Python爬虫从入门到放弃(十三)之 Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍
创建爬虫项目
scrapy startproject 项目名
例子如下:
localhost:spider zhaofan$ scrapy startproject test1
New Scrapy project 'test1', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/zhaofan/Documents/python_project/spider/test1 You can start your first spider with:
cd test1
scrapy genspider example example.com
localhost:spider zhaofan$
这个时候爬虫的目录结构就已经创建完成了,目录结构如下:
|____scrapy.cfg
|____test1
| |______init__.py
| |____items.py
| |____middlewares.py
| |____pipelines.py
| |____settings.py
| |____spiders
| | |______init__.py
接着我们按照提示可以生成一个spider,这里以百度作为例子,生成spider的命令格式为;
scrapy genspider 爬虫名字 爬虫的网址
localhost:test1 zhaofan$ scrapy genspider baiduSpider baidu.com
Created spider 'baiduSpider' using template 'basic' in module:
test1.spiders.baiduSpider
localhost:test1 zhaofan$
关于命令详细使用
命令的使用范围
这里的命令分为全局的命令和项目的命令,全局的命令表示可以在任何地方使用,而项目的命令只能在项目目录下使用
全局的命令有:
startproject
genspider
settings
runspider
shell
fetch
view
version
项目命令有:
crawl
check
list
edit
parse
bench
startproject
这个命令没什么过多的用法,就是在创建爬虫项目的时候用
genspider
用于生成爬虫,这里scrapy提供给我们不同的几种模板生成spider,默认用的是basic,我们可以通过命令查看所有的模板
localhost:test1 zhaofan$ scrapy genspider -l
Available templates:
basic
crawl
csvfeed
xmlfeed
localhost:test1 zhaofan$
当我们创建的时候可以指定模板,不指定默认用的basic,如果想要指定模板则通过
scrapy genspider -t 模板名字
localhost:test1 zhaofan$ scrapy genspider -t crawl zhihuspider zhihu.com
Created spider 'zhihuspider' using template 'crawl' in module:
test1.spiders.zhihuspider
localhost:test1 zhaofan$
crawl
这个是用去启动spider爬虫格式为:
scrapy crawl 爬虫名字
这里需要注意这里的爬虫名字和通过scrapy genspider 生成爬虫的名字是一致的
check
用于检查代码是否有错误,scrapy check
list
scrapy list列出所有可用的爬虫
fetch
scrapy fetch url地址
该命令会通过scrapy downloader 讲网页的源代码下载下来并显示出来
这里有一些参数:
--nolog 不打印日志
--headers 打印响应头信息
--no-redirect 不做跳转
view
scrapy view url地址
该命令会讲网页document内容下载下来,并且在浏览器显示出来
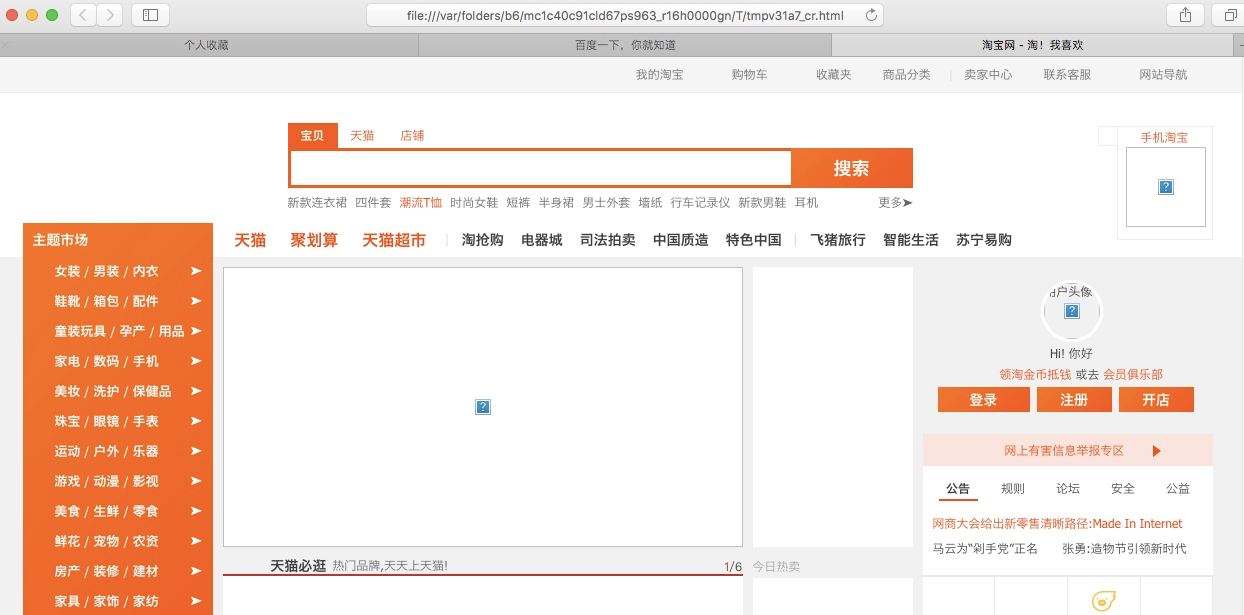
因为现在很多网站的数据都是通过ajax请求来加载的,这个时候直接通过requests请求是无法获取我们想要的数据,所以这个view命令可以帮助我们很好的判断
shell
这是一个命令行交互模式
通过scrapy shell url地址进入交互模式
这里我么可以通过css选择器以及xpath选择器获取我们想要的内容(xpath以及css选择的用法会在下个文章中详细说明),例如我们通过scrapy shell http://www.baidu.com
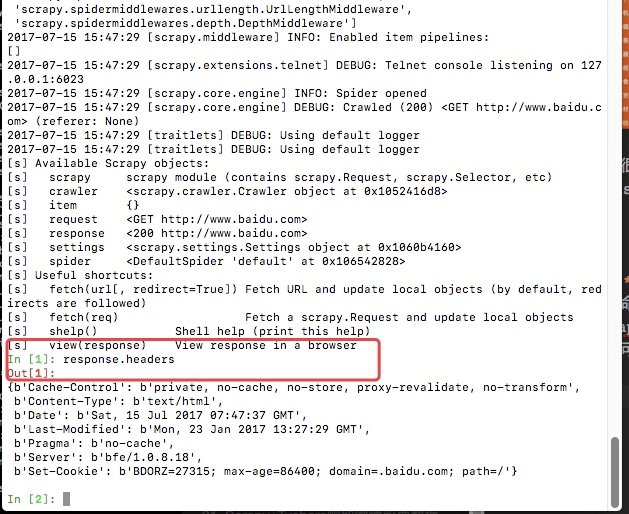
这里最后给我们返回一个response,这里的response就和我们通requests请求网页获取的数据是相同的。
view(response)会直接在浏览器显示结果
response.text 获取网页的文本
下图是css选择器的一个简单用法

settings
获取当前的配置信息
通过scrapy settings -h可以获取这个命令的所有帮助信息
localhost:jobboleSpider zhaofan$ scrapy settings -h
Usage
=====
scrapy settings [options] Get settings values Options
=======
--help, -h show this help message and exit
--get=SETTING print raw setting value
--getbool=SETTING print setting value, interpreted as a boolean
--getint=SETTING print setting value, interpreted as an integer
--getfloat=SETTING print setting value, interpreted as a float
--getlist=SETTING print setting value, interpreted as a list Global Options
--------------
--logfile=FILE log file. if omitted stderr will be used
--loglevel=LEVEL, -L LEVEL
log level (default: DEBUG)
--nolog disable logging completely
--profile=FILE write python cProfile stats to FILE
--pidfile=FILE write process ID to FILE
--set=NAME=VALUE, -s NAME=VALUE
set/override setting (may be repeated)
--pdb enable pdb on failure
拿一个例子进行简单的演示:(这里是我的这个项目的settings配置文件中配置了数据库的相关信息,可以通过这种方式获取,如果没有获取的则为None)
localhost:jobboleSpider zhaofan$ scrapy settings --get=MYSQL_HOST
192.168.1.18
localhost:jobboleSpider zhaofan$
runspider
这个和通过crawl启动爬虫不同,这里是scrapy runspider 爬虫文件名称
所有的爬虫文件都是在项目目录下的spiders文件夹中
version
查看版本信息,并查看依赖库的信息
localhost:~ zhaofan$ scrapy version
Scrapy 1.3.
localhost:~ zhaofan$ scrapy version -v
Scrapy : 1.3.
lxml : 3.7.3.0
libxml2 : 2.9.
cssselect : 1.0.
parsel : 1.1.
w3lib : 1.17.
Twisted : 17.1.
Python : 3.5. (v3.5.2:4def2a2901a5, Jun , ::) - [GCC 4.2. (Apple Inc. build ) (dot )]
pyOpenSSL : 16.2. (OpenSSL 1.0.2k Jan )
Platform : Darwin-16.6.-x86_64-i386-64bit
Python爬虫从入门到放弃(十三)之 Scrapy框架的命令行详解的更多相关文章
- Python之爬虫(十五) Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- python爬虫从入门到放弃(四)之 Requests库的基本使用
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- python爬虫从入门到放弃前奏之学习方法
首谈方法 最近在整理爬虫系列的博客,但是当整理几篇之后,发现一个问题,不管学习任何内容,其实方法是最重要的,按照我之前写的博客内容,其实学起来还是很点枯燥不能解决传统学习过程中的几个问题: 这个是普通 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- python爬虫从入门到放弃(四)之 Requests库的基本使用(转)
什么是Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库如果你看过上篇文章关于urllib库的使用,你会发现,其 ...
- Python爬虫从入门到放弃 之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
随机推荐
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- VR全景智慧城市——商家的需求才是全景市场的核心竞争力
消费者视角痛点:比如酒店消费行业,很多消费者在预订酒店过程中,都遇到过这样的场景:网上照片里酒店房间看着宽敞明亮,格调不凡,感觉非常喜欢,等真正推开房门插上房卡一看,却大失所望.在酒店行业,网上照片和 ...
- hdu4081
hdu4081 题意 给出n个点坐标,每个点有权值,要求得到一颗生成树,且其中有一条道路修建不需要花费,但是要求这条道路所连接的两点的权值之和除以剩下所有道路的距离花费最大. 分析 首先求最小生成树, ...
- JavaSE教程-04Java中循环语句for,while,do···while-思维导图
思维导图看不清楚时: 1)可以将图片另存为图片,保存在本地来查看 2)右击在新标签中打开放大查看
- datagrid 添加、修改、删除(转载)
原链接:JQueryEasyUI学习笔记(十)datagrid 添加.修改.删除 基于datagrid框架的删除.添加与修改: 主要是批量删除,双击表单修改.选中行修改,增加行修改,再有就是扩展edi ...
- python装饰器大详解
1.作用域 在python中,作用域分为两种:全局作用域和局部作用域. 全局作用域是定义在文件级别的变量,函数名.而局部作用域,则是定义函数内部. 关于作用域,我要理解两点:a.在全局不能访问到局部定 ...
- jquery实现导航栏效果
<html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="C ...
- 利用base64库暴力破解base加密
做个base加密题python语法出了一堆错误..... 附上py中关于base加密/解码的知识:http://www.open-open.com/lib/view/open1433990719973 ...
- .NET中使用Redis总结
注:关于如何在windows,linux下配置redis,详见这篇文章:) 启动遇到问题 使用命令[redis-server.exe redis.windows.conf],启动redis 服务[如果 ...
- Java中的事件监听机制
鼠标事件监听机制的三个方面: 1.事件源对象: 事件源对象就是能够产生动作的对象.在Java语言中所有的容器组件和元素组件都是事件监听中的事件源对象.Java中根据事件的动作来区分不同的事件源对象,动 ...