使用playwright爬取魔笔小说网站并下载轻小说资源
一、安装python
下载python3.9及以上版本
二、安装playwright
playwright是微软公司2020年初发布的新一代自动化测试工具,相较于目前最常用的Selenium,它仅用一个API即可自动执行Chromium、Firefox、WebKit等主流浏览器自动化操作。
(1)安装Playwright依赖库
1 pip install playwright
(2)安装Chromium、Firefox、WebKit等浏览器的驱动文件(内置浏览器)
1 python -m playwright install
三、分析网站的HTML结构
魔笔小说网是一个轻小说下载网站,提供了mobi、epub等格式小说资源,美中不足的是,需要跳转城通网盘下载,无会员情况下被限速且同一时间只允许一个下载任务。
当使用chrome浏览器时点击键盘的F12进入开发者模式。
(一)小说目录

HTML内容

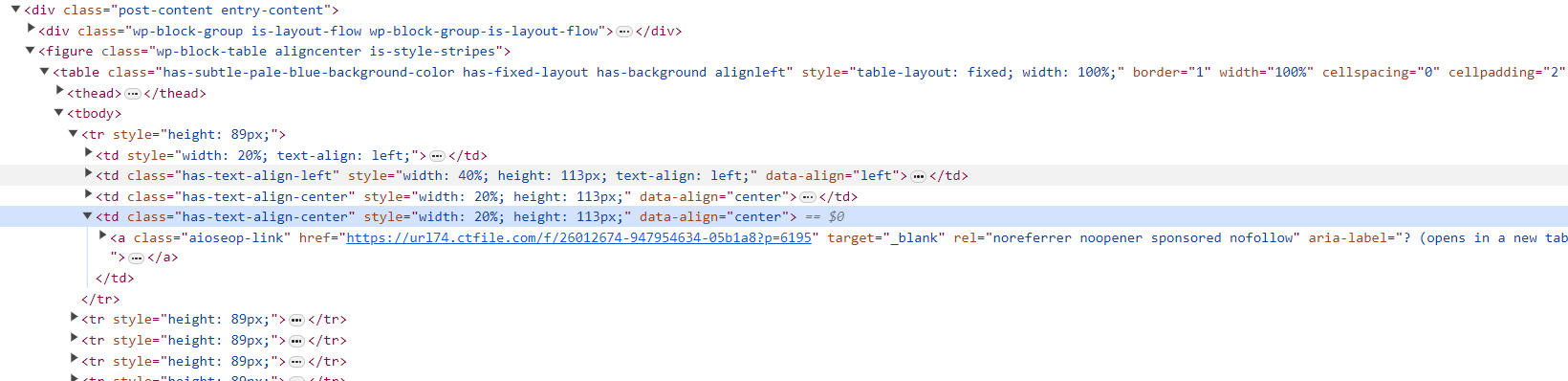
通过href标签可以获得每本小说的详细地址,随后打开该地址获取章节下载地址。
(二)章节下载目录
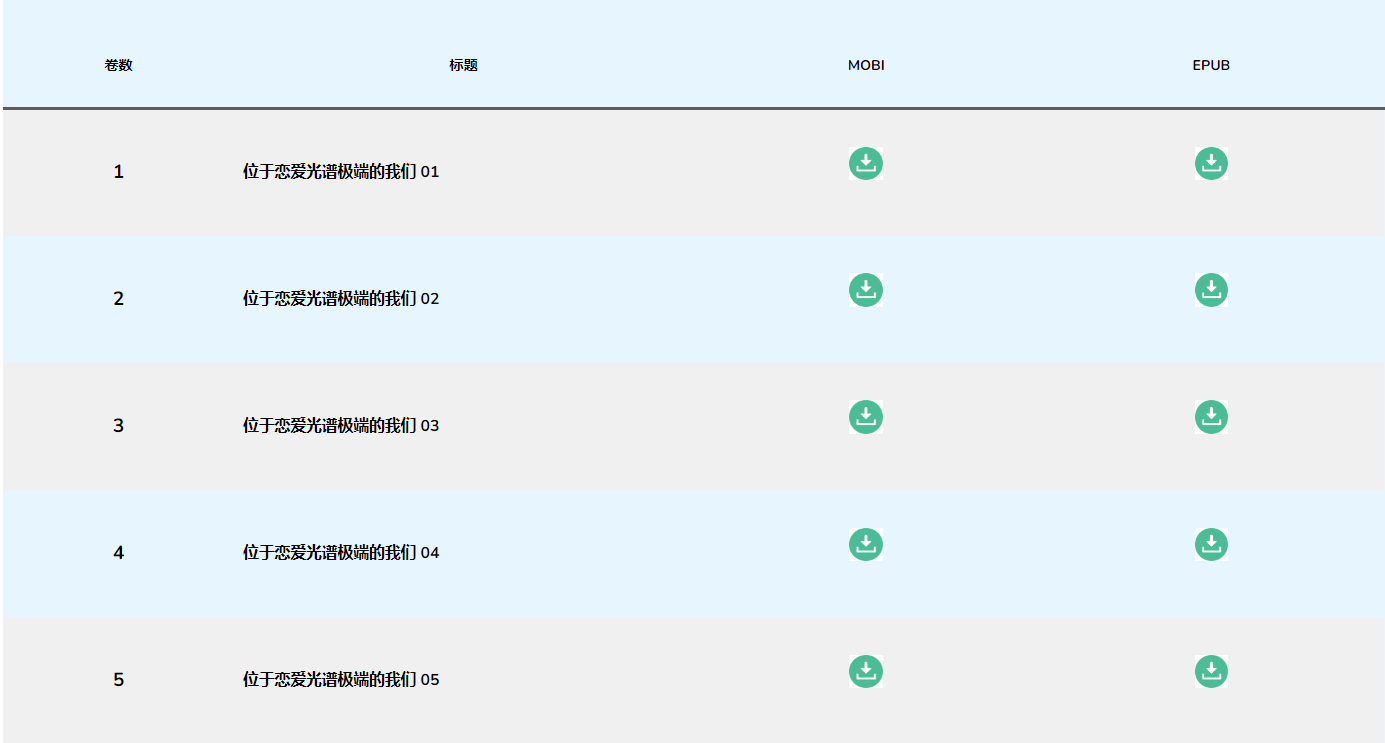
HTML内容
遍历每本小说的地址并保存到单独的txt文件中供后续下载。
(三)代码
1 import time,re
2
3 from playwright.sync_api import Playwright, sync_playwright, expect
4
5 def cancel_request(route,request):
6 route.abort()
7 def run(playwright: Playwright) -> None:
8 browser = playwright.chromium.launch(headless=False)
9 context = browser.new_context()
10 page = context.new_page()
11 # 不加载图片
12 # page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
13 page.goto("https://mobinovels.com/")
14 # 由于魔笔小说首页是动态加载列表,因此在此处加30s延迟,需手动滑动页面至底部直至加载完全部内容
15 for i in range(30):
16 time.sleep(1)
17 print(i)
18 # 定位至列表元素
19 novel_list = page.locator('[class="post-title entry-title"]')
20 # 统计小说数量
21 total = novel_list.count()
22 # 遍历获取小说详情地址
23 for i in range(total):
24 novel = novel_list.nth(i).locator("a")
25 title = novel.inner_text()
26 title_url = novel.get_attribute("href")
27 page1 = context.new_page()
28 page1.goto(title_url,wait_until='domcontentloaded')
29 print(i+1,total,title)
30 try:
31 content_list = page1.locator("table>tbody>tr")
32 # 保存至单独txt文件中供后续下载
33 with open('./novelurl/'+title+'.txt', 'a') as f:
34 for j in range(content_list.count()):
35 if content_list.nth(j).locator("td").count() > 2:
36 content_href = content_list.nth(j).locator("td").nth(3).locator("a").get_attribute("href")
37 f.write(title+str(j+1)+'分割'+content_href + '\n')
38 except:
39 pass
40 page1.close()
41 # 程序结束后手动关闭程序
42 time.sleep(50000)
43 page.close()
44
45 # ---------------------
46 context.close()
47 browser.close()
48
49
50 with sync_playwright() as playwright:
51 run(playwright)
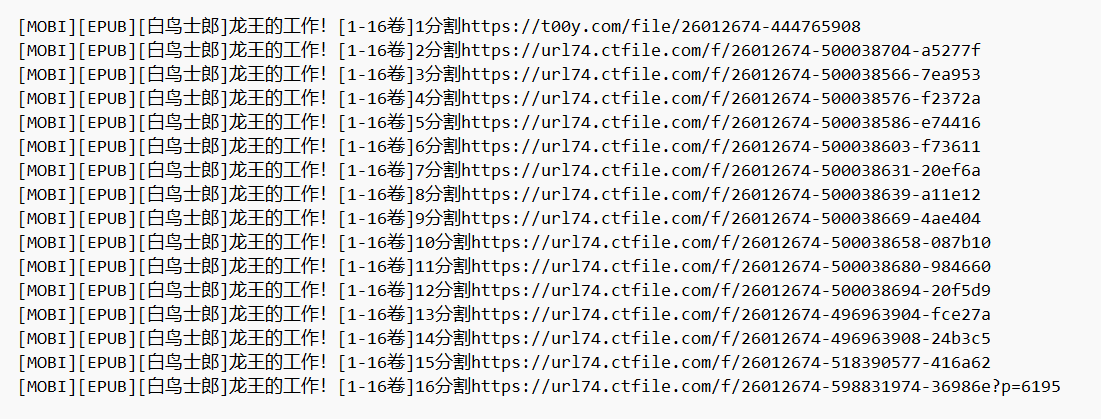
(四)运行结果

四、开始下载
之所以先将下载地址保存到txt再下载而不是立即下载,是防止程序因网络等原因异常崩溃后记录进度,下次启动避免重复下载。
(一)获取cookies
城通网盘下载较大资源时需要登陆,有的轻小说文件较大时,页面会跳转到登陆页面导致程序卡住,因此需利用cookies保存登陆状态,或增加延迟手动在页面登陆。
chrome浏览器可以通过cookies editor插件获取cookies,导出后即可使用。
(二)分析下载地址
下载地址有三种类型,根据判断条件分别处理:
(1)文件的访问密码统一为6195,当域名为 https://url74.ctfile.com/ 地址后缀带有 ?p=6195 时,页面自动填入访问密码,我们需要在脚本中判断后缀是否为 ?p=6195 ,如不是则拼接字符串后访问;
(2)有后缀时无需处理;
(3)当域名为 https://t00y.com/ 时无需密码;
1 if "t00y.com" in new_url:
2 page.goto(new_url)
3 elif "?p=6195" not in new_url:
4 page.goto(new_url+"?p=6195")
5 page.get_by_placeholder("文件访问密码").click()
6 page.get_by_role("button", name="解密文件").click()
7 else:
8 page.goto(new_url)
9 page.get_by_placeholder("文件访问密码").click()
10 page.get_by_role("button", name="解密文件").click()
(三)开始下载
playWright下载资源需利用 page.expect_download 函数。
下载完整代码如下:
1 import time,os
2
3 from playwright.sync_api import Playwright, sync_playwright, expect
4
5
6 def run(playwright: Playwright) -> None:
7 browser = playwright.chromium.launch(channel="chrome", headless=False) # 此处使用的是本地chrome浏览器
8 context = browser.new_context()
9 path = r'D:\PycharmProjects\wxauto\novelurl'
10 dir_list = os.listdir(path)
11 # 使用cookies
12 # cookies = []
13 # context.add_cookies(cookies)
14 page = context.new_page()
15 for i in range(len(dir_list)):
16 try:
17 novel_url = os.path.join(path, dir_list[i])
18 print(novel_url)
19 with open(novel_url) as f:
20 for j in f.readlines():
21 new_name,new_url = j.strip().split("分割")
22 if "t00y.com" in new_url:
23 page.goto(new_url)
24 elif "?p=6195" not in new_url:
25 page.goto(new_url+"?p=6195")
26 page.get_by_placeholder("文件访问密码").click()
27 page.get_by_role("button", name="解密文件").click()
28 else:
29 page.goto(new_url)
30 page.get_by_placeholder("文件访问密码").click()
31 page.get_by_role("button", name="解密文件").click()
32
33 with page.expect_download(timeout=100000) as download_info:
34 page.get_by_role("button", name="立即下载").first.click()
35 print(new_name,"开始下载")
36 download_file = download_info.value
37 download_file.save_as("./novel/"+dir_list[i][:-4]+"/"+download_file.suggested_filename)
38 time.sleep(3)
39 os.remove(novel_url)
40 print(i+1,dir_list[i],"下载结束")
41 except:
42 print(novel_url,"出错")
43 time.sleep(60)
44 page.close()
45
46 # ---------------------
47 context.close()
48 browser.close()
49
50
51 with sync_playwright() as playwright:
52 run(playwright)
(四)运行结果
使用playwright爬取魔笔小说网站并下载轻小说资源的更多相关文章
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
- python之如何爬取一篇小说的第一章内容
现在网上有很多小说网站,但其实,有一些小说网站是没有自己的资源的,那么这些资源是从哪里来的呢?当然是“偷取”别人的数据咯.现在的问题就是,该怎么去爬取别人的资源呢,这里便从简单的开始,爬取一篇小说的第 ...
- 如何用python爬虫从爬取一章小说到爬取全站小说
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- 用scrapy爬取亚马逊网站项目
这次爬取亚马逊网站,用到了scrapy,代理池,和中间件: spiders里面: # -*- coding: utf-8 -*- import scrapy from scrapy.http.requ ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- 使用requests+BeautifulSoup爬取龙族V小说
这几天想看龙族最新版本,但是搜索半天发现 没有网站提供 下载, 我又只想下载后离线阅读(写代码已经很费眼睛了).无奈只有自己 爬取了. 这里记录一下,以后想看时,直接运行脚本 下载小说. 这里是从 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- Python的scrapy之爬取6毛小说网的圣墟
闲来无事想看个小说,打算下载到电脑上看,找了半天,没找到可以下载的网站,于是就想自己爬取一下小说内容并保存到本地 圣墟 第一章 沙漠中的彼岸花 - 辰东 - 6毛小说网 http://www.6ma ...
- 使用scrapy爬取金庸小说目录和章节url
刚接触使用scrapy的时候,如果一开始就想实现特别复杂的配置,显然是不太现实的,用一些小的例子可以帮助自己理解各个模块. 今天的目标:爬取http://www.luoxia.com/shendiao ...
随机推荐
- Unity的IGenerateNativePluginsForAssemblies:深入解析与实用案例
Unity IGenerateNativePluginsForAssemblies Unity是一款非常流行的游戏引擎,它支持多种平台,包括Windows.Mac.Linux.Android.iOS等 ...
- 《Among Us》火爆全球,实时语音助力派对游戏开启第二春
今年在全球"宅经济"的影响下,社交派对类游戏意外的迎来了爆发. 8月份,<糖豆人:终极淘汰赛>突然爆火,创造了首日150万玩家.首周Steam 200万销量.单周Twi ...
- 前端uni-app自定义精美全端复制文本插件,支持全端文本复制插件 可设置复制按钮颜色
随着技术的发展,开发的复杂度也越来越高,传统开发方式将一个系统做成了整块应用,经常出现的情况就是一个小小的改动或者一个小功能的增加可能会引起整体逻辑的修改,造成牵一发而动全身. 通过组件化开发,可以有 ...
- Django-4.2博客开发教程:需求分析并确定数据表(四)
前三步已经完成了一个初步流程,从创建项目>应用>数据迁移>访问首页.以下是我整理的基本流程,接下来一步一步完成整个项目. 1.我们的需求: 博客的功能主要分为:网站首页.文章分类.文 ...
- mysql中使用sql语句统计日志计算每天的访问量
日志建表语句: CREATE TABLE `syslog` ( `syslogid` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(255) ...
- Sa-Token 多账号认证:同时为系统的 Admin 账号和 User 账号提供鉴权操作
Sa-Token 是一个轻量级 java 权限认证框架,主要解决登录认证.权限认证.单点登录.OAuth2.微服务网关鉴权 等一系列权限相关问题. Gitee 开源地址:https://gitee.c ...
- 分布式ID性能评测:CosId VS 美团 Leaf
分布式ID性能评测:CosId VS 美团 Leaf 基准测试环境 MacBook Pro (M1) JDK 17 JMH 1.36 运行在本机的Docker 的 mariadb:10.6.4 运行基 ...
- NOIP 2023 模拟赛 20230712 C 论剑
首先是伟大的题面 然后是数据范围 先解决1-4号数据点 1.枚举每个gcd的值p,统计一次答案,得到最小值(期望得分20) \[ans=\min_{p=2}^{\max a}\sum^n_{i=1}\ ...
- React:styled-components有趣的用法
背景 用于记录一些styled-components的有趣的用法 绑定a标签的链接 编写伪类 在styleComponents中使用参数 传入参数
- Node: Module not found: Can't resolve 'xlsx'
报错信息 解决方案 npm install xlsx --save 参考链接 https://github.com/securedeveloper/react-data-export/issues/8 ...