Optimal Value Functions and Optimal Policy
Optimal Value Function is how much reward the best policy can get from a state s, which is the best senario given state s. It can be defined as:

Value Function and Optimal State-Value Function
Let's see firstly compare Value Function with Optimal Value Function. For example, in the student study case, the value function for the blue circle state under 50:50 policy is 7.4.
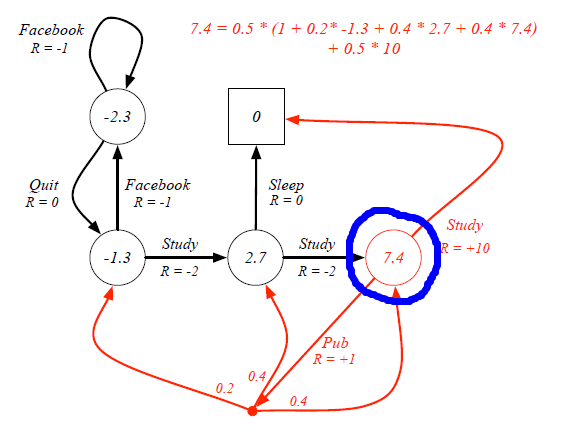
However, when we consider the Optimal State-Value function, 'branches' that may prevent us from getting the best scores are proned. For instance, the optimal senario for the blue circle state is having 100% probability to continue his study rather than going to pub.

Optimal Action-Value Function
Then we move to Action-Value Function, and the following equation also reveals the Optimal Action-Value Function is from the policy who gives the best Action Returns.
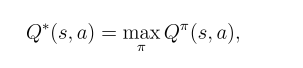
The Optimal Action-Value Function is strongly related to Optimal State-Value Function by:
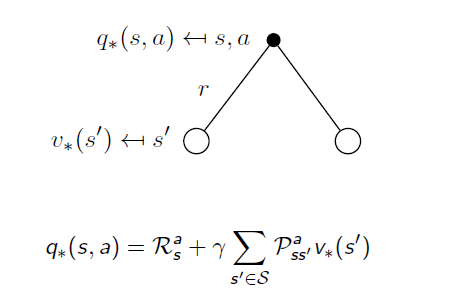
The equation means when action a is taken at state s, what the best return is. At this condition, the probability of reaching each state and the immediate reward is determined, so the only variable is the State-Value function . Therefore it is obvious that obtaining the Optimal State-Value function is equivalent to holding the Optimal Action-Value Function.
Conversely, the Optimal State-Value function is the best combination of Action and the following states with Optimal State-value Functions:

Still in the student example, when we know the Optimal State-Value Function, the Optimal Action-Value Function can be calculated as:
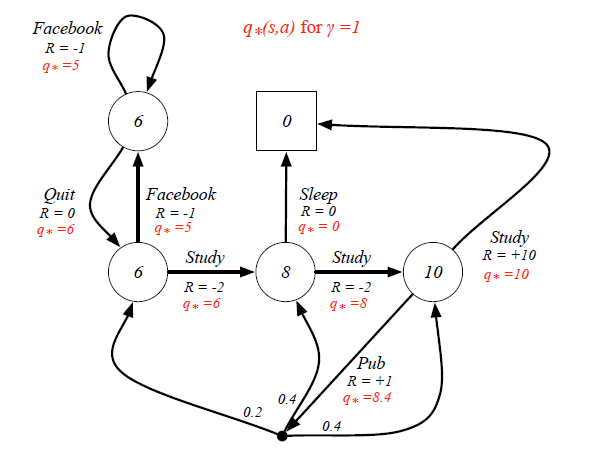
Finally we can derive the best policy from the Optimal Action-Value Function:
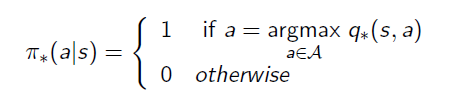
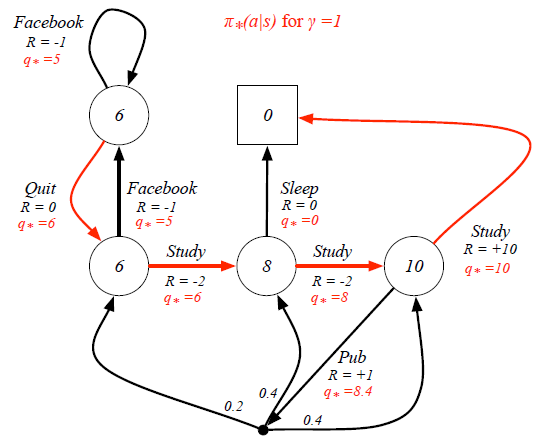
This means the policy only picks up the best action at every state rather than having a probability distribution. This deterministic policy is the goal of Reinforcement Learning, as it will guide the action to complete the task.
Optimal Value Functions and Optimal Policy的更多相关文章
- Reinforcement Learning: An Introduction读书笔记(3)--finite MDPs
> 目 录 < Agent–Environment Interface Goals and Rewards Returns and Episodes Policies and Val ...
- Machine Learning——吴恩达机器学习笔记(酷
[1] ML Introduction a. supervised learning & unsupervised learning 监督学习:从给定的训练数据集中学习出一个函数(模型参数), ...
- RL_Learning
Key Concepts in RL 标签(空格分隔): RL_learning OpenAI Spinning Up原址 states and observations (状态和观测) action ...
- Massively parallel supercomputer
A novel massively parallel supercomputer of hundreds of teraOPS-scale includes node architectures ba ...
- Factoextra R Package: Easy Multivariate Data Analyses and Elegant Visualization
factoextra is an R package making easy to extract and visualize the output of exploratory multivaria ...
- 深度学习课程笔记(七):模仿学习(imitation learning)
深度学习课程笔记(七):模仿学习(imitation learning) 2017.12.10 本文所涉及到的 模仿学习,则是从给定的展示中进行学习.机器在这个过程中,也和环境进行交互,但是,并没有显 ...
- DP Intro - OBST
http://radford.edu/~nokie/classes/360/dp-opt-bst.html Overview Optimal Binary Search Trees - Problem ...
- [C5] Andrew Ng - Structuring Machine Learning Projects
About this Course You will learn how to build a successful machine learning project. If you aspire t ...
- Reinforcement Learning Index Page
Reinforcement Learning Posts Step-by-step from Markov Property to Markov Decision Process Markov Dec ...
随机推荐
- Vert.x学习第一天
昨天看了下异步,然后就开始了Vert.x相关知识的学习. Vert.x是当下非常流行的一套全异步框架,其优势在于轻量级.高效.非常适合作为移动端后台或是企业应用. 当然对于第一天接触这个框架的人(没错 ...
- HDU 4013 Distinct Subtrees(树的最小表示)
Distinct Subtrees Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65768/65768 K (Java/Other ...
- SCUT - 131 - 小P玩游戏II - 贪心 - 平衡树
https://scut.online/p/131 首先假如钦定了一群人去打怪兽,那么可以把主要的任务都丢给b最大的人去打,这样不会更差.然后考虑枚举这个b最大的人,其他人陪练.一开始就是ai+k*b ...
- 【推荐系统】知乎live入门5.常用技能与日常工作
参考链接 [推荐系统]知乎live入门 目录 1. 实习与求职 2. 推荐算法职责 3. 解构算法 4. 参考资料 5. 其他强关联岗位 6. 工作模型和日常工作 7. 2017年相关论文 8. 找工 ...
- HBase HA分布式集群搭建
HBase HA分布式集群搭建部署———集群架构 搭建之前建议先学习好HBase基本构架原理:https://www.cnblogs.com/lyywj170403/p/9203012.html 集群 ...
- leetcode x进制数 python3
不少题目都是实现吧10进制数转换成x进制数,实际上都是一个套路,下面是7进制的,想换成什么进制,把7替换成相应数字即可,输出的是字符串 16,32进制这种有特殊要求的转不了,其他的应该通用 class ...
- 【LeetCode】二分 binary_search(共58题)
[4]Median of Two Sorted Arrays [29]Divide Two Integers [33]Search in Rotated Sorted Array [34]Find F ...
- $2019$各种$WC$没去记
\(2019\)各种\(WC\)没去记 太弱了去不了啊. 至少我联赛没退役是吧...(退役感++ 不过这个分数线还是有点让人自闭啊,划线人绝对有毒,有人关照一下空巢老人\(mona\)喵? 这里大概是 ...
- Kettle日志级别
Kettle的日志级别LogLevel分为以下几个: Nothing 没有日志 不显示任何输出 Error 错误日志 仅仅显示错误信息 Minimal 最小日志 使用最小的日志 Basic 基本日志 ...
- centos上部署flask项目之环境配置-MySQL的安装
1.添加mysql 的yum源 wget 'https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm' rpm ...