TensorFlow从0到1之TensorFlow优化器(13)
高中数学学过,函数在一阶导数为零的地方达到其最大值和最小值。梯度下降算法基于相同的原理,即调整系数(权重和偏置)使损失函数的梯度下降。
在回归中,使用梯度下降来优化损失函数并获得系数。本节将介绍如何使用 TensorFlow 的梯度下降优化器及其变体。
按照损失函数的负梯度成比例地对系数(W 和 b)进行更新。根据训练样本的大小,有三种梯度下降的变体:
- Vanilla 梯度下降:在 Vanilla 梯度下降(也称作批梯度下降)中,在每个循环中计算整个训练集的损失函数的梯度。该方法可能很慢并且难以处理非常大的数据集。该方法能保证收敛到凸损失函数的全局最小值,但对于非凸损失函数可能会稳定在局部极小值处。
- 随机梯度下降:在随机梯度下降中,一次提供一个训练样本用于更新权重和偏置,从而使损失函数的梯度减小,然后再转向下一个训练样本。整个过程重复了若干个循环。由于每次更新一次,所以它比 Vanilla 快,但由于频繁更新,所以损失函数值的方差会比较大。
- 小批量梯度下降:该方法结合了前两者的优点,利用一批训练样本来更新参数。
TensorFlow优化器的使用
首先确定想用的优化器。TensorFlow 为你提供了各种各样的优化器:
- 这里从最流行、最简单的梯度下降优化器开始:
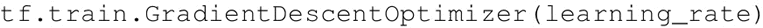
GradientDescentOptimizer 中的 learning_rate 参数可以是一个常数或张量。它的值介于 0 和 1 之间。
必须为优化器给定要优化的函数。使用它的方法实现最小化。该方法计算梯度并将梯度应用于系数的学习。该函数在 TensorFlow 文档中的定义如下:

综上所述,这里定义计算图:

馈送给 feed_dict 的 X 和 Y 数据可以是 X 和 Y 个点(随机梯度)、整个训练集(Vanilla)或成批次的。
- 梯度下降中的另一个变化是增加了动量项。为此,使用优化器 tf.train.MomentumOptimizer()。它可以把 learning_rate 和 momentum 作为初始化参数:
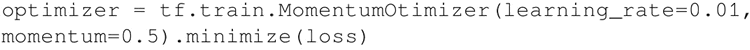
- 可以使用 tf.train.AdadeltaOptimizer() 来实现一个自适应的、单调递减的学习率,它使用两个初始化参数 learning_rate 和衰减因子 rho:

- TensorFlow 也支持 Hinton 的 RMSprop,其工作方式类似于 Adadelta 的 tf.train.RMSpropOptimizer():
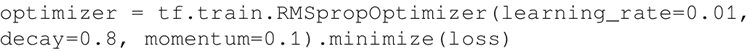
Adadelta 和 RMSprop 之间的细微不同可参考 http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf 和 https://arxiv.org/pdf/1212.5701.pdf。
- 另一种 TensorFlow 支持的常用优化器是 Adam 优化器。该方法利用梯度的一阶和二阶矩对不同的系数计算不同的自适应学习率:
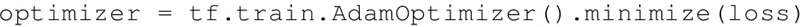
- 除此之外,TensorFlow 还提供了以下优化器:

通常建议你从较大学习率开始,并在学习过程中将其降低。这有助于对训练进行微调。可以使用 TensorFlow 中的 tf.train.exponential_decay 方法来实现这一点。
根据 TensorFlow 文档,在训练模型时,通常建议在训练过程中降低学习率。该函数利用指数衰减函数初始化学习率。需要一个 global_step 值来计算衰减的学习率。可以传递一个在每个训练步骤中递增的 TensorFlow 变量。函数返回衰减的学习率。
变量:
- learning_rate:标量float32或float64张量或者Python数字。初始学习率。
- global_step:标量int32或int64张量或者Python数字。用于衰减计算的全局步数,非负。
- decay_steps:标量int32或int64张量或者Python数字。正数,参考之前所述的衰减计算。
- decay_rate:标量float32或float64张量或者Python数字。衰减率。
- staircase:布尔值。若为真则以离散的间隔衰减学习率。
- name:字符串。可选的操作名。默认为ExponentialDecay。
返回:
- 与learning_rate类型相同的标量张量。衰减的学习率。
实现指数衰减学习率的代码如下:

推荐阅读
下面是讲解不同优化器的链接:
- https://arxiv.org/pdf/1609.04747.pdf:该文章提供了不同优化器算法的综述。
- https://www.tensorflow.org/api_guides/python/train#Optimizers:这是 TensorFlow.org 链接,详述了 TensorFlow 中优化器的使用方法。
- https://arxiv.org/pdf/1412.6980.pdf:关于 Adam 优化器的论文。
TensorFlow从0到1之TensorFlow优化器(13)的更多相关文章
- TensorFlow从0到1之TensorFlow Keras及其用法(25)
Keras 是与 TensorFlow 一起使用的更高级别的作为后端的 API.添加层就像添加一行代码一样简单.在模型架构之后,使用一行代码,你可以编译和拟合模型.之后,它可以用于预测.变量声明.占位 ...
- TensorFlow从0到1之TensorFlow多层感知机函数逼近过程(23)
Hornik 等人的工作(http://www.cs.cmu.edu/~bhiksha/courses/deeplearning/Fall.2016/notes/Sonia_Hornik.pdf)证明 ...
- TensorFlow从0到1之TensorFlow实现反向传播算法(21)
反向传播(BPN)算法是神经网络中研究最多.使用最多的算法之一,它用于将输出层中的误差传播到隐藏层的神经元,然后用于更新权重. 学习 BPN 算法可以分成以下两个过程: 正向传播:输入被馈送到网络,信 ...
- TensorFlow从0到1之TensorFlow超参数及其调整(24)
正如你目前所看到的,神经网络的性能非常依赖超参数.因此,了解这些参数如何影响网络变得至关重要. 常见的超参数是学习率.正则化器.正则化系数.隐藏层的维数.初始权重值,甚至选择什么样的优化器优化权重和偏 ...
- TensorFlow从0到1之TensorFlow多层感知机实现MINIST分类(22)
TensorFlow 支持自动求导,可以使用 TensorFlow 优化器来计算和使用梯度.它使用梯度自动更新用变量定义的张量.本节将使用 TensorFlow 优化器来训练网络. 前面章节中,我们定 ...
- TensorFlow从0到1之TensorFlow实现单层感知机(20)
简单感知机是一个单层神经网络.它使用阈值激活函数,正如 Marvin Minsky 在论文中所证明的,它只能解决线性可分的问题.虽然这限制了单层感知机只能应用于线性可分问题,但它具有学习能力已经很好了 ...
- TensorFlow从0到1之TensorFlow实现多元线性回归(16)
在 TensorFlow 实现简单线性回归的基础上,可通过在权重和占位符的声明中稍作修改来对相同的数据进行多元线性回归. 在多元线性回归的情况下,由于每个特征具有不同的值范围,归一化变得至关重要.这里 ...
- TensorFlow从0到1之TensorFlow实现简单线性回归(15)
本节将针对波士顿房价数据集的房间数量(RM)采用简单线性回归,目标是预测在最后一列(MEDV)给出的房价. 波士顿房价数据集可从http://lib.stat.cmu.edu/datasets/bos ...
- TensorFlow从0到1之TensorFlow常用激活函数(19)
每个神经元都必须有激活函数.它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性.该函数取所有输入的加权和,进而生成一个输出信号.你可以把它看作输入和输出之间的转换.使用适当的激活函数,可以将输出 ...
随机推荐
- MySQL的日期类型
-- MySQL 中有多种数据类型可以用于日期和时间的表示,不同的版本可能有所差异,表 3-2 中-- 列出了 MySQL 5.0 中所支持的日期和时间类型.-- 表 3-2 MySQL 中的日期和时 ...
- indetityserver4-implicit-grant-types-请求流程叙述-下篇
上一篇将请求流程描述一遍,这篇将描述一下相关的源码. 1 访问客户端受保护的资源 GET /Home/Secure HTTP/1.1HTTP/1.1 302 Found Date: Tue, 23 O ...
- JAVA课程学习感想
JAVA课程学习感想 在学习JAVA之前,我们学习了C语言,汇编语言,数据结构等等.虽然学习了这些,但对于JAVA来说,学习起来不是那么容易,所有的计算机语言有相似的地方,但他们更有不同的地方.对我来 ...
- idea创建maven项目慢的原因以及解决方案
问题分析;在idea中maven项目所依赖的jar包,默认是从中央仓库直接下载jar包,不管jar包是否在本地仓库存在,所以导致idea创建maven项目速度慢,那么要解决这个问题,那么将idea设置 ...
- DC-8靶机writeup
nmap -sV 172.16.61.129 -A 看下端口信息 nid=1 ‘ 报错,存在注入,扔到sqlmap跑 sqlmap -u http://172.16.61.129/?nid=1 --d ...
- 2020本科校招-从小白到拿到30k offer的学习经历
本文是个人的2020年年中总结 还有十几天就要毕业,面临着身份从学生到互联网社畜的转变,未来的一切捉摸不定,但凡心中万千情绪,也只能「但行好事,莫问前程」. 介绍下博主背景:计算机本科大四,刚进大三时 ...
- 15 . PythonWeb框架本质
PythonWeb框架的本质 简单描述就是:浏览器通过你输入的网址给你的socket服务端发送请求,服务端接受到请求给其回复一个对应的html页面,这就是web项目.所有的Web应用本质上就是一个so ...
- 01 . Nginx简介及部署
Nginx简介 Nginx(发音同engine x)是一个异步框架的 Web 服务器,也可以用作反向代理,负载平衡器 和 HTTP 缓存.该软件由 Igor Sysoev 创建,并于2004年首次公开 ...
- Rocket - tilelink - SourceShrinker
https://mp.weixin.qq.com/s/1vyfhZuF4RyRE5Qjj6AGWA 简单介绍SourceShrinker的实现. 1. 基本介绍 用于把上游节点的 ...
- Rocket - config - implicit Parameters
https://mp.weixin.qq.com/s/OH_Z1gdSUpfgM-tjx0OlrA 追溯配置信息的源头. 0. HasRocketCoreParameters Has ...