使用playwright爬取魔笔小说网站并下载轻小说资源
一、安装python
下载python3.9及以上版本
二、安装playwright
playwright是微软公司2020年初发布的新一代自动化测试工具,相较于目前最常用的Selenium,它仅用一个API即可自动执行Chromium、Firefox、WebKit等主流浏览器自动化操作。
(1)安装Playwright依赖库
1 pip install playwright
(2)安装Chromium、Firefox、WebKit等浏览器的驱动文件(内置浏览器)
1 python -m playwright install
三、分析网站的HTML结构
魔笔小说网是一个轻小说下载网站,提供了mobi、epub等格式小说资源,美中不足的是,需要跳转城通网盘下载,无会员情况下被限速且同一时间只允许一个下载任务。
当使用chrome浏览器时点击键盘的F12进入开发者模式。
(一)小说目录

HTML内容

通过href标签可以获得每本小说的详细地址,随后打开该地址获取章节下载地址。
(二)章节下载目录
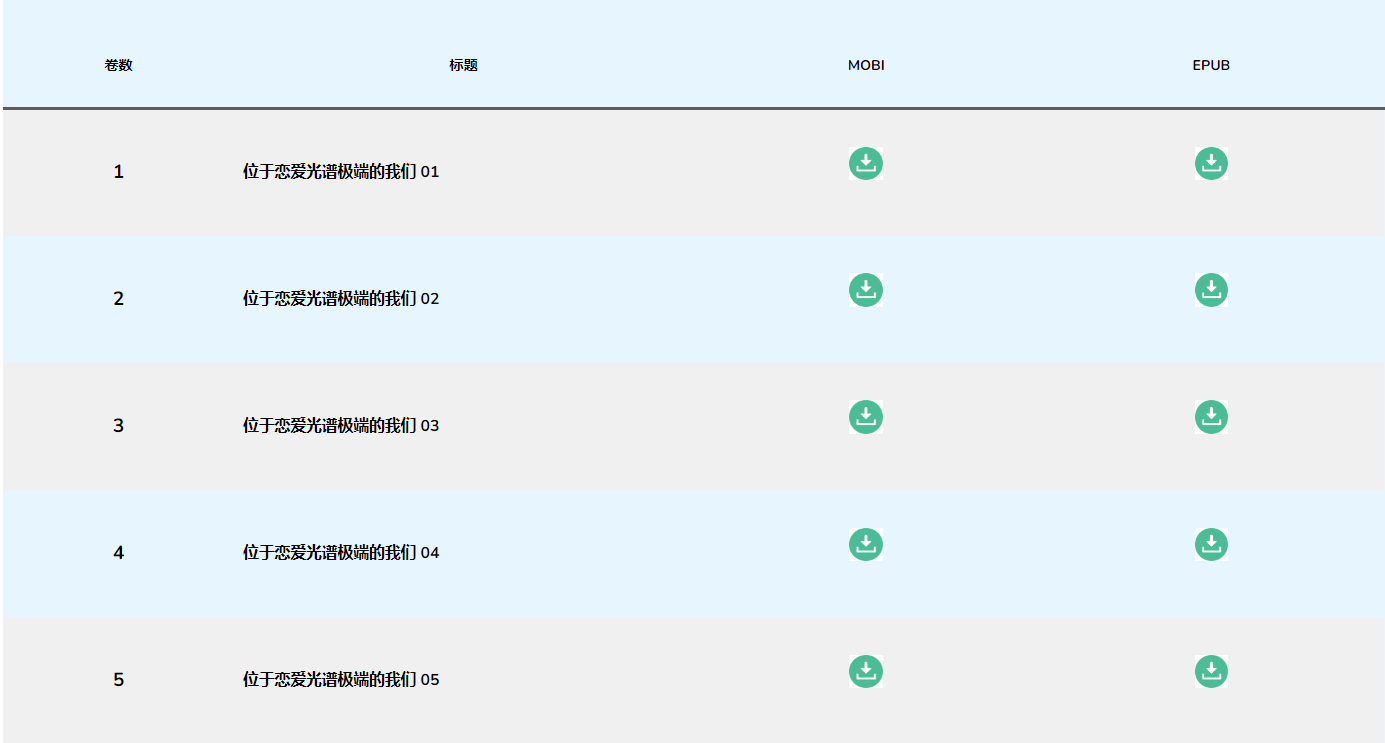
HTML内容
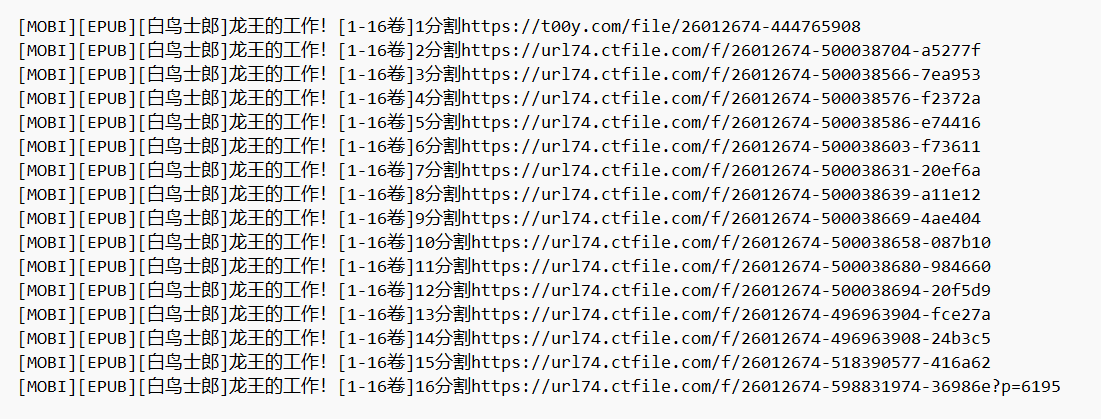
遍历每本小说的地址并保存到单独的txt文件中供后续下载。
(三)代码
1 import time,re
2
3 from playwright.sync_api import Playwright, sync_playwright, expect
4
5 def cancel_request(route,request):
6 route.abort()
7 def run(playwright: Playwright) -> None:
8 browser = playwright.chromium.launch(headless=False)
9 context = browser.new_context()
10 page = context.new_page()
11 # 不加载图片
12 # page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
13 page.goto("https://mobinovels.com/")
14 # 由于魔笔小说首页是动态加载列表,因此在此处加30s延迟,需手动滑动页面至底部直至加载完全部内容
15 for i in range(30):
16 time.sleep(1)
17 print(i)
18 # 定位至列表元素
19 novel_list = page.locator('[class="post-title entry-title"]')
20 # 统计小说数量
21 total = novel_list.count()
22 # 遍历获取小说详情地址
23 for i in range(total):
24 novel = novel_list.nth(i).locator("a")
25 title = novel.inner_text()
26 title_url = novel.get_attribute("href")
27 page1 = context.new_page()
28 page1.goto(title_url,wait_until='domcontentloaded')
29 print(i+1,total,title)
30 try:
31 content_list = page1.locator("table>tbody>tr")
32 # 保存至单独txt文件中供后续下载
33 with open('./novelurl/'+title+'.txt', 'a') as f:
34 for j in range(content_list.count()):
35 if content_list.nth(j).locator("td").count() > 2:
36 content_href = content_list.nth(j).locator("td").nth(3).locator("a").get_attribute("href")
37 f.write(title+str(j+1)+'分割'+content_href + '\n')
38 except:
39 pass
40 page1.close()
41 # 程序结束后手动关闭程序
42 time.sleep(50000)
43 page.close()
44
45 # ---------------------
46 context.close()
47 browser.close()
48
49
50 with sync_playwright() as playwright:
51 run(playwright)
(四)运行结果

四、开始下载
之所以先将下载地址保存到txt再下载而不是立即下载,是防止程序因网络等原因异常崩溃后记录进度,下次启动避免重复下载。
(一)获取cookies
城通网盘下载较大资源时需要登陆,有的轻小说文件较大时,页面会跳转到登陆页面导致程序卡住,因此需利用cookies保存登陆状态,或增加延迟手动在页面登陆。
chrome浏览器可以通过cookies editor插件获取cookies,导出后即可使用。
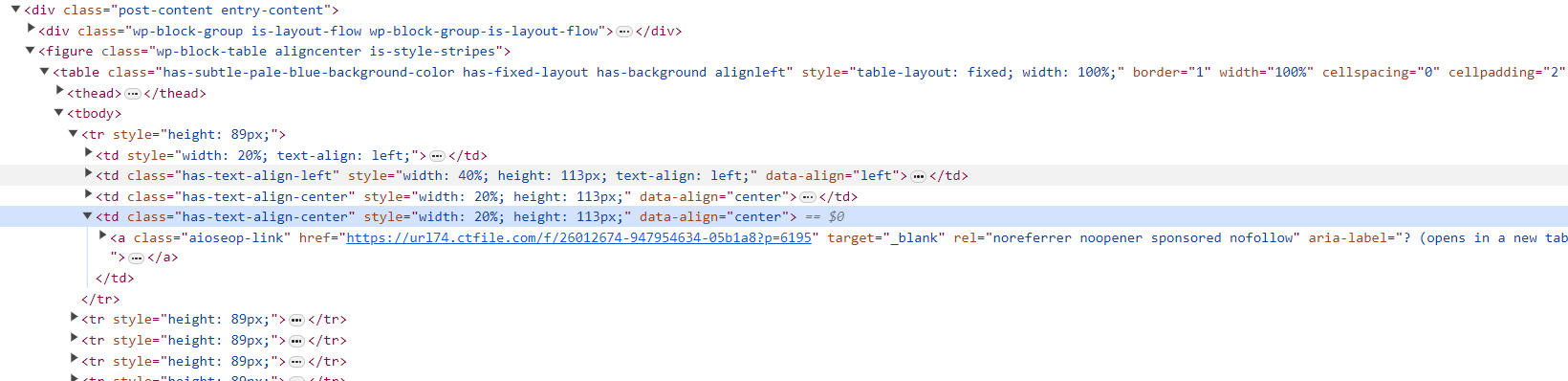
(二)分析下载地址
下载地址有三种类型,根据判断条件分别处理:
(1)文件的访问密码统一为6195,当域名为 https://url74.ctfile.com/ 地址后缀带有 ?p=6195 时,页面自动填入访问密码,我们需要在脚本中判断后缀是否为 ?p=6195 ,如不是则拼接字符串后访问;
(2)有后缀时无需处理;
(3)当域名为 https://t00y.com/ 时无需密码;
1 if "t00y.com" in new_url:
2 page.goto(new_url)
3 elif "?p=6195" not in new_url:
4 page.goto(new_url+"?p=6195")
5 page.get_by_placeholder("文件访问密码").click()
6 page.get_by_role("button", name="解密文件").click()
7 else:
8 page.goto(new_url)
9 page.get_by_placeholder("文件访问密码").click()
10 page.get_by_role("button", name="解密文件").click()
(三)开始下载
playWright下载资源需利用 page.expect_download 函数。
下载完整代码如下:
1 import time,os
2
3 from playwright.sync_api import Playwright, sync_playwright, expect
4
5
6 def run(playwright: Playwright) -> None:
7 browser = playwright.chromium.launch(channel="chrome", headless=False) # 此处使用的是本地chrome浏览器
8 context = browser.new_context()
9 path = r'D:\PycharmProjects\wxauto\novelurl'
10 dir_list = os.listdir(path)
11 # 使用cookies
12 # cookies = []
13 # context.add_cookies(cookies)
14 page = context.new_page()
15 for i in range(len(dir_list)):
16 try:
17 novel_url = os.path.join(path, dir_list[i])
18 print(novel_url)
19 with open(novel_url) as f:
20 for j in f.readlines():
21 new_name,new_url = j.strip().split("分割")
22 if "t00y.com" in new_url:
23 page.goto(new_url)
24 elif "?p=6195" not in new_url:
25 page.goto(new_url+"?p=6195")
26 page.get_by_placeholder("文件访问密码").click()
27 page.get_by_role("button", name="解密文件").click()
28 else:
29 page.goto(new_url)
30 page.get_by_placeholder("文件访问密码").click()
31 page.get_by_role("button", name="解密文件").click()
32
33 with page.expect_download(timeout=100000) as download_info:
34 page.get_by_role("button", name="立即下载").first.click()
35 print(new_name,"开始下载")
36 download_file = download_info.value
37 download_file.save_as("./novel/"+dir_list[i][:-4]+"/"+download_file.suggested_filename)
38 time.sleep(3)
39 os.remove(novel_url)
40 print(i+1,dir_list[i],"下载结束")
41 except:
42 print(novel_url,"出错")
43 time.sleep(60)
44 page.close()
45
46 # ---------------------
47 context.close()
48 browser.close()
49
50
51 with sync_playwright() as playwright:
52 run(playwright)
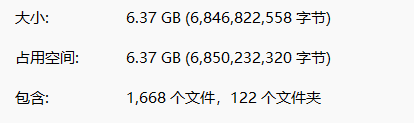
(四)运行结果
使用playwright爬取魔笔小说网站并下载轻小说资源的更多相关文章
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
- python之如何爬取一篇小说的第一章内容
现在网上有很多小说网站,但其实,有一些小说网站是没有自己的资源的,那么这些资源是从哪里来的呢?当然是“偷取”别人的数据咯.现在的问题就是,该怎么去爬取别人的资源呢,这里便从简单的开始,爬取一篇小说的第 ...
- 如何用python爬虫从爬取一章小说到爬取全站小说
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- 用scrapy爬取亚马逊网站项目
这次爬取亚马逊网站,用到了scrapy,代理池,和中间件: spiders里面: # -*- coding: utf-8 -*- import scrapy from scrapy.http.requ ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- 使用requests+BeautifulSoup爬取龙族V小说
这几天想看龙族最新版本,但是搜索半天发现 没有网站提供 下载, 我又只想下载后离线阅读(写代码已经很费眼睛了).无奈只有自己 爬取了. 这里记录一下,以后想看时,直接运行脚本 下载小说. 这里是从 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- Python的scrapy之爬取6毛小说网的圣墟
闲来无事想看个小说,打算下载到电脑上看,找了半天,没找到可以下载的网站,于是就想自己爬取一下小说内容并保存到本地 圣墟 第一章 沙漠中的彼岸花 - 辰东 - 6毛小说网 http://www.6ma ...
- 使用scrapy爬取金庸小说目录和章节url
刚接触使用scrapy的时候,如果一开始就想实现特别复杂的配置,显然是不太现实的,用一些小的例子可以帮助自己理解各个模块. 今天的目标:爬取http://www.luoxia.com/shendiao ...
随机推荐
- 完美决解win10 可以上网却显示无internet的bug
试过网上的几乎所有方法,例如禁用复用网卡.网络重置.禁用复用服务,也用了用修改注册表下HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesNlaSvcPa ...
- 从头学Java17-Modules模块
模块Modules 了解module系统如何塑造 JDK,如何使用,使项目更易于维护. 烧哥注 从头讲JDK17的文章比较少,英文为主,老外虽能讲清原理,但写的比较绕,所以决定翻译一下,也有个别细节完 ...
- [译]使用Python和Dash 创建一个仪表盘(上)
介绍 在数据科学和分析的领域,数据能力的释放不仅是通过提取见解的方式, 同时也要能通过有效的方式来传达见解.这就是数据可视化发挥见解的地方. 数据可视化是信息和数据的可视化呈现. 它使用可视化元素,如 ...
- Openjob 1.0.5 发布,新增 Agent
什么是 Openjob? Openjob 基于Akka架构的新一代分布式任务调度框架.支持多种定时任务.延时任务.工作流设计,采用无中心化架构,底层使用一致性分片算法,支持无限水平扩容. 完善的任务日 ...
- mysql-workbench-community报错解决办法
输入以下命令: sudo apt-get -f install 参考链接:https://www.jianshu.com/p/767c9a29b403
- asp.net core之HttpClient
本文介绍了ASP.NET Core中的HttpClient和HttpClientFactory的作用.用法以及最佳实践.通过示例代码的展示,读者可以了解如何使用HttpClient发送HTTP请求并处 ...
- 来会会babel这个重要且神奇的工具
babel 在前端工程化开发中发挥着至关重要的作用,它能将较高级的语法转成浏览器可识别的代码,无论中 es6 中 const .promise 还是 React.TypeScript. 以下babel ...
- 使用 OpenTelemetry 构建 .NET 应用可观测性(1):什么是可观测性
目录 什么是系统的可观测性(Observability) 为什么需要软件系统需要可观测性 可观测性的三大支柱 日志(Logging) 指标(Metrics) 分布式追踪(Distributed Tra ...
- Hugging News #0821: Hugging Face 完成 2.35 亿美元 D 轮融资
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 如何使用Grid中的repeat函数
在本文中,我们将探索 CSS Grid repeat() 函数的所有可能性,它允许我们高效地创建 Grid 列和行的模式,甚至无需媒体查询就可以创建响应式布局. 不要重复自己 通过 grid-temp ...