关于python的中国历年城市天气信息爬取
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
关于python的中国城市天气网爬取
2.主题式网络爬虫爬取的内容与数据特征分析
爬取中国天气网各个城市每年各个月份的天气数据,
包括最高城市名,最低气温,天气状况等。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:通过正则表达式以及通过读取爬取数据的csv文件数据,并且变成可视化图。
技术难点:代码有问题,初期爬取的值不是城市,而只有省份,后来也不对,从城市开始后就是天气了,不行。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
爬取页面的天气信息,该页面是由table,tr,conmidtab,display和none,div来组成的中国天气网html页面程序代码。
2.Htmls页面解析
以下是中国天气网部分地区的HTML页面分析,可以发现,一个省份就是用一个table来进行装,选择各个table,就可以将里面的各个城市都选中,
又在各个table中用tr来装载各个城市的天气信息,前两个tr标签是表头,后面的tr标签才是信息,
q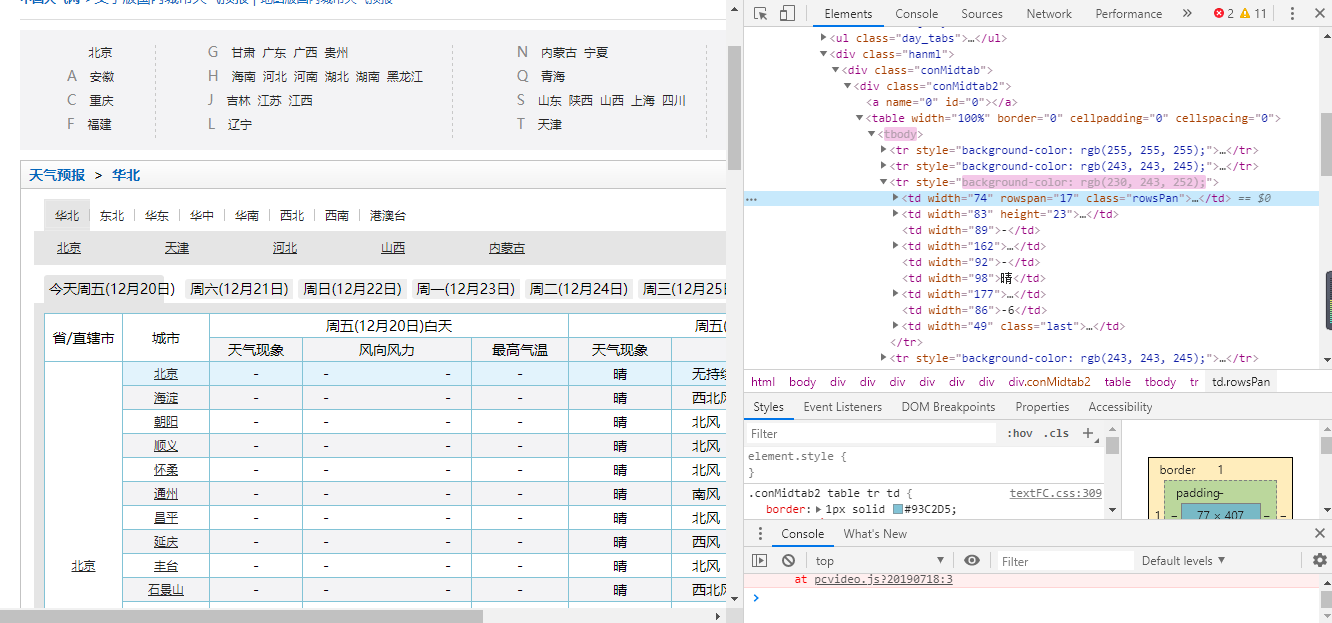
以及以下的’conMidtab包裹了该页面地区所有城市的信息段,将其展开,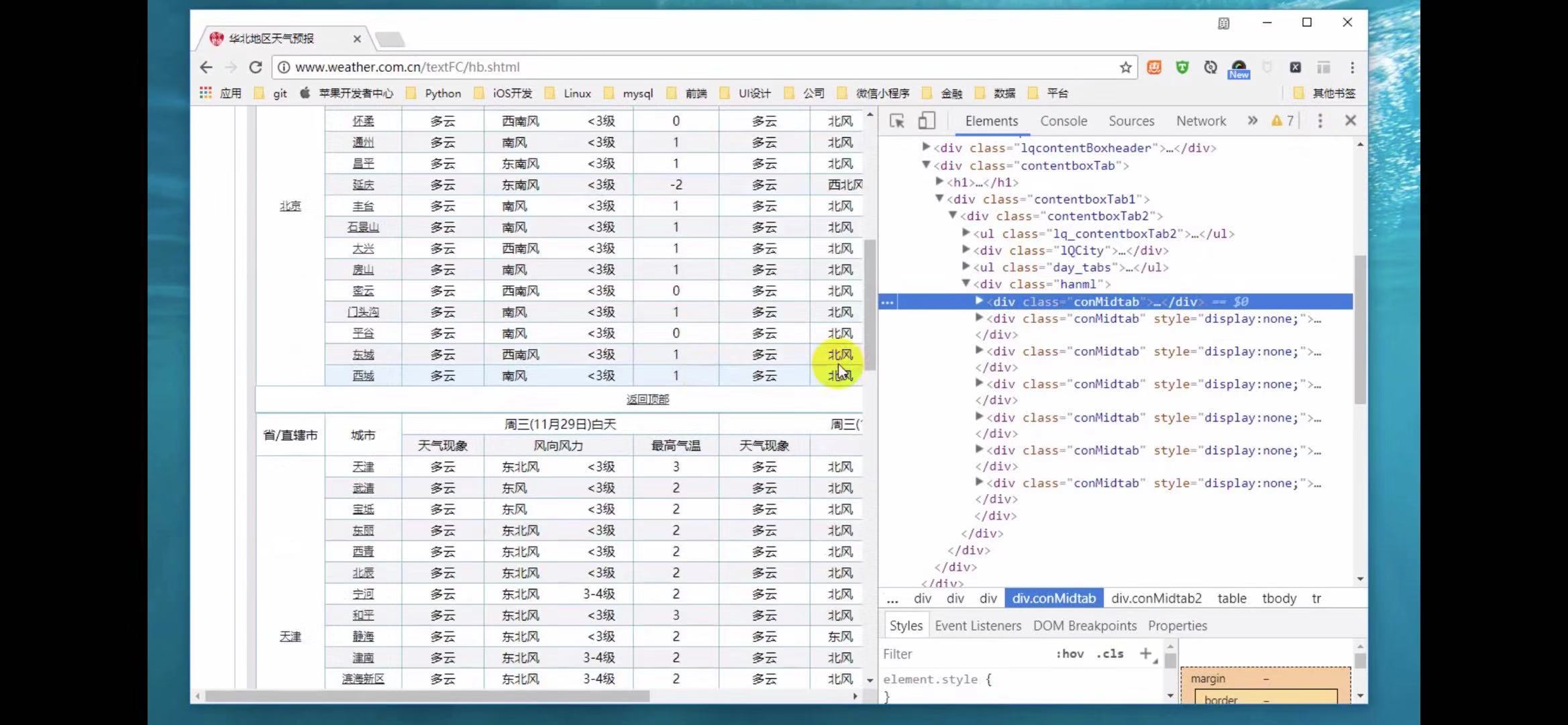
会在里面再找到一个table,里面也有一个conmidtab,但并没有在页面所显示出来,因为,里面有一个display和none将它隐藏了起来。可运用于想查询哪一天的天气信息,那就会把上一条的天气信息隐藏起来。
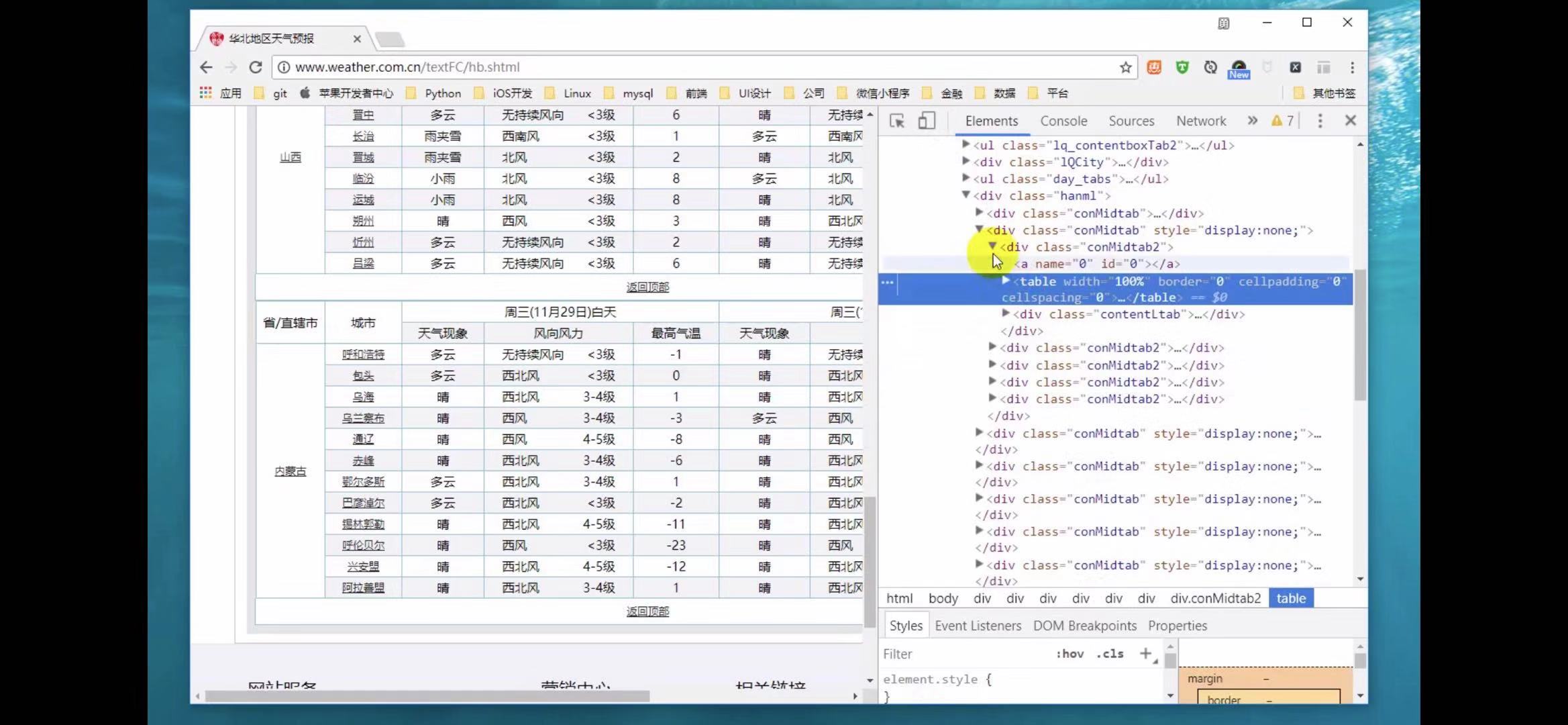
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
使用正则表达式,以及tr标签,div,table分装,来进行查找各个城市的天气信息。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
3.文本分析(可选):jieba分词、wordcloud可视化
5.数据持久化
6.附完整程序代码
1.数据爬取与采集
我们通过获取网页url来进行爬取
def get_one_page(url): #获取网页url 进行爬取
print('进行爬取'+url)
headers={'User-Agent':'User-Agent:Mozilla/5.0'} #头文件的user-agent
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.content
return None
except RequestException:
return None
2.对数据进行清洗和处理
def parse_one_page(html):#解析清理网页
soup = BeautifulSoup(html, "lxml")
info = soup.find('div', class_='wdetail')
rows=[]
tr_list = info.find_all('tr')[1:] # 使用从第二个tr开始取
for index, tr in enumerate(tr_list): # enumerate可以返回元素的位置及内容
td_list = tr.find_all('td')
date = td_list[0].text.strip().replace("\n", "") # 取每个标签的text信息,并使用replace()函数将换行符删除
weather = td_list[1].text.strip().replace("\n", "").split("/")[0].strip()
temperature_high = td_list[2].text.strip().replace("\n", "").split("/")[0].strip()
temperature_low = td_list[2].text.strip().replace("\n", "").split("/")[1].strip()
rows.append((date,weather,temperature_high,temperature_low))
return rows
3.文本分析(可选):jieba分词、wordcloud可视化
然后我们再选取我们想要的城市,所需年份,及月份,以及相关部分代码
cities = ['quanzhou',beijing','shanghai','tianjin','chongqing','akesu','anning','anqing',
'anshan','anshun','anyang','baicheng','baishan','baiyiin','bengbu','baoding',
'baoji','baoshan','bazhong','beihai','benxi','binzhou','bole','bozhou',
'cangzhou','changde','changji','changshu','changzhou','chaohu','chaoyang',
'chaozhou','chengde','chengdu','chenggu','chengzhou','chibi','chifeng','chishui',
'chizhou','chongzuo','chuxiong','chuzhou','cixi','conghua'] #获取城市名称来爬取选定城市天气
years = ['2011','2012','2013','2014','2015','2016','2017','2018']#爬取的年份
months = ['01','02','03','04','05','06', '07', '08','09','10','11','12']#爬取的月份
def get_one_page(url): #获取网页url 进行爬取
def parse_one_page(html):#解析清晰和处理网页
if __name__ == '__main__':#主函数
# os.chdir() # 设置工作路径
#读取CSV文件数据 filename='quanzhou_weather.csv'
current_date=datetime.strptime(row[0],'%Y-%m-%d') #将日期数据转换为datetime对象
soup = BeautifulSoup(html, "lxml") #使用lxml的方式进行解析
info = soup.find('div', class_='wdetail') #寻找到第一个div,以及它的class= wdetail
ate = td_list[0].text.strip().replace("\n", "") # 取每个标签的text信息,并使用replace()函数将换行符删除
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
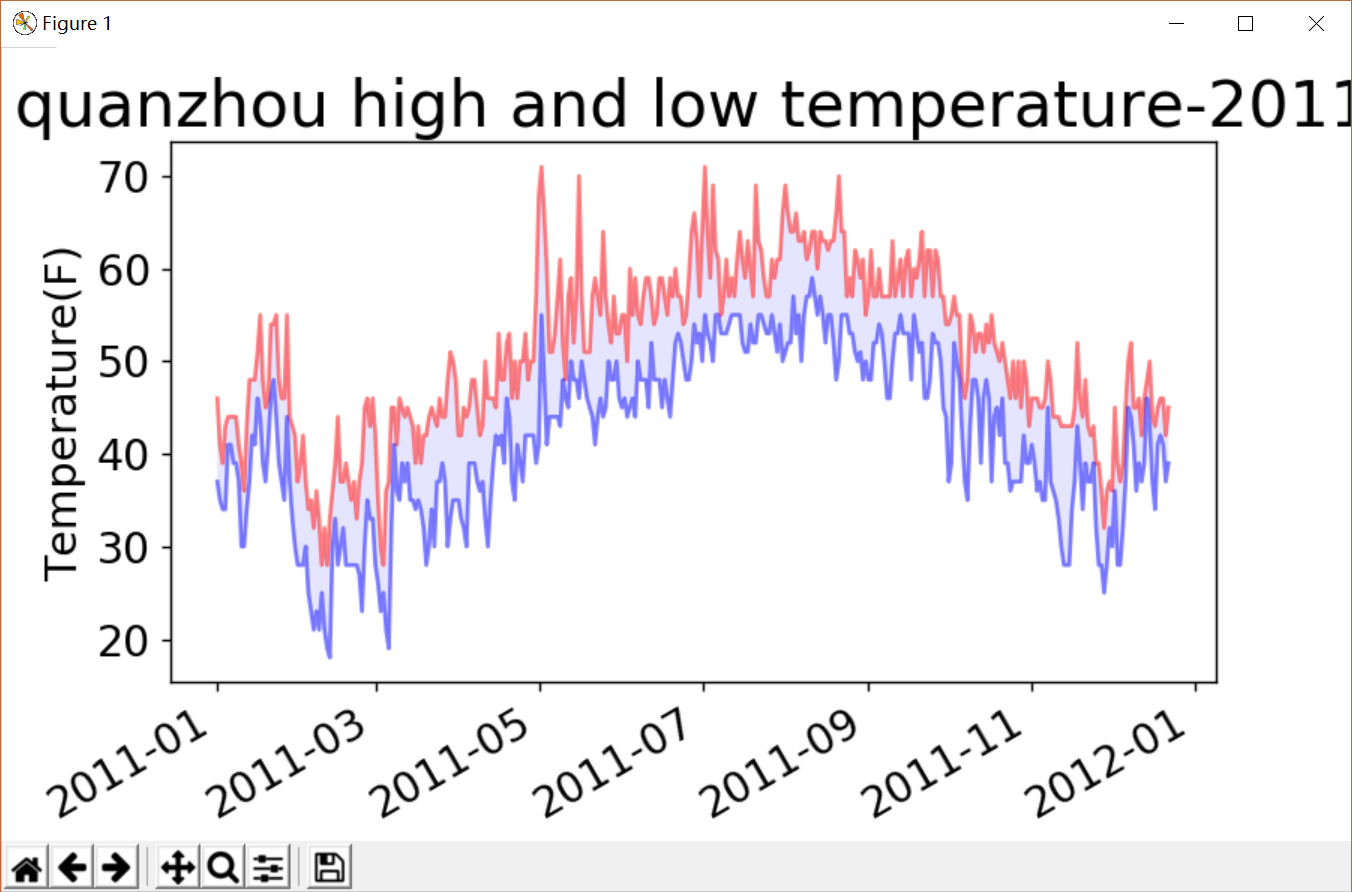
下图为爬取代表性城市泉州天气成功的效果图。

下图为代表城市泉州历年来各个月份每天的天气数据
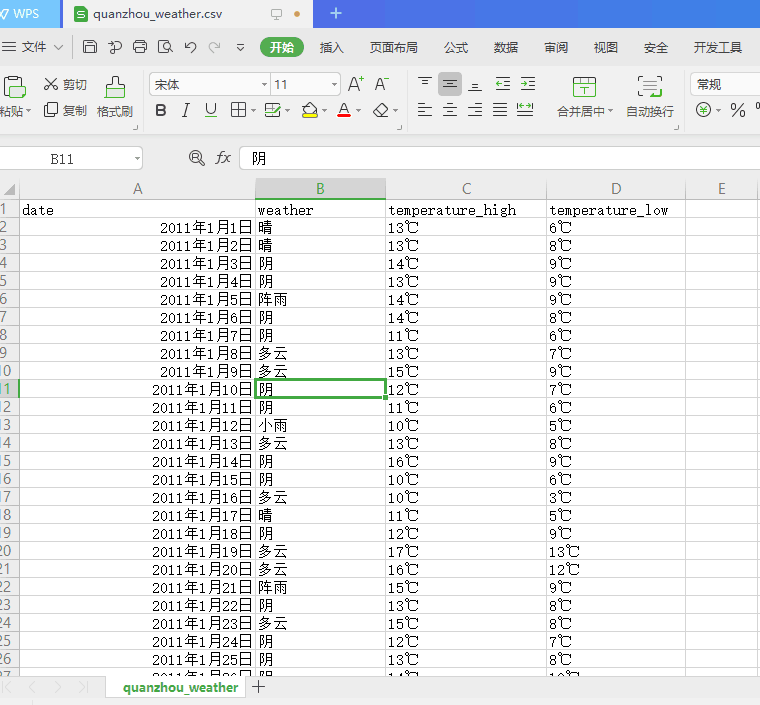
下图为爬取的代表性城市天气的可视化图,以及相关的代码分析。
import csv
from matplotlib import pyplot as plt
from datetime import datetime
#读取CSV文件数据
filename='quanzhou_weather.csv'
with open(filename) as f: #打开这个文件,并将结果文件对象存储在f中
reader=csv.reader(f) #创建一个阅读器reader
header_row=next(reader) #返回文件中的下一行
dates,highs,lows=[],[],[] #声明存储日期,最值的列表
for row in reader:
current_date=datetime.strptime(row[0],'%Y-%m-%d') #将日期数据转换为datetime对象
dates.append(current_date) #存储日期
high=int(row[1]) #将字符串转换为数字
highs.append(high) #存储温度最大值
low=int(row[3])
lows.append(low) #存储温度最小值
#根据数据绘制图形
fig=plt.figure(dpi=128,figsize=(10,6))
plt.plot(dates,highs,c='red',alpha=0.5)#实参alpha指定颜色的透明度,0表示完全透明,1(默认值)完全不透明
plt.plot(dates,lows,c='blue',alpha=0.5)
plt.fill_between(dates,highs,lows,facecolor='blue',alpha=0.1) #给图表区域填充颜色
plt.title('quanzhou high and low temperature-2011',fontsize=24)
plt.xlabel('',fontsize=16)
plt.ylabel('Temperature(F)',fontsize=16)
plt.tick_params(axis='both',which='major',labelsize=16)
fig.autofmt_xdate() #绘制斜的日期标签
plt.show()
5.数据持久化
6.附完整程序代码
爬取中国天气网各城市天气数据完整程序代码:
import requests
from requests.exceptions import RequestException #爬取异常函数
from bs4 import BeautifulSoup
import os #操作系统接口模块 用来写入爬出数据
import csv #爬出数据存为csv文件
import time def get_one_page(url): #获取网页url 进行爬取 print('进行爬取'+url)
headers={'User-Agent':'User-Agent:Mozilla/5.0'} #头文件的User-Agent
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.content
return None
except RequestException:
return None def parse_one_page(html):#解析清晰和处理网页 soup = BeautifulSoup(html, "lxml") #使用lxml的方式进行解析
info = soup.find('div', class_='wdetail') #寻找到第一个div,以及它的class= wdetail
rows=[]
tr_list = info.find_all('tr')[1:]
for index, tr in enumerate(tr_list): # enumerate可以返回元素的位置及内容
td_list = tr.find_all('td')
date = td_list[0].text.strip().replace("\n", "") # 取每个标签的text信息,并使用replace()函数将换行符删除
weather = td_list[1].text.strip().replace("\n", "").split("/")[0].strip()
temperature_high = td_list[2].text.strip().replace("\n", "").split("/")[0].strip()
temperature_low = td_list[2].text.strip().replace("\n", "").split("/")[1].strip() rows.append((date,weather,temperature_high,temperature_low))
return rows cities = ['quanzhou',beijing','shanghai','tianjin','chongqing','akesu','anning','anqing',
'anshan','anshun','anyang','baicheng','baishan','baiyiin','bengbu','baoding',
'baoji','baoshan','bazhong','beihai','benxi','binzhou','bole','bozhou',
'cangzhou','changde','changji','changshu','changzhou','chaohu','chaoyang',
'chaozhou','chengde','chengdu','chenggu','chengzhou','chibi','chifeng','chishui',
'chizhou','chongzuo','chuxiong','chuzhou','cixi','conghua',
'dali','dalian','dandong','danyang','daqing','datong','dazhou',
'deyang','dezhou','dongguan','dongyang','dongying','douyun','dunhua',
'eerduosi','enshi','fangchenggang','feicheng','fenghua','fushun','fuxin',
'fuyang','fuyang1','fuzhou','fuzhou1','ganyu','ganzhou','gaoming','gaoyou',
'geermu','gejiu','gongyi','guangan','guangyuan','guangzhou','gubaotou',
'guigang','guilin','guiyang','guyuan','haerbin','haicheng','haikou',
'haimen','haining','hami','handan','hangzhou','hebi','hefei','hengshui',
'hengyang','hetian','heyuan','heze','huadou','huaian','huainan','huanggang',
'huangshan','huangshi','huhehaote','huizhou','huludao','huzhou','jiamusi',
'jian','jiangdou','jiangmen','jiangyin','jiaonan','jiaozhou','jiaozou',
'jiashan','jiaxing','jiexiu','jilin','jimo','jinan','jincheng','jingdezhen',
'jinghong','jingjiang','jingmen','jingzhou','jinhua','jining1','jining',
'jinjiang','jintan','jinzhong','jinzhou','jishou','jiujiang','jiuquan','jixi',
'jiyuan','jurong','kaifeng','kaili','kaiping','kaiyuan','kashen','kelamayi',
'kuerle','kuitun','kunming','kunshan','laibin','laiwu','laixi','laizhou',
'langfang','lanzhou','lasa','leshan','lianyungang','liaocheng','liaoyang',
'liaoyuan','lijiang','linan','lincang','linfen','lingbao','linhe','linxia',
'linyi','lishui','liuan','liupanshui','liuzhou','liyang','longhai','longyan',
'loudi','luohe','luoyang','luxi','luzhou','lvliang','maanshan','maoming',
'meihekou','meishan','meizhou','mianxian','mianyang','mudanjiang','nanan',
'nanchang','nanchong','nanjing','nanning','nanping','nantong','nanyang',
'neijiang','ningbo','ningde','panjin','panzhihua','penglai','pingdingshan',
'pingdu','pinghu','pingliang','pingxiang','pulandian','puning','putian','puyang',
'qiannan','qidong','qingdao','qingyang','qingyuan','qingzhou','qinhuangdao',
'qinzhou','qionghai','qiqihaer','quanzhou','qujing','quzhou','rikaze','rizhao',
'rongcheng','rugao','ruian','rushan','sanmenxia','sanming','sanya','xiamen',
'foushan','shangluo','shangqiu','shangrao','shangyu','shantou','ankang','shaoguan',
'shaoxing','shaoyang','shenyang','shenzhen','shihezi','shijiazhuang','shilin',
'shishi','shiyan','shouguang','shuangyashan','shuozhou','shuyang','simao',
'siping','songyuan','suining','suizhou','suzhou','tacheng','taian','taicang',
'taixing','taiyuan','taizhou','taizhou1','tangshan','tengchong','tengzhou',
'tianmen','tianshui','tieling','tongchuan','tongliao','tongling','tonglu','tongren',
'tongxiang','tongzhou','tonghua','tulufan','weifang','weihai','weinan','wendeng',
'wenling','wenzhou','wuhai','wuhan','wuhu','wujiang','wulanhaote','wuwei','wuxi','wuzhou',
'xian','xiangcheng','xiangfan','xianggelila','xiangshan','xiangtan','xiangxiang',
'xianning','xiantao','xianyang','xichang','xingtai','xingyi','xining','xinxiang','xinyang',
'xinyu','xinzhou','suqian','suyu','suzhou1','xuancheng','xuchang','xuzhou','yaan','yanan',
'yanbian','yancheng','yangjiang','yangquan','yangzhou','yanji','tantai','yanzhou','yibin',
'yichang','yichun','yichun1','yili','yinchuan','yingkou','yulin1','yulin','yueyang','yongkang',
'yongzhou','yuxi','changchun','zaozhuang','zhangjiajie','zhangjiakou','changsha','changle',
'zhangzhou','zhuhai','zhengzhou','zunyi','fuqing','foshan'] #获取城市名称来爬取选定城市天气
years = ['2011','2012','2013','2014','2015','2016','2017','2018']#爬取的年份
months = ['01','02','03','04','05','06', '07', '08','09','10','11','12']#爬取的月份 if __name__ == '__main__':#主函数
# os.chdir() # 设置工作路径
for city in cities:
with open(city + '_weather.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(['date','weather','temperature_high','temperature_low'])
for year in years:
for month in months:
url = 'http://www.tianqihoubao.com/lishi/'+city+'/month/'+year+month+'.html'
html = get_one_page(url)
content=parse_one_page(html)
writer.writerows(content)
print(city+year+'年'+month+'月'+'数据爬取完毕!')
time.sleep(2)
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
爬取的代表性城市的数据很详细,精确到每一天的天气变化,以及通过可视化图可以知道,最高气温与最低气温相差大,昼夜温差大。
2.对本次程序设计任务完成的情况做一个简单的小结。
这段时间通过对爬取中国天气网数据的项目,得到了不少的收获,就比如说懂得了要先将爬出的数据存为CSV格式不然的话运行不出来,再然后获取该页面的url再进行爬取(其中还必须有头文件),先用tr进行爬取,以及enumerate可以返回元素的位置及内容,
关于python的中国历年城市天气信息爬取的更多相关文章
- 中国大学MOOC课程信息爬取与数据存储
版权声明:本文为博主原创文章,转载 请注明出处: https://blog.csdn.net/sc2079/article/details/82016583 10月18日更:MOOC课程信息D3.js ...
- Python 爬虫练手项目—酒店信息爬取
from bs4 import BeautifulSoup import requests import time import re url = 'http://search.qyer.com/ho ...
- 爬虫-通过本地IP地址从中国天气网爬取当前城市天气情况
1.问题描述 最近在做一个pyqt登录校园网的小项目,想在窗口的状态栏加上当天的天气情况,用爬虫可以很好的解决我的问题. 2.解决思路 考虑到所处位置的不同,需要先获取本地城市地址,然后作为中 ...
- [Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息 2018-07-21 23:53:02 larger5 阅读数 4123更多 分类专栏: 网络爬虫 版权声明: ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是 ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
随机推荐
- 【Git】Windows 配置 SSH-Key
查看本地公钥是否存在 执行以下语句来判断是否已经存在本地公钥 cat ~/.ssh/id_rsa.pub 如果出现如下截图,则本地公钥不存在,继续按步骤进行. 如果看到一长串以 ssh-rsa 或 s ...
- Linux 内存映射函数 mmap()函数详解
mmap将一个文件或者其它对象映射进内存.文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零.mmap在用户空间映射调用系统中作用很大.头文件 <sys/ ...
- 天天动听API
本次分析的是天天动听API,天天动听有一点比较好,就是搜索返回直接有歌曲播放的地址了,并且有无损的音频 搜索歌曲API:http://so.ard.iyyin.com/s/song_with_out? ...
- 《Java基础知识》序列化与反序列化详解
序列化的作用:为了不同jvm之间共享实例对象的一种解决方案.由java提供此机制. 序列化应用场景: 1. 分布式传递对象. 2. 网络传递对象. 3. tomcat关闭以后会把session对象序列 ...
- 用Python抢到回家的车票,so easy!
“ 盼望着,盼望着,春节的脚步近了,然而,每年到这个时候,最难的,莫过于一张回家的火车票. 据悉,今年春运期间,全国铁路发送旅客人次同比将增长 8.0%.达到 4.4 亿人次. 2020 年铁 ...
- 1、手写Unity容器--极致简陋版Unity容器
模拟Unity容器实例化AndroidPhone 思路: 1.注册类型:把类型完整名称作为key添加到数据字典中,类型添加到数据字典的value中 2.获取实例:根据完整类型名称也就是key取出val ...
- Sqlite—删除语句(Delete)
SQLite 的 DELETE 语句用于删除表中已有的记录.可以使用带有 WHERE 子句的 DELETE 查询来删除选定行,否则所有的记录都会被删除. SQLite 要清空表记录,只能使用Delet ...
- 对token机制的学习和分析
token,中文意思为令牌,是用户登录后会返回的一个字符串,里面包括用户信息.登录时间等,但是是加密过的密文,其加解密方式由后端决定. 在登录之后的接口请求中,前端需在请求中统一加上token,从而识 ...
- 1.编译spring源码
本文是作者原创,版权归作者所有.若要转载,请注明出处 下载spring源码,本文用的是版本如下: springframework 5.1.x, IDE工具idea 2019.2.3 JAVA ...
- Prometheus学习系列(五)之Prometheus 规则(rule)、模板配置说明
前言 本文来自Prometheus官网手册1.2.3.4和 Prometheus简介1.2.3.4 记录规则 一.配置规则 Prometheus支持两种类型的规则,这些规则可以定期配置,然后定期评估: ...