sklearn中的pipeline的创建与访问
前期博文提到管道(pipeline)在机器学习实践中的重要性以及必要性,本文则递进一步,探讨实际操作中管道的创建与访问。
已经了解到,管道本质上是一定数量的估计器连接而成的数据处理流,所以成功创建管道的唯一要求就是:管道中所有估计器必须具有fit()和transform()方法,但管道中最后一个估计器只需具有fit()方法足矣;
这个约束条件的目的是保证,管道中后一个估计器能够接受前一个估计器的transform输出。
pipeline创建
创建管道一般有两种途径:
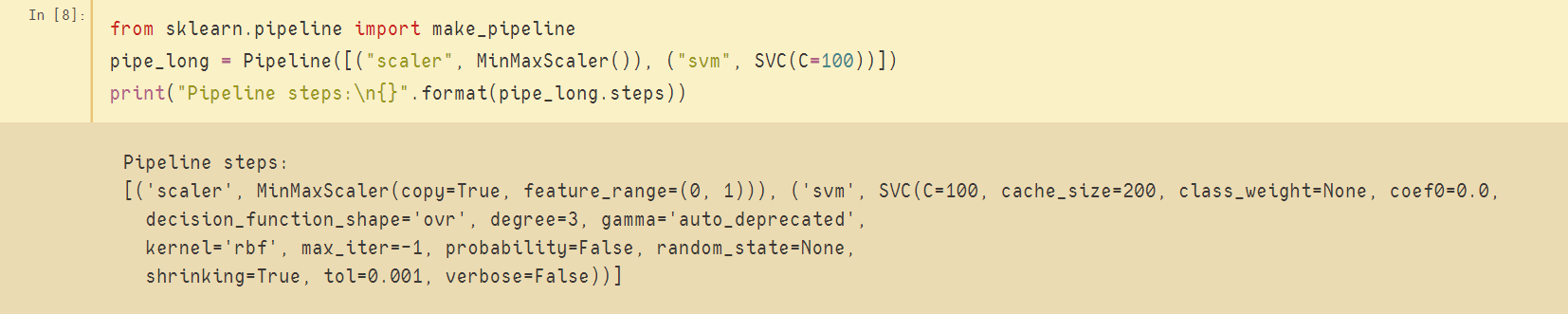
如上图,利用Pipeline创建两个估计器构成的管道,并且指明每个步骤的名称;利用pipe_long.steps()方法可以得到管道的每个估计器的细节信息。

对比这两个创建方法,可以发现不指定处理步骤名称时,系统会自动给估计器命名(见图中圆圈部分)。
访问pipeline中估计器信息
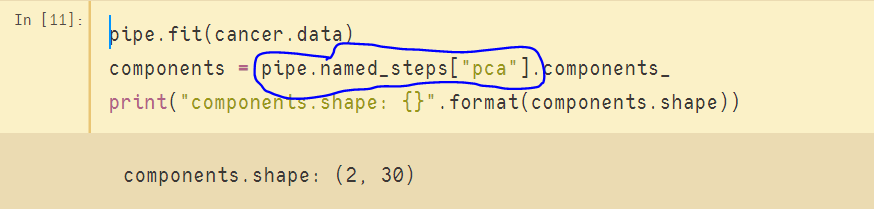
如下图所示,圆圈部分利用管道的named_steps属性和特定估计器的名称指定访问目标,而后访问目标的components_信息。
下面是一个较为完整的实例:
第一步,先创建由数据标准化函数和逻辑回归分类器构成的管道,并在网格搜索的框架下进行训练数据的拟合:

第二步:类似地,利用管道的named_steps属性指定逻辑回归估计器的步骤名称,得到估计器的大体信息和系数属性。

实际上,管道机制与网格搜索的结合可以完成许多有意思的工作,这一部分内容见后期博文。
sklearn中的pipeline的创建与访问的更多相关文章
- sklearn中的pipeline实际应用
前面提到,应用sklearn中的pipeline机制的高效性:本文重点讨论pipeline与网格搜索在机器学习实践中的结合运用: 结合管道和网格搜索以调整预处理步骤以及模型参数 一般地,sklearn ...
- sklearn中的Pipeline
在将sklearn中的模型持久化时,使用sklearn.pipeline.Pipeline(steps, memory=None)将各个步骤串联起来可以很方便地保存模型. 例如,首先对数据进行了PCA ...
- sklearn 中的 Pipeline 机制 和FeatureUnion
一.pipeline的用法 pipeline可以用于把多个estimators级联成一个estimator,这么 做的原因是考虑了数据处理过程中一系列前后相继的固定流程,比如feature selec ...
- sklearn 中的 Pipeline 机制
转载自:https://blog.csdn.net/lanchunhui/article/details/50521648 from sklearn.pipeline import Pipeline ...
- JSON ------ 创建与访问
JSON (Java Script Object Notation, js对象表示法) 是存储和交换文本信息的语法,类似 XML JSON的文件类型是 “.json” 优点: 比XML ...
- 【笔记】多项式回归的思想以及在sklearn中使用多项式回归和pipeline
多项式回归以及在sklearn中使用多项式回归和pipeline 多项式回归 线性回归法有一个很大的局限性,就是假设数据背后是存在线性关系的,但是实际上,具有线性关系的数据集是相对来说比较少的,更多时 ...
- 在 ASP.NET 中创建数据访问和业务逻辑层(转)
.NET Framework 4 当在 ASP.NET 中处理数据时,可从使用通用软件模式中受益.其中一种模式是将数据访问代码与控制数据访问或提供其他业务规则的业务逻辑代码分开.在此模式中,这两个层均 ...
- 如何在浏览器中输入(myeclipse创建的项目的)地址访问JSP页面
如何在浏览器中输入(myeclipse创建的项目的)地址访问JSP页面 可以在Tomcat项目里面查看你的JSP页面在哪里,具体的路径为: tomcat--work--localhost--项目名称, ...
- 创建一个欢迎 cookie 利用用户在提示框中输入的数据创建一个 JavaScript Cookie,当该用户再次访问该页面时,根据 cookie 中的信息发出欢迎信息。
创建一个欢迎 cookie 利用用户在提示框中输入的数据创建一个 JavaScript Cookie,当该用户再次访问该页面时,根据 cookie 中的信息发出欢迎信息. <html> & ...
随机推荐
- 无刷电调基础知识以及BLHeli固件烧录和参数调整
标题: 无刷电调基础知识以及BLHeli固件烧录和参数调整 作者: 梦幻之心星 sky-seeker@qq.com 标签: [#基础知识,#电调,#BLHeli,#固件,#烧录,#调参] 目录: [电 ...
- Linux CGroup入门
Linux cgroup Linux CGroup全称Linux Control Group, 是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU.内存.磁盘输入输出等).L ...
- Mac变卡顿,优化性能
当调整窗口大小,同时按住"Option"键,可以从中央调整大小 同时按住"Shift"键时,可以按比例调整大小.同时按住这两个键,那么既成比例,又从中央调整大小 ...
- 开发环境管理利器Vagrant
引言 不知道你是否经历过,开发环境与生产环境不一致.Windows开发和Linux上的包效果不一样.在我这运行时好的啊 等等等问题,那有没有解决方法呢? 答案就是Vagrant.Docker 1.简介 ...
- NodeMCU学习笔记
NodeMCU学习笔记 引脚连通 引脚 连通 D3 FLASH按键 D0 模组上的LED D4 芯片的LED FLASH按键 D3引脚已经与开发板上的FLASH按键开关连接 我们可以通过NodeMCU ...
- Flink-v1.12官方网站翻译-P021-State & Fault Tolerance-overview
状态和容错 在本节中,您将了解Flink为编写有状态程序提供的API.请看一下Stateful Stream Processing来了解有状态流处理背后的概念. 下一步去哪里? Working wit ...
- Educational Codeforces Round 88 (Rated for Div. 2) A. Berland Poker(数学)
题目链接:https://codeforces.com/contest/1359/problem/A 题意 $n$ 张牌可以刚好被平分给 $k$ 个人,其中有 $m$ 张 joker,当一个人手中的 ...
- HDU 6852 Increasing and Decreasing 构造
题意: 给你一个n,x,y.你需要找出来一个长度为n的序列,使得这个序列满足最长上升子序列长度为x,最长下降子序列长度为y.且这个序列中每个数字只能出现一次 且要保证最后输出的序列的字典序最小 题解: ...
- codeforces626D . Jerry's Protest (概率)
Andrew and Jerry are playing a game with Harry as the scorekeeper. The game consists of three rounds ...
- Codeforces Round #641 (Div. 2) D. Orac and Medians (贪心)
题意:有一个长度为\(n\)的数组,问能否通过多次使某个区间的所有元素变成这个区间的中位数,来使整个数组变成题目所给定的\(k\). 题解:首先这个\(k\)一定要在数组中存在,然后我们对中位数进行考 ...