使用SGD(Stochastic Gradient Descent)进行大规模机器学习
原贴地址:http://fuliang.iteye.com/blog/1482002
其它参考资料:http://en.wikipedia.org/wiki/Stochastic_gradient_descent
1. 基于梯度下降的学习
对于一个简单的机器学习算法,每一个样本包含了一个(x,y)对,其中一个输入x和一个数值输出y。我们考虑损失函数 ,它描述了预测值
,它描述了预测值 和实际值y之间的损失。预测值是我们选择从一函数族F中选择一个以w为参数的函数
和实际值y之间的损失。预测值是我们选择从一函数族F中选择一个以w为参数的函数 的到的预测结果。
的到的预测结果。
我们的目标是寻找这样的函数 ,能够在训练集中最小化平均损失函数 :
,能够在训练集中最小化平均损失函数 : 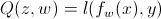
由于我们不知道数据的真实分布,所以我们通常使用 
来代替 
经验风险 用来衡量训练集合的效果。期望风险E(f)描述了泛化(generation)的效果,预测未知样例的能力。
用来衡量训练集合的效果。期望风险E(f)描述了泛化(generation)的效果,预测未知样例的能力。
如果函数族F进行足够的限制(sufficiently restrictive ),统计机器学习理论使用经验风险来代替期望风险。
1.1 梯度下降
我们经常使用梯度下降(GD)的方式来最小化期望风险,每一次迭代,基于 更新权重w:
更新权重w:  ,
, 为学习率,如果选择恰当,初始值选择合适,这个算法能够满足线性的收敛。也就是:
为学习率,如果选择恰当,初始值选择合适,这个算法能够满足线性的收敛。也就是: ,其中
,其中 表示残余误差(residual error)。
表示残余误差(residual error)。
基于二阶梯度的比较出名的算法是牛顿法,牛顿法可以达到二次函数的收敛。如果代价函数是二次的,矩阵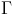 是确定的,那么这个算法可以一次迭代达到最优值。如果足够平滑的话,
是确定的,那么这个算法可以一次迭代达到最优值。如果足够平滑的话, 。但是计算需要计算偏导hession矩阵,对于高维,时间和空间消耗都是非常大的,所以通常采用近似的算法,来避免直接计算hession矩阵,比如BFGS,L-BFGS。
。但是计算需要计算偏导hession矩阵,对于高维,时间和空间消耗都是非常大的,所以通常采用近似的算法,来避免直接计算hession矩阵,比如BFGS,L-BFGS。
1.2 随机梯度下降
SGD是一个重要的简化,每一次迭代中,梯度的估计并不是精确的计算 ,而是基于随即选取的一个样例
,而是基于随即选取的一个样例 :
: 
随机过程
依赖于每次迭代时随即选择的样例,尽管这个简化的过程引入了一些噪音,但是我们希望他的表现能够和GD的方式一样。
随机算法不需要记录哪些样例已经在前面的迭代过程中被访问过,有时候随机梯度下降能够直接优化期望风险,因为样例可能是随机从真正的分布中选取的。
随机梯度算法的收敛性已经在随机近似算法的论文所讨论。收敛性要满足:  并且
并且
二阶随机梯度下降: 
这种方法并没有减少噪音,也不会对计算 有太大改进。
有太大改进。
1.3 随即梯度的一些例子
下面列了一些比较经典的机器学习算法的随机梯度, 
使用SGD(Stochastic Gradient Descent)进行大规模机器学习的更多相关文章
- 逻辑回归:使用SGD(Stochastic Gradient Descent)进行大规模机器学习
Mahout学习算法训练模型 mahout提供了许多分类算法,但许多被设计来处理非常大的数据集,因此可能会有点麻烦.另一方面,有些很容易上手,因为,虽然依然可扩展性,它们具有低开销小的数据集.这样一个 ...
- 机器学习-随机梯度下降(Stochastic gradient descent)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MINI-BATCH LEARNING. WHAT IS THE DIFFERENCE?
FITTING A MODEL VIA CLOSED-FORM EQUATIONS VS. GRADIENT DESCENT VS STOCHASTIC GRADIENT DESCENT VS MIN ...
- Stochastic Gradient Descent
一.从Multinomial Logistic模型说起 1.Multinomial Logistic 令为维输入向量; 为输出label;(一共k类); 为模型参数向量: Multinomial Lo ...
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- 基于baseline和stochastic gradient descent的个性化推荐系统
文章主要介绍的是koren 08年发的论文[1], 2.1 部分内容(其余部分会陆续补充上来). koren论文中用到netflix 数据集, 过于大, 在普通的pc机上运行时间很长很长.考虑到写文 ...
- Stochastic Gradient Descent 随机梯度下降法-R实现
随机梯度下降法 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. 批量梯度下降法在权值更新前对所有样本汇总 ...
- Stochastic Gradient Descent收敛判断及收敛速度的控制
要判断Stochastic Gradient Descent是否收敛,可以像Batch Gradient Descent一样打印出iteration的次数和Cost的函数关系图,然后判断曲线是否呈现下 ...
- 基于baseline、svd和stochastic gradient descent的个性化推荐系统
文章主要介绍的是koren 08年发的论文[1], 2.3部分内容(其余部分会陆续补充上来).koren论文中用到netflix 数据集, 过于大, 在普通的pc机上运行时间很长很长.考虑到写文章目 ...
随机推荐
- phpstorm 输入法中文不同步 phpstorm 输入法不跟随光标解决办法
win7系统新安装的phpstorm2017.2版本,试了很多输入法,要么是不显示候选次,要么是输入法候选词总是在屏幕右下角,没有跟随光标移动.百度很久,重要找到解决方案. 就是替换phpstorm安 ...
- php 二维数组去重
function remove_duplicate($array){ $result=array(); foreach ($array as $key => $value) { $has = f ...
- 美团针对Redis Rehash机制的探索和实践
背景 Squirrel(松鼠)是美团技术团队基于Redis Cluster打造的缓存系统.经过不断的迭代研发,目前已形成一整套自动化运维体系,涵盖一键运维集群.细粒度的监控.支持自动扩缩容以及热点Ke ...
- C++ 几种经典的垃圾回收算法
之前遇到了一篇好文(https://blog.csdn.net/wallwind/article/details/6889917)准备学习一下的,课程繁忙就忘记了,今日得闲,特来补一下. 自己写一遍加 ...
- js包
1.base.js /*语法: $("选择器") 工厂函数 */ /*寻找页面中name属性值是haha的元素*/ $("[name='haha']&qu ...
- sklearn六大板块
六大板块 分类 回归 聚类 数据降维 数据预处理 特征抽取 统一API estimator.fit(X_train,[y_train]) estimator.fit(X_train,[y_train] ...
- [BZOJ5125]小Q的书架(决策单调性+分治DP+树状数组)
显然有决策单调性,但由于逆序对不容易计算,考虑分治DP. solve(k,x,y,l,r)表示当前需要选k段,待更新的位置为[l,r],这些位置的可能决策点区间为[x,y].暴力计算出(l+r)/2的 ...
- [SPOJ-BEADS]Glass Beads
来源: CE1998 题目大意: 求字符串最小表示. 思路: 字符串复制一遍接在后面,构建SAM,然后每次跑小的转移. 跑n次以后就跑到了最小表示的末尾,用该状态的len值减去n就是最小表示的起始位置 ...
- 【10.5校内测试】【DP】【概率】
转移都很明显的一道DP题.按照不优化的思路,定义状态$dp[i][j][0/1]$表示吃到第$i$天,当前胃容量为$j$,前一天吃(1)或不吃(0)时能够得到的最大价值. 因为有一个两天不吃可以复原容 ...
- Vuex了解
State Vuex是用来管理某个应用的整个状态,那么一个应用只能有一个Vuex实例.和React一样,Vuex也不允许直接去修改state,而是通过提交mutation,来触发状态变更.Vuex的状 ...