创建笔记,以下以麒麟为例
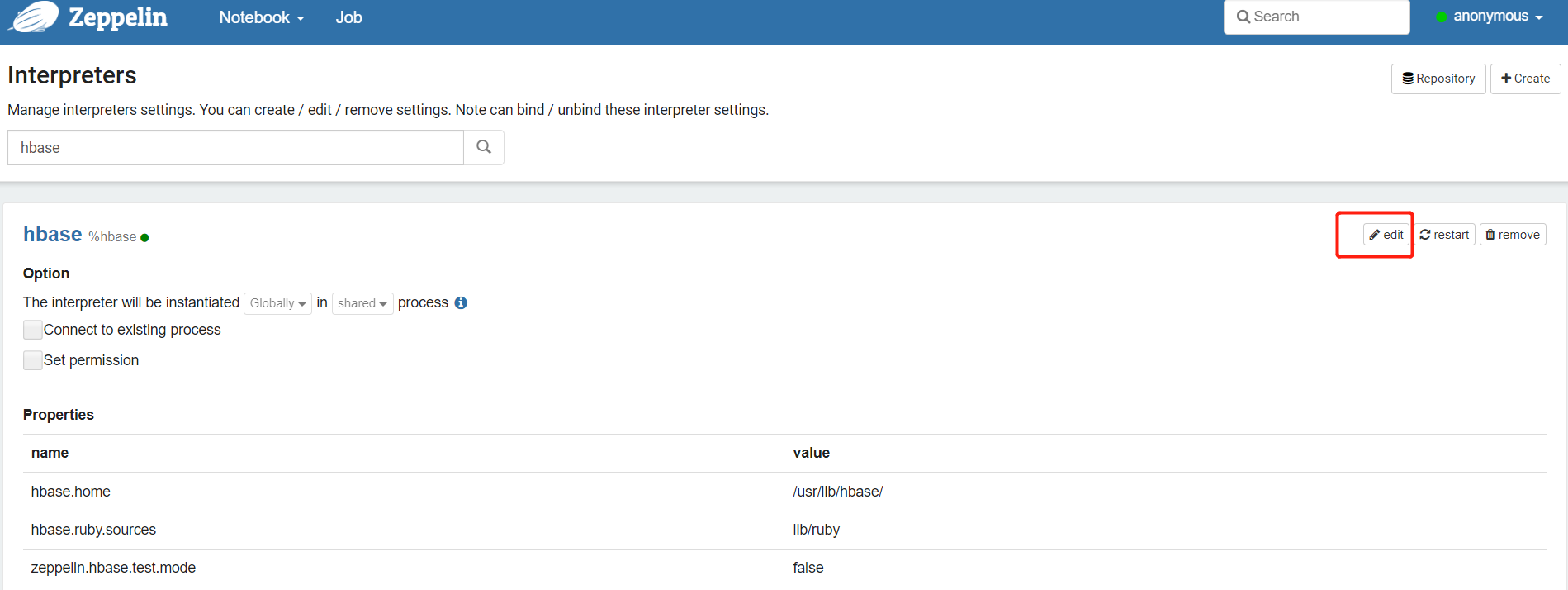
2.4 对接解释器,以Hbase为例
#将hbase配置文件copy到zeppelin下
cp /etc/hbase/conf/hbase-site.xml /usr/local/src/zeppelin/zeppelin-0.8.2-bin-all/conf/
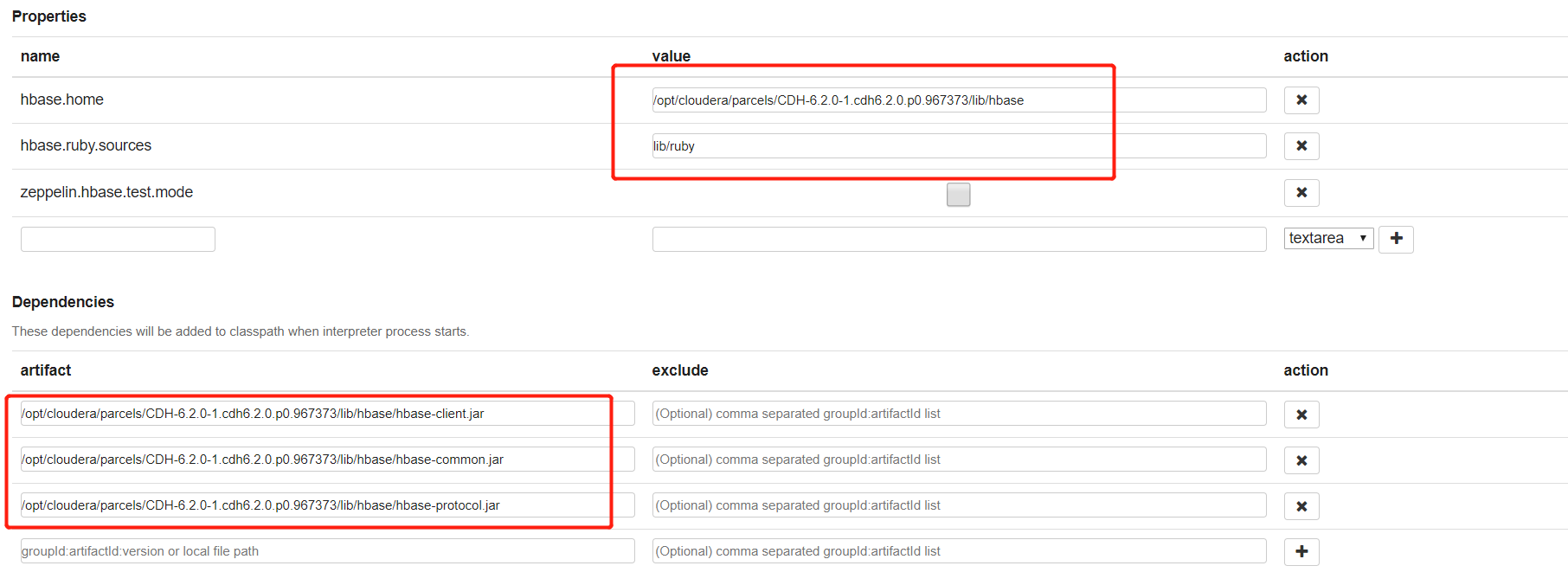
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/hbase-client.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/hbase-common.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/hbase-protocol.jar
- 使用
环境篇:Zeppelin的更多相关文章
- 环境篇:Kylin3.0.1集成CDH6.2.0
环境篇:Kylin3.0.1集成CDH6.2.0 Kylin是什么? Apache Kylin™是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析( ...
- 篇5 python自动化测试应用-Selenium环境篇
篇5 python自动化测试应用-Selenium环境篇 --lamecho 1.1概要 大家好!我是lamecho(辣么丑),从本篇开始我将开始 ...
- SpringBoot系列之profles配置多环境(篇二)
SpringBoot系列之profles配置多环境(篇二) 继续上篇博客SpringBoot系列之profles配置多环境(篇一)之后,继续写一篇博客进行补充 写Spring项目时,在测试环境是一套数 ...
- 环境篇:Docker
环境篇:Docker www.docker.com Docker 是什么? Docker 是一个开源的应用容器引擎,基于Go语言并遵从Apache协议的开源,让开发者可以打包他们的应用以及依赖包到一个 ...
- 环境篇:Virtualbox+Vagrant安装Centos7
环境篇:Virtualbox+Vagrant安装Centos7 1 安装Vagrant Vagrant下载地址:https://www.vagrantup.com/ Vagrant百度网盘:https ...
- 环境篇:VMware Workstation安装Centos7
环境篇:VMware Workstation安装Centos7 1 VMware Workstation安装 CentOS下载地址:http://isoredirect.centos.org/cent ...
- 环境篇:Atlas2.0.0兼容CDH6.2.0部署
环境篇:Atlas2.0.0兼容CDH6.2.0部署 Atlas 是什么? Atlas是一组可扩展和可扩展的核心基础治理服务,使企业能够有效地满足Hadoop中的合规性要求,并允许与整个企业数据生态系 ...
- 环境篇:Superset
环境篇:Superset Superset 是什么? Apache Superset 是一个开源.现代.轻量的BI分析工具,能够对接多种数据源,拥有丰富的图表展示形式.支持自定义仪表盘,用户界面友好, ...
- 环境篇:CM+CDH6.3.2环境搭建(全网最全)
环境篇:CM+CDH6.3.2环境搭建(全网最全) 一 环境准备 1.1 三台虚拟机准备 Master( 32g内存 + 100g硬盘 + 4cpu + 每个cpu2核) 2台Slave( 12g内存 ...
随机推荐
- 【DNS域名解析命令】host
host - DNS lookup utility host命令是常用的分析域名查询工具,可以用来测试域名系统工作是否正常. 语法: host [-aCdlnrsTwv] [-c class] [-N ...
- 2.Python是什么?使用Python的好处是什么?
Python是什么?使用Python的好处是什么? 答: Python is a programming language with objects, modules, threads, except ...
- 编写C#程序的IDE
编写C#程序,在Windows平台下,除了昂贵的Visual Studio.NET这个正宗的工具外,你还了解哪些? 听说有个Eclipse,IBM投钱开发的开源工具,有人也做了个for .NET的pl ...
- iOS自定义tabBar
在我们的项目中经常会自己自定义tabBar因为苹果自带的真的太丑了!也不满足我们的项目需求. 好 开始行动吧! 先上图看下我们最终实现的效果: 继承UItabBar自定义一个自己的tabBar .h# ...
- Nodejs与Mysql交互实现(异步写法,同步写法)
https://blog.csdn.net/think_A_lot/article/details/93498737
- 2019-2020 ICPC, Asia Jakarta Regional Contest C. Even Path(思维)
Pathfinding is a task of finding a route between two points. It often appears in many problems. For ...
- Flutter 打包Android APK 笔记与事项
获取一个KEY 首先要获取 你的 打包应用的一个 key ,这一步其实和 在AndroidStudio 上打包 APK 一样,都是要注册一个本地的 key,key 其实也就是 jks文件啦. 如果已经 ...
- A - Aragorn's Story HDU - 3966 树剖裸题
这个题目是一个比较裸的树剖题,很好写. http://acm.hdu.edu.cn/showproblem.php?pid=3966 #include <cstdio> #include ...
- Spring中bean的四种注入方式
一.前言 最近在复习Spring的相关内容,这篇博客就来记录一下Spring为bean的属性注入值的四种方式.这篇博客主要讲解在xml文件中,如何为bean的属性注入值,最后也会简单提一下使用注解 ...
- Python:日薪工资计算
劳动者离职,当天要结清工资,实际操作是当天算清,三日内结清.有的公司省人力和吃利息,统一计算,统一下月月底发放. 有时要验算下离职工资,用Python操作一番,输入计时天数.请假小时.加班小时.基本工 ...