scrapy 基础组件专题(一):scrapy框架中各组件的工作流程
Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向):
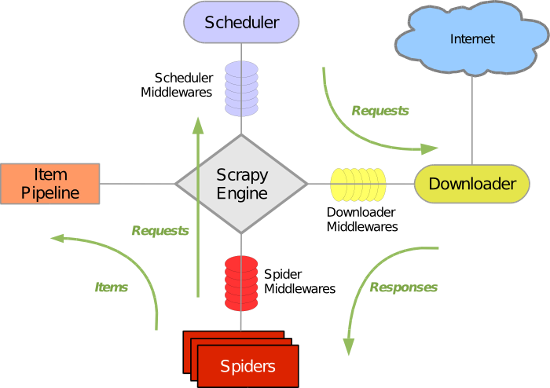
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
介于Scrapy引擎和下载器之间的中间件,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的中间件,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
1.引擎:Hi!Spider, 你要处理哪一个网站?
2.Spider:老大要我处理xxxx.com(初始URL)。
3.引擎:你把第一个需要处理的URL给我吧。
4.Spider:给你,第一个URL是xxxxxxx.com。
5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6.调度器:好的,正在处理你等一下。
7.引擎:Hi!调度器,把你处理好的request请求给我。
8.调度器:给你,这是我处理好的request
9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。
10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14.管道、调度器:好的,现在就做!
scrapy 基础组件专题(一):scrapy框架中各组件的工作流程的更多相关文章
- drf框架中分页组件
drf框架中分页组件 普通分页(最常用) 自定制分页类 pagination.py from rest_framework.pagination import PageNumberPagination ...
- drf框架中认证与权限工作原理及设置
0909自我总结 drf框架中认证与权限工作原理及设置 一.概述 1.认证 工作原理 返回None => 游客 返回user,auth => 登录用户 抛出异常 => 非法用户 前台 ...
- nodejs的Express框架源码分析、工作流程分析
nodejs的Express框架源码分析.工作流程分析 1.Express的编写流程 2.Express关键api的使用及其作用分析 app.use(middleware); connect pack ...
- django框架中form组件的简单使用示例:注册验证
Django中form组件的三大特点: 1. 生成页面可使用的HTML标签 2. 对用户提交的数据进行初步校验 3. 保留上次输入内容 废话不多说,直接进入正题. 这是注册界面截图: 与上一篇a ...
- Scrapy基础(十)———同步机制将Item中的数据写在Mysql
前面讲解到将Item中的所有字段都已经填写完成,那么接下来就是将他们存储到mysql数据库中,那就用到了pipeline项目管道了: 对项目管道的理解:做一个比喻,爬取好比是开采石油,Item装 ...
- Scrapy基础(二)————Scrapy的安装和目录结构
Scrapy安装: 1,首先进入虚拟环境 2,使用国内豆瓣源进行安装,快! pip install -i https://pypi.douban.com/simple/ scrapy 3,特殊情 ...
- scrapy基础知识之制作 Scrapy 爬虫 一共需要4步:
1.新建项目 (scrapy startproject xxx):新建一个新的爬虫项目 2.明确目标 (编写items.py):明确你想要抓取的目标 3.制作爬虫 (spiders/xxspider. ...
- Primeng UI框架中 分页组件用法
1.在当前模块或当前页面的对应的module.ts文件中引入相应组件模块,如:core.module.ts模块. import { PaginatorModule } from 'primeng/pr ...
- 使用spring框架中的组件发送邮件
首先进入自己的QQ邮箱,在设置中修改账户信息 然后来至底部 点击开启,再用手机发送对应信息到指定号码,然后点击我已发送 获取授权码 注意提示: 到这里,相信你已经开通了SMTP服务,这样就可以在 ...
随机推荐
- 如何解析json格式的字符串
package com.json; import java.util.ArrayList; import java.util.HashMap; import java.util.List; impor ...
- matplotlib作图一例
知识点都在这个例子里面: plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt ...
- 关于自动寻路(Navigation)的初级总结
1.使用Nav Mesh Link组件 该组件会实现寻路者从Start跳向end点 注意Player会优先选择最佳路线,且Start,End两个物体都应该在Walkable的区域上 2.使用Nav M ...
- 【DMCP】2020-CVPR-DMCP Differentiable Markov Channel Pruning for Neural Networks-论文阅读
DMCP 2020-CVPR-DMCP Differentiable Markov Channel Pruning for Neural Networks Shaopeng Guo(sensetime ...
- Python之浅谈生成器
目录 三元表达式 列表推导式 字典生成式 生成器 生成器表达式 匿名函数 三元表达式 a=0 b=6 print (a)if a>b else print(b) 三元表达式只能写if的双分支结构 ...
- Install fail! Error: EBUSY: resource busy or locked, rename
https://stackoverflow.com/questions/36566236/npm-install-error-code-ebusy-errono-4082 关闭项目所在的文件夹,cmd ...
- 一文读懂 Redis 分布式部署方案
为什么要分布式 Redis是一款开源的基于内存的K-V型数据库,因为内存访问速度快,一般被用来做系统的缓存. Redis作为单机部署能够支持业务简单,数据量不大的系统需求,但在实际应用中,一旦系统规模 ...
- 服务消费者(Feign-下)
上一篇文章中已经讲述 Feign的基本用法,本章主要概述 FeignClient GET/POST/PUT/DELETE restful写法以及 Feign 拦截器,与配置优化方案,关闭HttpCli ...
- npm tip: go to the package's home page
exec the following order: --- npm home <package name>
- 正确卸载vs2015及以前版本方式
官网工具:https://github.com/Microsoft/VisualStudioUninstaller/releases 亲自测试过,很好用. (完)