Hadoop之集群搭建
准备
- 需要准备多台主机(已经安装并且配置好hadoop和jdk)
- 需要配置ssh免密服务
下面我们开始进行配置,拿到已经准备好的主机,主机名分别为:
- centos101
- centos102
- centos103
先说下为什么需要进行ssh免密码配置:
我们在操作集群时,经常需要在各台主机上进行数据传输、主机切换等工作,如果直接进行切换等操作需要每次输入密码,当操作频繁
时,就显得很复杂,所以需要配置ssh免密码,让主机间自动检验账号密码。
主机间进行ssh通信的原理图
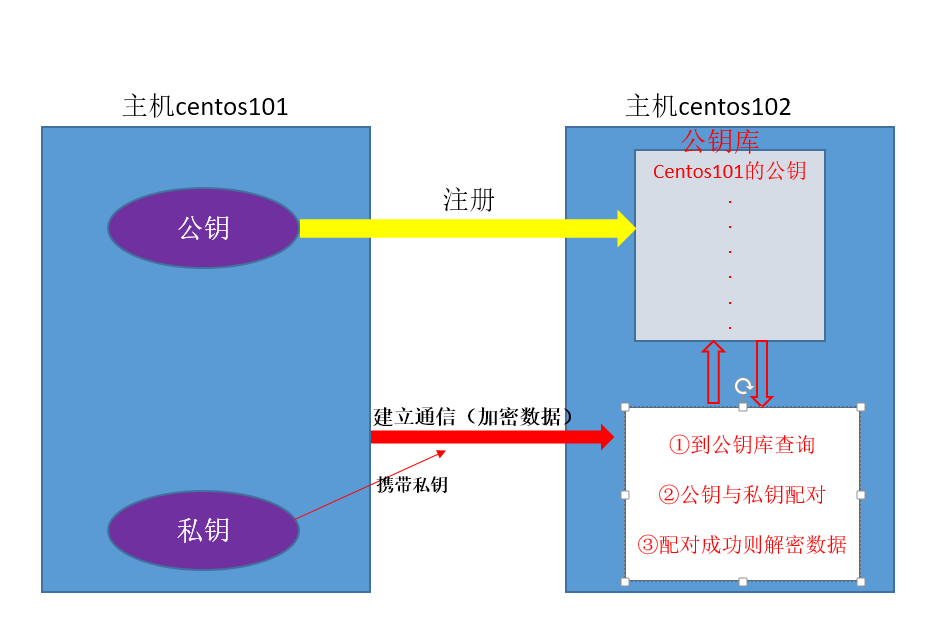
配置ssh免密
①在主机centos101上访问其它主机,保证有访问记录,访问记录存在 /home/ljm/.ssh下的known_hosts文件中
用命令:ssh 主机 访问过的记录都在该文件中
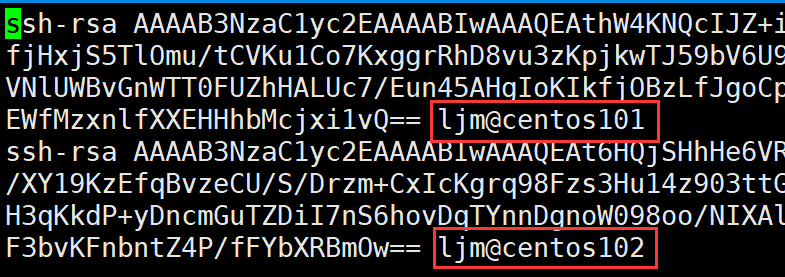
②生成密钥,产生本台主机的公钥和私钥
命令:ssh-keygen -t rsa , 一直回车 生成了三个新文件
- authorized_keys:保存已经注册过的主机(即把公钥备份到本机的其它主机)
- id_rsa :私钥
- id_rsa.pub : 公钥

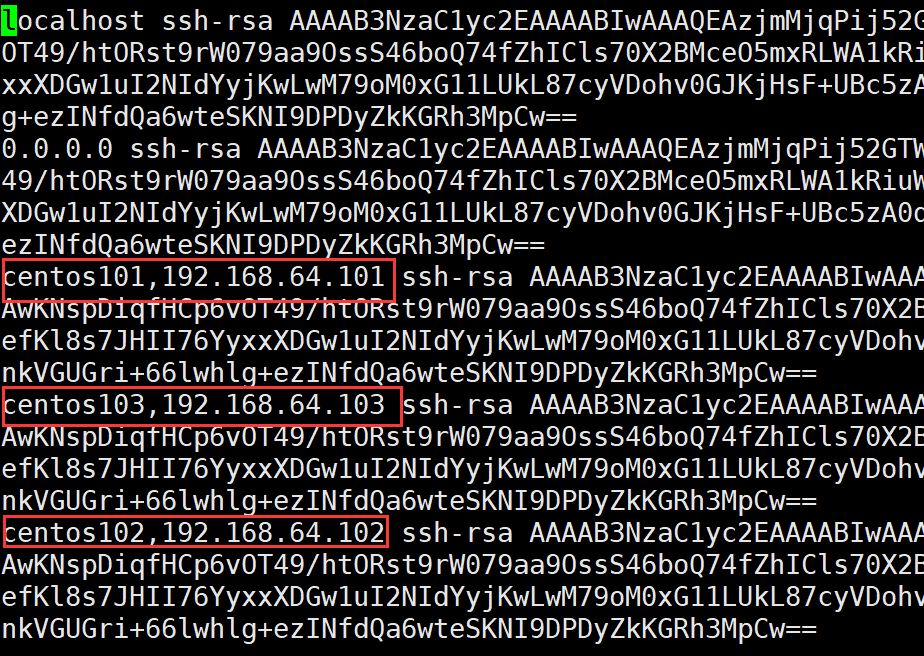
③将公钥复制到其它主机,复制时按照known_hosts中访问记录进行自动复制,复制后保存在其他主机的authorized_keys文件中
命令: ssh-copy-id 主机
以下是centos103主机的authorized_keys文件,可以看出centos101和centos102对它注册过
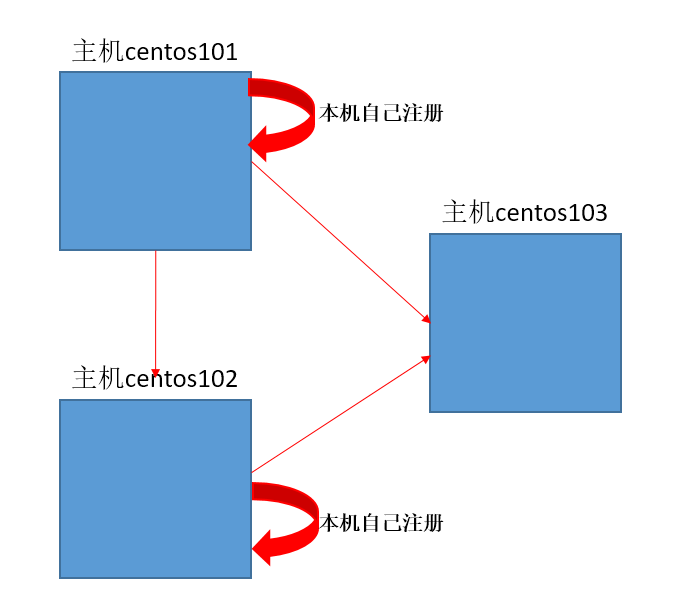
到这里已经完成了centos101对centos102和cenot103的免密配置了
注意:
①本主机也要对本主机注册,简单说,就是哪里需要免密就配置到哪里
②同一台主机上的不同用户配置不同(如user用户配置了ssh免密,root用户并没有权利使用它的配置)
③两台主机间只要一方往另一方配置了,双方便可以相互免密访问
我三台主机的ssh配置结构如下:
配置hadoop集群
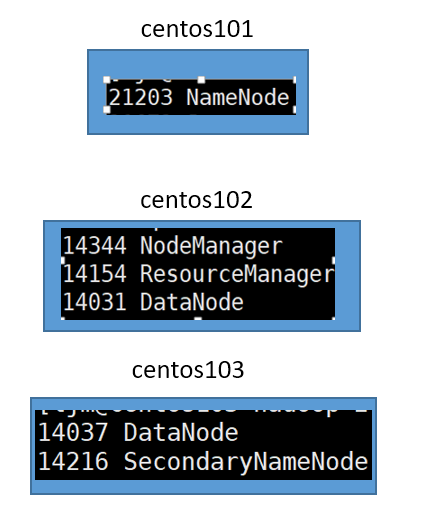
我的集群结构图:
基本配置文件(这些配置在hadoop根目录/etc/hadoop下):
- core-site.xml配置
- HDFS配置(hadoop-env.sh hdfs-site.xml slaves)
- YARN配置 (yarn-env.sh yarn-site.xml)
- MapReduce配置(mapred-env.sh mapred-site.xml)
①配置core-site.xml
每台主机都需要配置该文件,内容如下:
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://centos101:8020</value>
</property> <!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value> //缓存目录
</property>
</configuration>
②HDFS配置
每台主机都配置 hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_131 //jdk路径
只有主机centos101配置hdfs-site.xml,其它主机清空<configuration></configuration>中内容
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>centos103:50090</value>
</property>
</configuration>
只有主机centos101配置slaves,该文件默认localhost,centos101中slaves指定生成子节点datanode的主机
注意:格式要求严格,有空格都会导致出错
centos102
centos103
③YARN配置
每台主机都配置 yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_131 //jdk路径
只有主机centos101配置yarn-site.xml,其它主机清空<configuration></configuration>中内容
注意:yarn.resourcemanager.hostname指的是生成resourcemanager的节点主机,启动resourcemanager时必须在指定的主机启动
例如下面的配置,只能在主机centos102上启动resourcemanager
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centos102</value>
</property>
</configuration>
④MapReduce的配置
每台主机都配置 mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_131 //jdk路径
只有主机centos101配置mapred-site.xml,其它主机清空<configuration></configuration>中内容
注意:mapred-site.xml并没有,需要将mapred-site-template.xml改为mapred-site.xml再进行配置
<!--指定mr运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
到这里,一个简单的集群已经配置好了,下面去启动集群吧!
启动集群
①将每台主机上的缓存文件夹和logs文件删除,我的配置中为 : /opt/module/hadoop-2.7.2/data/tmp
②初始化主节点centos101,命令:bin/hdfs namenode -format
③主节点上开启HDFS 命令:sbin/start-dfs.sh
④在指定生成resourcemanager的节点主机上,开启YARN 命令: sbin/start-yarn.sh
⑤用jps到每台主机上查看是否启动成功
Hadoop之集群搭建的更多相关文章
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- Hadoop+HBase 集群搭建
Hadoop+HBase 集群搭建 1. 环境准备 说明:本次集群搭建使用系统版本Centos 7.5 ,软件版本 V3.1.1. 1.1 配置说明 本次集群搭建共三台机器,具体说明下: 主机名 IP ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- hadoop ha集群搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 zookeeper-3.4.8 linux系统环境:Centos6.5 3台主机:master.slave01.slave02 Hado ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- hadoop分布式集群搭建(2.9.1)
1.环境 操作系统:ubuntu16 jdk:1.8 hadoop:2.9.1 机器:3台,master:192.168.199.88,node1:192.168.199.89,node2:192.1 ...
- Hadoop分布式集群搭建_1
Hadoop是一个开源的分布式系统框架 一.集群准备 1. 三台虚拟机,操作系统Centos7,三台主机名分别为k1,k2,k3,NAT模式 2.节点分布 k1: NameNode DataNode ...
- hadoop分布式集群搭建前期准备(centos7)
那玩大数据,想做个大数据的从业者,必须了解在生产环境下搭建集群哇?由于hadoop是apache上的开源项目,所以版本有些混乱,听说都在用Cloudera的cdh5来弄?后续研究这个吧,就算这样搭建不 ...
- hadoop+spark集群搭建
1.选取三台服务器(CentOS系统64位) 114.55.246.88 主节点 114.55.246.77 从节点 114.55.246.93 从节点 之后的操作如果是用普通用户操作的话也必须知道r ...
- hadoop+eclipse集群搭建及测试
前段时间搭了下hadoop,每次都会碰到很多问题,也没整理过,每次搜索都麻烦,现在整理下 一.准备工作 1.准备俩计算机,安装linux系统,分别装好jdk(虚拟机操作一样) nano /etc/ho ...
随机推荐
- springboot(十九)-线程池的使用
我们常用ThreadPoolExecutor提供的线程池服务,springboot框架提供了@Async注解,帮助我们更方便的将业务逻辑提交到线程池中异步执行. 话不多说,编码开始: 1.创建spri ...
- Hadoop伪分布式重启正确流程
既然是伪分布式,那就不可避免的设计到重启Hadoop服务或者重启Hadoop服务器的情况,正确的停止和重启是很有必要的. 首先是Hadoop服务的停止,使用 ./sbin/stop-all.sh脚本来 ...
- java笔记web
1,spring请求同,返回同一个界面 Dubbo消费者无法连接到生产者提供的服务?内网IP? https://blog.csdn.net/xlgen157387/article/details/52 ...
- 腾讯地图JSAPI开发demo 定位,查询
1.IP定位切换 2.点击坐标获取地点 3.查询地点切换坐标 <!DOCTYPE html> <html> <head> <meta http-equiv=& ...
- Delphi 适合于文本文件的基本操作
- Delphi ScrollBar组件
- Qualcomm_Mobile_OpenCL.pdf 翻译-1
1 前言 1.1 目的 这篇文档的主要目的是,向原始设备制造商(OEMs),独立软件供应商(ISVs),第三方开发者们,提供在基于高通骁龙400系列.600系列,和800系列的手机平台和芯片上进行开发 ...
- 构建一个highcharts
示例:http://www.helloweba.com/demo/highcharts/line.html <!doctype html> <html lang="en&q ...
- chown -R lyd usbsend
chown -R lyd usbsend chown -R lyd usbsend chown -R lyd usbsend 某一个目录下所有文件授权给lyd
- glViewport函数用法
一. 其函数原型为glViewport(GLint x,GLint y,GLsizei width,GLsizei height) x,y 以像素为单位,指定了窗口的左下角位置. width,heig ...