大数据笔记(二十)——NoSQL数据库之MemCached
一、为什么要把数据存入内存?
1、原因:快
2、常见的内存数据库
(*)MemCached:看成Redis的前身,严格来说Memcached的不能叫数据库,原因:不支持持久化
(*)Redis:内存数据库,持久化(RDB、AOF)
(*)Oracle TimesTen
(*)SAP HANA
二、MemCached缓存技术
1、基本原理和体系结构
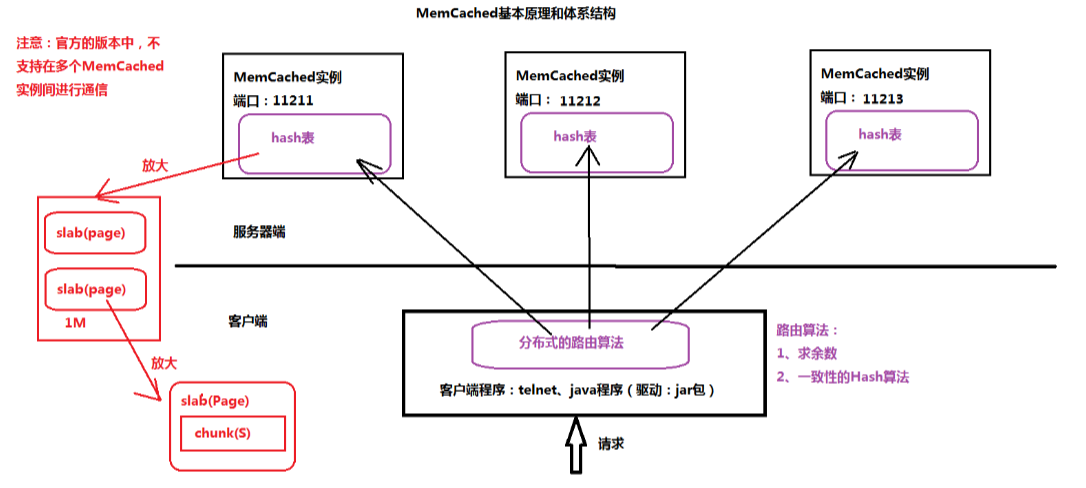
(*) 就是在内存中,维护一张巨大的Hash表
(*) MemCached通过一个路由算法(由客户端决定),来决定数据保存到哪一个节点上
2、安装和配置
(*) 前提1:安装gcc的编译器
(*) 前提2:安装libevent
(1) 确定、删除自带的libevent
rpm -qa|grep libevent =-==> 确定是否已有
rpm -e libevent-2.0.21-4.el7.x86_64 --nodeps (不要删除相关的依赖)
(2) tar -zxvf libevent-2.0.21-stable.tar.gz
(3) 安装到: /root/training/libevent
./configure --prefix=/root/training/libevent
make
make install
(*) 安装MemCached: 官方的版本:memcached-1.4.25.tar.gz
tar -zxvf memcached-1.4.25.tar.gz
安装目录:/root/training/memcached
配置:./configure --prefix=/root/training/memcached --with-libevent=/root/training/libevent
make
make install
(*) 启动:./memcached -u root -d -m 128 -p 11211
./memcached -u root -d -m 128 -p 11212
./memcached -u root -d -m 128 -p 11213(training/me../bin目录)
3、操作MemCached
(1)命令行:telnet (如果mnt下面没有东西,则重新挂载一下光盘)
(*) 安装telnet:rpm -ivh telnet-0.17-64.el7.x86_64.rpm
(*) telnet 127.0.0.1 11211
(*) 插入数据: add/set
set: 如果key已经存在,会替换原来的值
add: 如果key已经存在,返回信息(错误): NOT_STROED
举例:add key1 0 0 4
key1: key-value的键
第一个0:标志位
第二个0:数据过期的时间,0表示永远不过期
4表示:数据的长度
统计信息的命令:
stats
stats items
stats slabs
(2)JAVA API
4、MemCached路由算法
由客户端来决定
(1)求余数路由算法
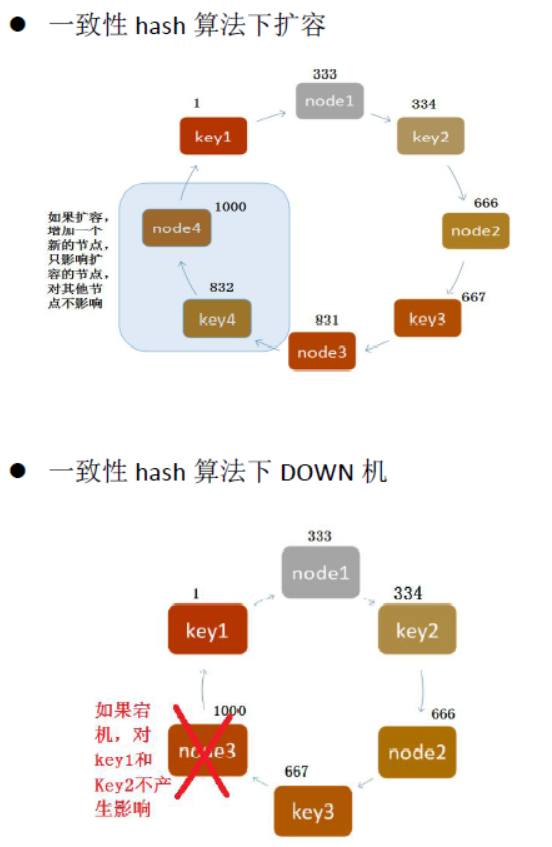
缺点:如果需要扩容或者有宕机的情况,会造成数据的丢失。
举例: 扩容
3台MemCached ----> 4台MemCached
key
1 1 1
2 2 2
3 0 3
4 1 0
5 2 1
6 0 2
7 1 3
8 2 0
9 0 1
10 1 2
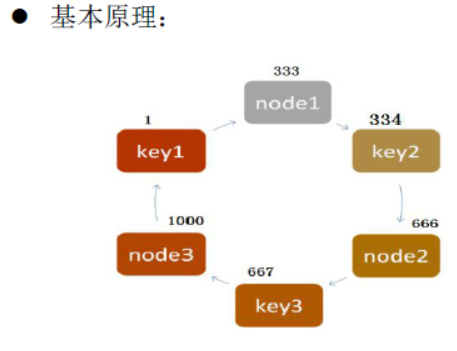
(2)一致性的hash算法
5、MemCached主主复制功能(双机热备)
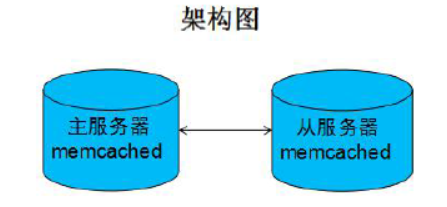
(1)不能使用官方的版本
一个日本的工程师改写了官方的版本,支持主主复制功能
memcached-1.2.8-repcached-2.2.tar.gz
(2)准备两台:bigdata11 bigdata12
(*) tar -zxvf memcached-1.2.8-repcached-2.2.tar.gz
(*) ./configure --prefix=/root/training/memcached_replication --with-libevent=/root/training/libevent --enable-replication
make
错误:error: ‘IOV_MAX’ undeclared (first use in this function)
vi memcached.c
55 /* FreeBSD 4.x doesn't have IOV_MAX exposed. */
56 #ifndef IOV_MAX
57 //#if defined(__FreeBSD__) || defined(__APPLE__)
58 # define IOV_MAX 1024
59 //#endif
60 #endif
make install
(3) 启动:需要指定对端的Memcached地址: -x参数
bigdata11: ./memcached -d -u root -m 128 -x bigdata12(/root/training/memcached_replication/bin)
bigdata12: ./memcached -d -u root -m 128 -x bigdata11
错误:
./memcached: error while loading shared libraries: libevent-2.0.so.5: cannot open shared object file:
No such file or directory
判断:命令memcached依赖的库有哪些?
ldd memcached
linux-vdso.so.1 => (0x00007ffee936b000)
libevent-2.0.so.5 => not found
libc.so.6 => /lib64/libc.so.6 (0x00007fc26923e000)
/lib64/ld-linux-x86-64.so.2 (0x00005579c379b000)
创建一个连接,让系统的libevent-2.0.so.5 指向我们自己的libevent-2.0.so.5
(64位系统) ln -s /root/training/libevent/lib/libevent-2.0.so.5 /usr/lib64/libevent-2.0.so.5
(32位系统) ln -s /root/training/libevent/lib/libevent-2.0.so.5 /usr/lib/libevent-2.0.so.5
telnet退出: ctrl + ]
如果没有telnet 重新挂载一下光盘: mount /dev/cdrom /mnt,去Package目录下执行:rpm -ivh telnet-0.17-64.el7.x86_64.rpm
大数据笔记(二十)——NoSQL数据库之MemCached的更多相关文章
- 大数据笔记(十二)——使用MRUnit进行单元测试
package demo.wc; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.IntW ...
- 大数据笔记(十五)——Hive的体系结构与安装配置、数据模型
一.常见的数据分析引擎 Hive:Hive是一个翻译器,一个基于Hadoop之上的数据仓库,把SQL语句翻译成一个 MapReduce程序.可以看成是Hive到MapReduce的映射器. Hive ...
- 大数据笔记(十)——Shuffle与MapReduce编程案例(A)
一.什么是Shuffle yarn-site.xml文件配置的时候有这个参数:yarn.nodemanage.aux-services:mapreduce_shuffle 因为mapreduce程序运 ...
- 大数据笔记(十九)——数据采集引擎Sqoop和Flume安装测试详解
一.Sqoop数据采集引擎 采集关系型数据库中的数据 用在离线计算的应用中 强调:批量 (1)数据交换引擎: RDBMS <---> Sqoop <---> HDFS.HBas ...
- 大数据笔记(十八)——Pig的自定义函数
Pig的自定义函数有三种: 1.自定义过滤函数:相当于where条件 2.自定义运算函数: 3.自定义加载函数:使用load语句加载数据,生成一个bag 默认:一行解析成一个Tuple 需要MR的ja ...
- 大数据笔记(十六)——Hive的客户端及自定义函数
一.Hive的Java客户端 JDBC工具类:JDBCUtils.java package demo.jdbc; import java.sql.DriverManager; import java. ...
- 大数据笔记(十四)——HBase的过滤器与Mapreduce
一. HBase过滤器 1.列值过滤器 2.列名前缀过滤器 3.多个列名前缀过滤器 4.行键过滤器5.组合过滤器 package demo; import javax.swing.RowFilter; ...
- python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法
python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法window安装redis,下载Redis的压缩包https://git ...
- Linux实战教学笔记44:NoSQL数据库开篇之应用指南
第1章 NoSQL数据库 1.1 NoSQL概述 自关系型数据库诞生40年以来,从理论产生发展到现实产品,例如:大家最常见的MySQL和Oracle,逐渐在数据库领域里上升到了霸主地位,形成每年高达数 ...
- 大数据量高并发的数据库优化详解(MSSQL)
转载自:http://www.jb51.net/article/71041.htm 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能. ...
随机推荐
- 使用 PC 做 FTP/TFTP 服务器,上传和下载文件
使用PC做TFTP服务器,上传和下载文件需要用到一个工具软件,IPOP,可百度下载. 1.在桌面新建一个空闲的文件夹,作为TFTP服务器的存储位置,然后打开IPOP软件,开启服务. 图片中 编号3 的 ...
- [Vim] 02 用 Windows 下的 gVim 假装 Linux 下的 Vim
0. 前言 这应该是极简配置,"极简"就是字面意思 我安装的版本是 8.1.1 来看个素颜 1. 找到 _vimrc 文本 我装在 E:\Program Files (x86)\V ...
- [BZOJ 3771] Triple(FFT+容斥原理+生成函数)
[BZOJ 3771] Triple(FFT+生成函数) 题面 给出 n个物品,价值为别为\(w_i\)且各不相同,现在可以取1个.2个或3个,问每种价值和有几种情况? 分析 这种计数问题容易想到生成 ...
- spring服务器接收参数格式
注:@RequestParam 或@RequestBody等注解是否添加有什么区别 不加:参数可有可无,无参数时为null,但当参数类型是 数字基本类型(int.double)时会报错: 加上@Req ...
- lilo.conf - lilo 配置文件
描述 默认情况下,本文件 ( /etc/lilo.conf ) 由引导管理程序 lilo 读取 (参考 lilo(8)). 它看起来可能象这样: boot = /dev/hda delay = 40 ...
- 负载均衡的3种模型(httpd+lvs几十万并发的负载均衡搭建)
一.几种常见的负载均衡模型 二.搭建httpd+lvs LVS .node01 启动一块eth0:2的网卡子接口(ifconfig eth0: down可以把网卡down掉) ifconfig eth ...
- Qt的QSettings类和.ini文件读写
Detailed Description QSettings类提供了持久的跨平台的应用程序设置.用户通常期望应用程序记住它的设置(窗口大小.位置等)所有会话.这些信息通常存储在Windows系统注册表 ...
- java ThreadGroup源码分析
使用: import javax.swing.text.html.HTMLDocument.HTMLReader.IsindexAction; public class Test { public s ...
- 在 LaTeX 中同步缩放 TikZ 与其中的 node
PGF/TikZ 是 Till Tantau 开发的基于 TeX 的绘图引擎.因其可以直接在 LaTeX 文稿中通过代码绘制向量图,所以是目前流行的 LaTeX 绘图解决方案之一. 在 tikzpic ...
- sharepoint 2010 创建自定义的ASP.NET Web Service (上)
项目背景 根据客户需求在SharePoint 2010 中创建自定义的ASP.NET Web Service可以分为3种方式(我所知道的).废话少说,下面一一列举: 创建方式 MSDN 官方博客自己的 ...