python: 爬取[博海拾贝]图片脚本
练手代码,聊作备忘:
# encoding: utf-8
# from __future__ import unicode_literals import urllib
import urllib2
import re
import os
import time
from threading import Thread class BhsbSpider(object):
_url = r'https://bh.sb/post/category/main/';
_page_count = 0
_page_index = 0 def __init__(self, url, page_count = 0):
self._url = url
self._page_count = page_count
folder = '博海拾贝'.decode('utf-8')
if not os.path.exists(folder):
os.mkdir(folder) def spider(self):
while self._page_index < self._page_count:
self._page_index += 1
self._url = r'https://bh.sb/post/category/main/page/%d' % self._page_index
self.do_spider(self._url) def do_spider(self, url):
html = self.get_html(url)
pattern = r'(?s)<h2><a\s+href="(?P<url>[^"]+).*?>\[博海拾贝\d+\](?P<title>[^<]+).*?'
for i, m in enumerate(re.findall(pattern, html)):
info = '%d. url: %s, title: %s' % ((self._page_index - 1) * 20 + i + 1, m[0], m[1])
print info
# 多线程爬取页面
Thread(target=self.download, args=(m[0], m[1])).start()
time.sleep(2) def download(self, url, title):
title = '博海拾贝\\' + title
title = title.decode('utf-8')
if not os.path.exists(title):
os.mkdir(title)
html = self.get_html(url)
pattern = r'(?s)<p>(?P<title>[^<]+).*?<p><img\s+src="(?P<image>[^"]+)"'
for i, m in enumerate(re.findall(pattern, html)):
img_title = m[0]
img_url = m[1]
img_filename = '%s/%s%s' % (title.encode('utf-8'), img_title, os.path.splitext(img_url)[1])
img_filename = img_filename.decode('utf-8')
print 'download %s ...' % img_filename
if not os.path.exists(img_filename):
Thread(target=urllib.urlretrieve, args=(img_url, img_filename)).start()
time.sleep(1) def get_html(self, url):
try:
url = url.encode('utf-8')
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.9.5.1000 Chrome/39.0.2146.0 Safari/537.36')
page = urllib2.urlopen(req)
return page.read()
except Exception as ex:
print 'get url_%s html error, ex=%s' % (url, ex) if __name__ == '__main__':
url = r'https://bh.sb/post/category/main/'
bs = BhsbSpider(url, 10)
bs.spider()
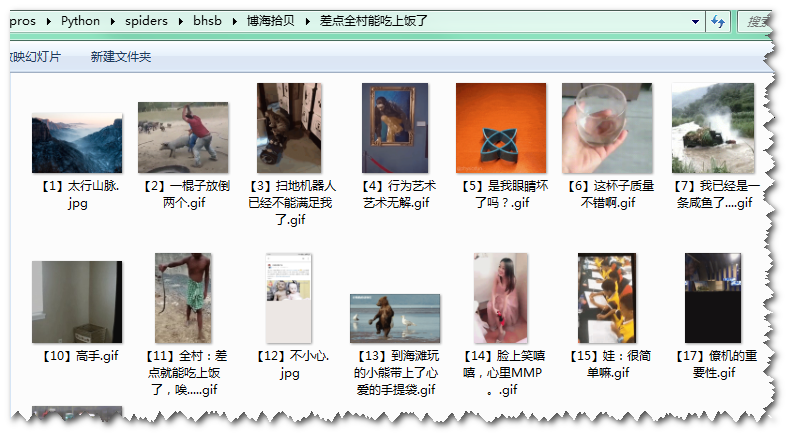
未及细测试,其间有图片丢失情况。结果如下图示:
python: 爬取[博海拾贝]图片脚本的更多相关文章
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Python 爬取陈都灵百度图片
Python 爬取陈都灵百度图片 标签(空格分隔): 随笔 今天意外发现了自己以前写的一篇爬虫脚本,爬取的是我的女神陈都灵,尝试运行了一下发现居然还能用.故把脚本贴出来分享一下. import req ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- Python爬取 | 唯美女生图片
这里只是代码展示,且复制后不能直接运行,需要配置一些设置才行,具体请查看下方链接介绍: Python爬取 | 唯美女生图片 from selenium import webdriver from fa ...
- python爬取网页文本、图片
从网页爬取文本信息: eg:从http://computer.swu.edu.cn/s/computer/kxyj2xsky/中爬取讲座信息(讲座时间和讲座名称) 注:如果要爬取的内容是多页的话,网址 ...
- Python爬取mn52网站美女图片以及图片防盗链的解决方法
防盗链原理 http标准协议中有专门的字段记录referer 一来可以追溯上一个入站地址是什么 二来对于资源文件,可以跟踪到包含显示他的网页地址是什么 因此所有防盗链方法都是基于这个Referer字段 ...
- python爬取并批量下载图片
import requests from lxml import etree url='http://desk.zol.com.cn/meinv/' add1='.html' urls=[] i = ...
- Python爬取百度贴吧图片
一.获取URL Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据.首先,我们定义了一个getHtml()函数: urllib.urlopen()方 ...
随机推荐
- Thinkpad 小红点飘移的不完美解决办法
环境:T420 BIOS1.49 windows7 x64 对硬盘执行写入操作,比如说建立一个空白记事本,每次飘移的时候,就alt+tab切到记事本,随便输入一个字符,ctrl+s保存,搞定.
- CPU的概念
1.CPU的运算都是以纳秒为单位的,内存相比要慢百倍,硬盘要慢百万倍. 2.CPU的主要工作就是运行指令,指令全在内存里,第一条指令地址为0xFFFFFF0处(BIOS发出的跳转指令). 3.CPU工 ...
- 简单Hash函数LongHash
import java.security.SecureRandom; import java.util.Random; public class LongHash { private static l ...
- windows环境 springboot+docker开发环境搭建与hello word
1,下载安装 docker toolbox 下载地址:http://mirrors.aliyun.com/docker-toolbox/windows/docker-toolbox/ docker t ...
- jquery datatable测试部分代码(仅自用)
创建一个四列的datatable表,第四列为表格里的按钮设置,respond为JSON对象数组. $('#example').DataTable({ //每页显示十条数据 ...
- [转]AJAX POST请求中参数以form data和request payload形式在servlet中的获取方式
转载至 http://blog.csdn.net/mhmyqn/article/details/25561535 最近在写接收第三方的json数据, 因为对java不熟悉,有时候能通过request能 ...
- hive 一次更新多个分区的数据
类似订单数据之类的表,因为有状态要更新,比如订单状态,物流状态之类的, 这样就需要同步很久之前的数据,目前我的订单表是更新前面100天的数据. hive中操作是先删除前面100个分区的数据,然后重新动 ...
- c#经典三层框架中的SqlHelper帮助类
using System; using System.Collections.Generic; using System.Configuration; using System.Data; using ...
- AET 本征半导体
本征半导体就是纯净的半导体,不掺杂质的半导体 note:(1)本征半导体中载流子数目极少,其导电性能很差:(2)温度愈高,载流子数目越多,半导体的性能也就越好. 杂质半导体 对于4价半导体,可惨杂3价 ...
- spring boot 请求地址带有.json 兼容处理
项目以前时spring mvc的,现在升级为spring boot ,有些请求地址带有.json后缀,在请求spring boot项目时,无法匹配控制器,spring boot默认选择禁用后缀模式匹配 ...