Java实现WordCount
GitHub项目地址:https://github.com/happyOwen/SoftwareEngineering
wordcount项目要求:
程序处理用户需求的模式为:wc.exe [parameter] [file_name]
基本功能列表:
-c file.c //返回文件 file.c 的字符数(实现)
-w file.c //返回文件 file.c 的词的数目 (实现)
-l file.c //返回文件 file.c 的行数(实现)
扩展功能:
-s 递归处理目录下符合条件的文件(实现)
-a 返回更复杂的数据(代码行 / 空行 / 注释行)(实现)
空行:本行全部是空格或格式控制字符,如果包括代码,则只有不超过一个可显示的字符,例如“{”。
代码行:本行包括多于一个字符的代码。
注释行:本行不是代码行,并且本行包括注释。
[file_name]: 文件或目录名,可以处理一般通配符(实现)
高级功能:
- -x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,
程序就会显示文件的字符数、行数等全部统计信息。(未实现)
PSP表:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 1080 | 1680 |
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 200 |
| · Design Spec | · 生成设计文档 | 50 | 100 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 40 | 100 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| · Design | · 具体设计 | 50 | 150 |
| · Coding | · 具体编码 | 600 | 800 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 250 |
| Reporting | 报告 | 120 | 150 |
| · Test Report | · 测试报告 | 90 | 120 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 20 |
| 合计 | 1230 | 1990 |
解题思路:
刚看到这个题目的时候觉得有些无从下手,主要是对于扩展功能中的代码行、空行、注释行的含义理解不是很懂,以及不太明白如何
递归处理目录下符合条件(以通配符表示)的文件,经过自己的思考和同学的讨论,我发现主要是对文件的IO和对String的解析和正则表达式的匹配问题,所以我参考了网上有关正则表达式的教程并阅读了java相关教材。
设计实现过程
以main()为中心,通过cmd传入参数到main(String[] args)获取操作和文件路径,根据是否查询子目录调用getRecursiveFiles()和getFiles()获取需要符合条件的文件,并将其绝对路径添加到ArrayList中,最后遍历ArrayList并根据相应的操作对相应的文件执行相应的操作方法。
总共设计了两个类Main.java、CountUtils.java。Main.java类主要处理传入的参数并根据参数执行CountUtils.java里面的功能函数
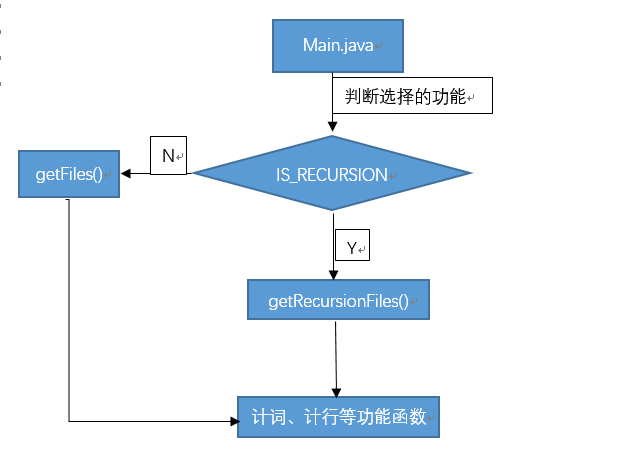
代码说明
Main.java,通过args获取要执行的操作,并根据是否递归来获取所有符合条件的文件路径,遍历并执行相应的功能函数
package com.homework.first;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
public class Main {
private static boolean IS_COUNTCHAR = false;
private static boolean IS_COUNTWORD = false;
private static boolean IS_COUNTLINE = false;
private static boolean IS_RECURSION = false;
private static boolean IS_COUNTDIFFLINE = false;
//利用ArrayList存储符合条件的文件的绝对路径
private static ArrayList<String> fileList = new ArrayList<String>();
public static void main(String[] args) throws IOException,ArrayIndexOutOfBoundsException {
//默认最后一个参数为路径名
String path = args[args.length - 1];
CountUtils cUtils = new CountUtils();
//判断需要执行的功能
for(int i = 0; i < args.length - 1; i++) {
if(args[i].equals("-c")) {
IS_COUNTCHAR = true;
}
if(args[i].equals("-w")) {
IS_COUNTWORD = true;
}
if(args[i].equals("-l")) {
IS_COUNTLINE = true;
}
if(args[i].equals("-s")) {
IS_RECURSION = true;
}
if(args[i].equals("-a")) {
IS_COUNTDIFFLINE = true;
}
}
//获取目录名
String paths[] = path.split("\\\\");
StringBuilder sb = new StringBuilder();
for(int i=0;i<paths.length-1;i++) {
if(i==paths.length-2) {
sb.append(paths[i]);
}else {
sb.append(paths[i]+"\\");
}
}
String dirName = sb.toString();
File file = new File(dirName);
if(!file.isDirectory()) {
System.out.println("路径错误!");
}
String fileName =paths[paths.length-1];
//对文件名通配符处理
fileName = fileName.replaceAll("\\*", "\\.+").replaceAll("\\?", "\\.");
//若IS_RECURSION,则使用递归获取文件名(包括子目录),否则只获取当前目录下符合条件的文件名
if(IS_RECURSION) {
cUtils.getRecursionFiles(dirName, fileName);
}else {
cUtils.getFiles(dirName, fileName);
}
fileList = cUtils.fileList;
//遍历fileList,对每一个文件使用选择的功能
for(String item : fileList) {
System.out.println("文件路径为:"+item);
if(IS_COUNTCHAR) {
cUtils.countChar(item);
}
if(IS_COUNTWORD) {
cUtils.countWord(item);
}
if(IS_COUNTLINE) {
cUtils.countLine(item);
}
if(IS_COUNTDIFFLINE) {
cUtils.countDiffLine(item);
}
}
}
}
以下是相应的功能函数:
- -c
//利用BufferedReader整行读取统计字符数
public int countChar(String path) {
File file = new File(path);
BufferedReader br = null;
String line;
int charNum = 0;
try {
br = new BufferedReader(new FileReader(file));
while((line = br.readLine()) != null){
char[] ch = line.toCharArray();
for(int i=0; i < ch.length; i++) {
if(!Character.isWhitespace(ch[i])) {
charNum++;
}
}
}
System.out.println("the charCount is: " + charNum);
br.close();
} catch (Exception e) {
System.out.println(path + "文件名错误");
}
return charNum;
}
- -w
/*
* 统计英文单词数
* 先用BufferedReader整行读取,然后添加到StringBuffer中,
* 将StringBuffer转化为字符串后,然后将非英文字符替换为空格,再根据空格分割
*/
public int countWord(String path) {
BufferedReader br = null;
String line;
String[] strings;
StringBuffer sbf = new StringBuffer();
int wordNum = 0;
String reg = "\\s+";
try {
br = new BufferedReader(new FileReader(path));
while((line = br.readLine()) != null){
sbf.append(line);
}
String s = sbf.toString().replaceAll("[^a-zA-Z]", " ");
strings = s.split(reg);
wordNum = strings.length;
System.out.println("the wordCount is: " + wordNum);
br.close();
} catch (IOException e) {
System.out.println(path + "文件名错误");
}
return wordNum;
}
- -l
//统计总行数
public int countLine(String path) {
BufferedReader br = null;
String line;
int lineNum = 0;
try {
br = new BufferedReader(new FileReader(path));
while((line = br.readLine()) != null){
lineNum++;
}
System.out.println("the lineCount is: " + lineNum);
br.close();
} catch (IOException e) {
System.out.println(path + "文件名错误");
}
return lineNum;
}
- -a
//统计注释行、空行、代码行
public void countDiffLine(String path) {
int annotationLineNum = 0;
int codeLineNum = 0;
int nullLineNum = 0;
String line;
BufferedReader br = null;
// 注释匹配器(匹配单行、多行、文档注释)
Pattern annotationLinePattern = Pattern.compile("(//)|(/\\*)|(^\\s*\\*)|(^\\s*\\*+/)");
try {
br = new BufferedReader(new FileReader(path));
while((line = br.readLine()) != null){
if(annotationLinePattern.matcher(line).find()) {//注释行
annotationLineNum++;
}else if (line.matches("\\s*\\p{Graph}?\\s*")) {//空行
nullLineNum++;
}else {
codeLineNum++;
}
}
System.out.println("the nullLineNum is: " + nullLineNum);
System.out.println("the annotationLineNum is: " + annotationLineNum);
System.out.println("the codeLineNum is: " + codeLineNum);
br.close();
} catch (IOException e) {
System.out.println(path + "文件名错误");
}
}
- 递归获取符合条件的文件的绝对路径(在Main.java中已对fileName进行通配符处理):
public void getRecursionFiles(String dirName,String fileName) {
File file = new File(dirName);
if(file.isDirectory()) {
File[] files = file.listFiles();
if(files!=null) {
for(File file1 : files) {
//当file1仍然是目录时,递归调用此函数
if(file1.isDirectory()) {
getRecursionFiles(dirName+"\\"+file1.getName(),fileName);
}else {
//处理后的fileName作为匹配规则,对遍历的文件进行匹配
Pattern pattern = Pattern.compile(fileName);
Matcher m = pattern.matcher(file1.getName());
if(m.matches()) {
fileList.add(dirName+"\\"+file1.getName());
}
}
}
}
}
}
- 非递归获取符合条件的文件的绝对路径(在Main.java中已对fileName进行通配符处理):
//仅获取当前目录下符合条件的文件,并将其绝对路径添加到ArrayList
public void getFiles(String dirName,String fileName) {
File file = new File(dirName);
if(file.isDirectory()) {
File[] files = file.listFiles();
if(files != null) {
for(File file1 : files) {
if(!file1.isDirectory()) {
Pattern pattern = Pattern.compile(fileName);
Matcher m = pattern.matcher(file1.getName());
if(m.matches()) {
fileList.add(dirName+"\\"+file1.getName());
}
}
}
}
}
}
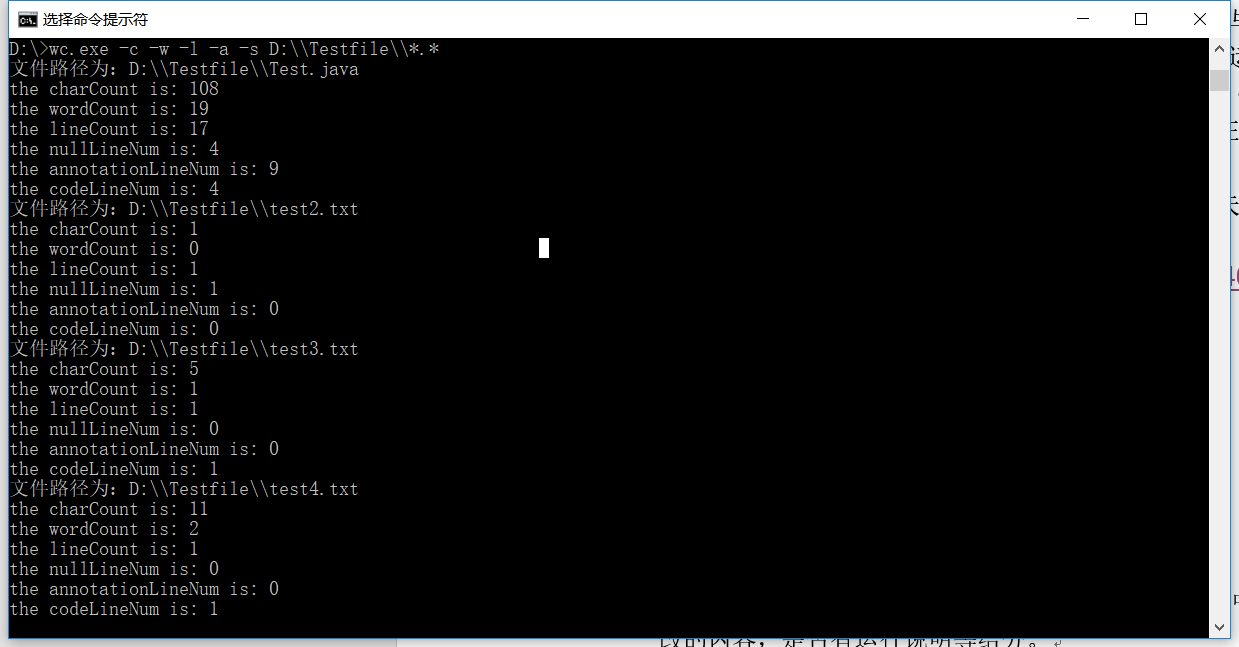
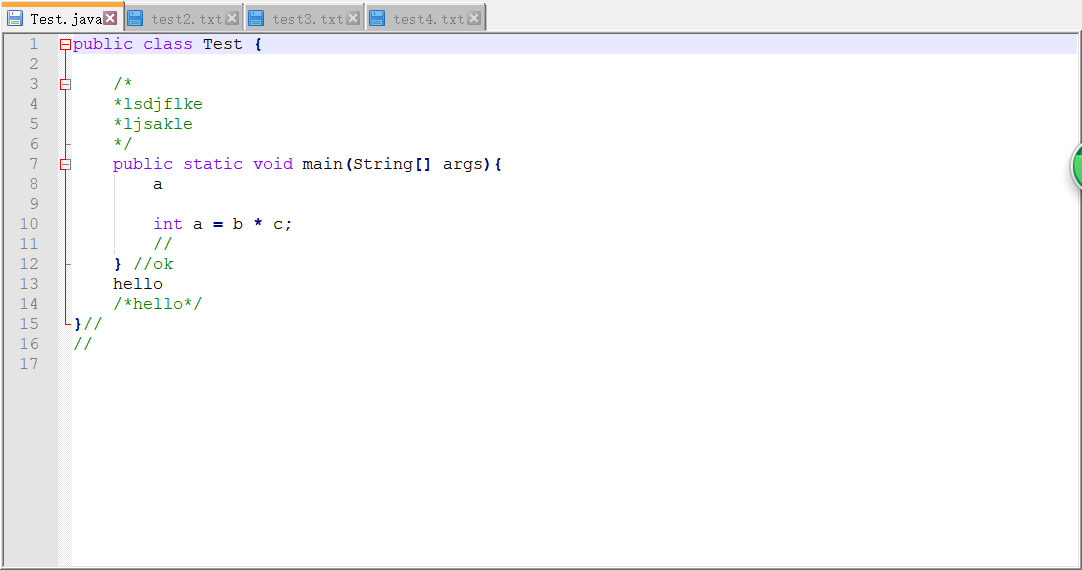
测试运行
项目小结
这次软件工程作业不仅让我了解到github、exe4j、单元测试等工具的使用,而且我也重新回顾了java和正则表达式的相关知识,在这个过程中,我初步体验到了一个项目开发的完整流程。在项目开发的初始,我急于实现各个功能的代码,导致后来各个函数调用之间存在难以对接以致多次修改的情况,之后我及时调整,按照软件开发的流程,逐步实现,最后得以完成。总的来说,我的编程能力和思维能力还有待提高,我会有计划的去学习java等知识。
Java实现WordCount的更多相关文章
- Spark:用Scala和Java实现WordCount
http://www.cnblogs.com/byrhuangqiang/p/4017725.html 为了在IDEA中编写scala,今天安装配置学习了IDEA集成开发环境.IDEA确实很优秀,学会 ...
- 软件工程:java实现wordcount基本功能
github链接:https://github.com/Nancy0611/wc 一:项目相关要求 该项目能统计文本文件的字符数.单词数和行数.这个项目要求写一个命令行程序,模仿已有wc.exe 的功 ...
- 个人项目———Java实现WordCount
2018年系统分析与设计—个人项目作业 题目来自于 :https://edu.cnblogs.com/campus/xnsy/2018Systemanalysisanddesign/homework/ ...
- MapReduce学习总结之java版wordcount实现
一.代码实现: package rdb.com.hadoop01.mapreduce; import java.io.IOException; import org.apache.hadoop.con ...
- java实现wordCount的map
打开IDEA,File--new --Project,新建一个项目 我们已经安装好了maven,不用白不用 这里不要选用骨架,Next.在写上Groupid,Next. 写上项目名称,finish.o ...
- demo1 spark streaming 接收 kafka 数据java代码WordCount示例
1. 首先启动zookeeper windows上的安装见zk 02之 Windows安装和使用zookeeper 启动后见: 2. 启动kafka windows的安装kafka见Windows上搭 ...
- spark streaming 接收 kafka 数据java代码WordCount示例
http://www.cnblogs.com/gaopeng527/p/4959633.html
- WordCount基于本地和java的使用
直接使用hadoop中的wordcount中的jar包进行使用 JAVA实现WordCount import java.io.IOException; import org.apache.hadoop ...
- Eclipse 执行成功的 Hadoop-1.2.1 WordCount 源码
万事开头难.最近在学习Hadoop,先是搭建各种版本环境,从2.2.0到2.3.0,再到1.2.1,终于都搭起来了,折腾了1周时间,之后开始尝试使用Eclipse编写小demo.仅复制一个现成的Wor ...
随机推荐
- t检验,T Test (Student’s T-Test)
1.什么是T test? t-test:比较数据的均值,告诉你这两者之间是否相同,并给出这种不同的显著性(即是否是因为偶然导致的不同) The t test (also called Student’ ...
- The Hard Thing About Hard Things
1.大多数的管理书籍都是告诉你如何做正确的事,不把事情搞砸.而好书是告诉你,当事情已经搞砸时,你该怎么办. 2.这是个个真实的世界,他们偷走了你的梦想,可你却不知道是谁偷的.
- 6.ZigZag Conversion(Graph, traverse)
The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows like ...
- 解决Lightmap在PC上与ios和Android上表现不同的问题
Lightmap在PC上与android和ios的区别以及解决方法 1. 问题描述 相信很多人碰到过Lightmap的一些问题: 烘培好Lightmap之后,在PC上看起来相当给力,而打包成ios或 ...
- SSH框架分模块开发
------------------siwuxie095 SSH 框架分模块开发 1.在 Spring 核心配置文件中配置多个内容,容易造成 配置混乱,不利于维护 「分模块开发主要针对 Spring ...
- iOS - swift项目接入bugly - 报错, 配置符号表,下载Java环境,
1.pod 安装,无需配置任何东西 2.终端找到路径: pod install 3.在 appdelegate 导入 import Bugly extension AppDelegate{ /// ...
- [leetcode]239. Sliding Window Maximum滑动窗口最大值
Given an array nums, there is a sliding window of size k which is moving from the very left of the a ...
- ADF 入门帮助
本文是由英文帮助翻译所得: 1>task flows “任务流 task flows”可以包括非可视化的组件,比如方法调用.“页片段 page fragment”可以运行在一个页面的某个局部区域 ...
- snowflake自增ID算法 (PHP版)
/** * SnowFlake ID Generator * Based on Twitter Snowflake to generate unique ID across multiple * da ...
- mysql中float、double、decimal三种类型,以及数值产生误差的原因
单精度浮点数用4字节(32bit)表示浮点数,采用IEEE754标准的计算机浮点数,在内部是用二进制表示的,如:7.22用32位二进制是表示不下的,所以就导致不精确了,存取会出现误差. mysql中f ...