Transformers for Graph Representation
Do Transformers Really Perform Badfor Graph Representation?
1 Introduction
作者们发现关键问题在于如何补回Transformer模型的自注意力层丢失掉的图结构信息!不同于序列数据(NLP, Speech)或网格数据(CV),图的结构信息是图数据特有的属性,且对图的性质预测起着重要的作用。
There are many attempts of leveraging Transformer into the graph domain, but the only effective way is replacing some key modules (e.g., feature aggregation) in classic GNN variants by the softmax attention[47,7,22,48,58,43,13]
- [47] Graph attention networks. ICLR, 2018.
- [7] Graph transformer for graph-to-sequence learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7464–7471, 2020.
- [22] Heterogeneous graph transformer. In Proceedings of The Web Conference 2020, pages 2704–2710, 2020.
- [48] Direct multi-hop attention based graph neural network.arXiv preprint arXiv:2009.14332, 2020.
- [58] Graph-bert: Only attention is needed forlearning graph representations.arXiv preprint arXiv:2001.05140, 2020.
- [43] Self-supervised graph transformer on large-scale molecular data. Advances in Neural Information ProcessingSystems, 33, 2020.
- [13] generalization of transformer networks to graphs. AAAI Workshop on Deep Learning on Graphs: Methods and Applications, 2021
- Centrality Encoding: capture the node importance in the graph. In particular, we leverage the degree centrality for the centrality encoding, where a learnable vectoris assigned to each node according to its degree and added to the node features in the input layer.
- Spatial Encoding: capture the structural relation between nodes.
- Edge Encoding
2 Graphormer
2.1 Structural Encodings in Graphormer
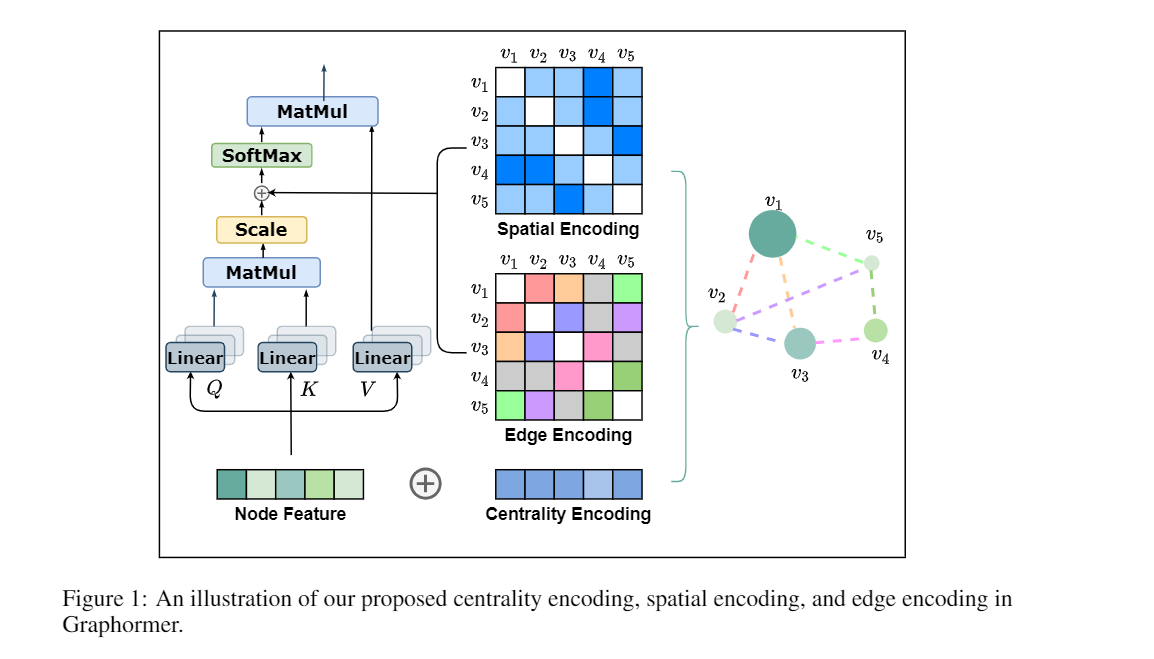
2.1.1 a Centrality Encoding
In Graphormer, we use the degree centrality, which is one of the standard centrality measures inliterature, as an additional signal to the neural network. To be specific, we develop a Centrality Encoding which assigns each node two real-valued embedding vectors according to its indegree and outdegree.

2.1.2 a Centrality Encoding
An advantage of Transformer is its global receptive field.
Spatial Encoding:
In this paper, we choose φ(vi,vj) to be the distance of the shortest path (SPD) between vi and vj if the two nodes are connected. If not, we set the output ofφto be a special value, i.e., -1. We assign each (feasible) output value a learnable scalar which will serve as a bias term in the self-attention module. Denote Aij as the (i,j)-element of the Query-Key product matrix A, we have:
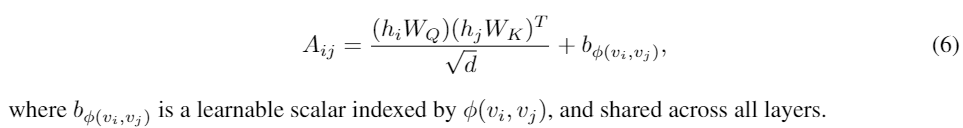
2.1.3 Edge Encoding in the Attention
In many graph tasks, edges also have structural features.
In the first method, the edge features areadded to the associated nodes’ features [21,29].
- [21] Open graph benchmark: Datasets for machine learning on graphs.arXiv preprintarXiv:2005.00687, 2020.
- [29] Deepergcn: All you need to train deepergcns.arXiv preprint arXiv:2006.07739, 2020
In the second method, for each node, its associated edges’ features will be used together with the node features in the aggregation [15,51,25].
- [51] How powerful are graph neural networks?InInternational Conference on Learning Representations, 2019.
- [25] Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
However, such ways of using edge feature only propagate the edge information to its associated nodes, which may not be an effective way to leverage edge information in representation of the whole graph.
a new edge encoding method in Graphormer:

3.2 Implementation Details of Graphormer
Graphormer Layer:
- MHA: multi-head self-attention (MHA)
- FFN: the feed-forward blocks
- LN: the layer normalization

Special Node:
生成一个VNODE连接图中所有的点,而它与所有节点的 spatial encodings 是 a distinct learnable scalar
3 Experiments
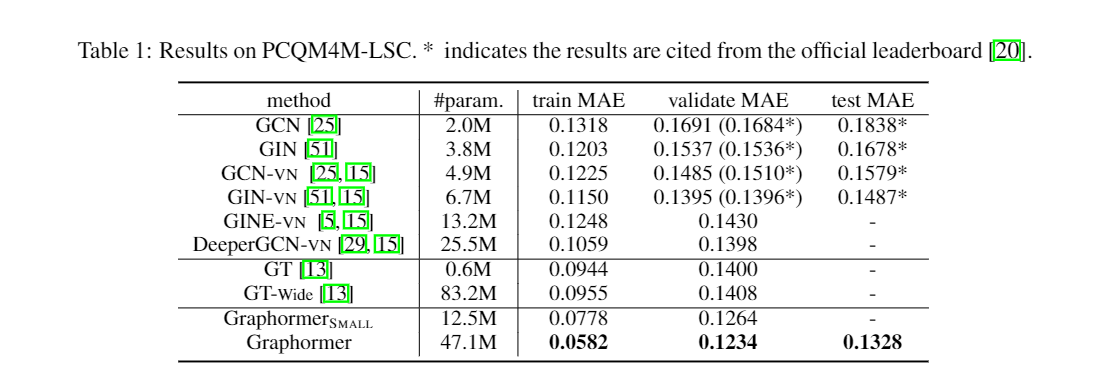
3.1 OGB Large-Scale Challenge
3.2 Graph Representation

Transformers for Graph Representation的更多相关文章
- 论文解读(Graphormer)《Do Transformers Really Perform Bad for Graph Representation?》
论文信息 论文标题:Do Transformers Really Perform Bad for Graph Representation?论文作者:Chengxuan Ying, Tianle Ca ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》2
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GRCCA)《 Graph Representation Learning via Contrasting Cluster Assignments》
论文信息 论文标题:Graph Representation Learning via Contrasting Cluster Assignments论文作者:Chun-Yang Zhang, Hon ...
- 论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息 论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning ...
- 论文解读(SUBG-CON)《Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning》
论文信息 论文标题:Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning论文作者:Yizhu Ji ...
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
随机推荐
- 使用C#进行数据库增删改查ADO.NET(一)
这节讲一下如何使用C#进行数据库的增删改查操作,本节以SQL Server数据库为例. .NET 平台,使用ADO.NET 作为与数据库服务器的桥梁,我们通过ADO.NET就可以使用C#语言操作数据库 ...
- Visual Studio/VS中任务列表的妙用
一.任务列表开启方法 首先说下开启的方法:视图-任务列表,即可打开任务列表. 快捷键Ctrl+'\'+T,熟练了可以快速开启.注意,'\'键是回车键上面的'',不要按成了'/' 二.任务列表标签设置 ...
- 吃透KVM创建虚机和KVM命令
1.创建虚拟机 1.1创建虚拟机磁盘 #使用qemu命令来创建磁盘 qemu-img create -f qcow2 /var/lib/libvirt/images/centos7.2.qcow2 2 ...
- bashshell删除列
删除所有空白列cat yum.log | awk '{$1=$2=$3=$4=null;print $0}'>>yum.log7删除文件中的所有空格sed -i s/[[:space:]] ...
- Linux——定时清空日志内容和删除日志文件
前言 最近在做性能压测试,会生成大量的日志,导致后续越压越慢,最终磁盘空间占满之类的问题.老是要手动删除日志文件,为避免此类问题发生,编写一个Linux日志定时清理的脚本,一劳永逸. 1.shell脚 ...
- Docker —— 使用 Dockerfile 制作 Jdk + Tomcat 镜像
一.准备好Jdk和Tomcat apache-tomcat-8.5.50.tar.gz jdk-8u212-linux-x64.tar.gz 注意: Jdk 和 Tomcat 记得从官网下载,否则制作 ...
- IT菜鸟之OSI七层模型
OSI七层模型从下到上分别是: 应用层 表示层 会话层 传输层 网络层 数据链路层 物理层 第一层物理层: 物理层是传输媒介(网线.无线.光纤) 在线路中起到的作用:是将0/1转换成电信号或光信号 物 ...
- 常用数据库连接池配置及使用(Day_11)
世上没有从天而降的英雄,只有挺身而出的凡人. --致敬,那些在疫情中为我们挺身而出的人. 运行环境 JDK8 + IntelliJ IDEA 2018.3 优点: 使用连接池的最主要的优点是性能.创 ...
- 看完这篇还不懂 MySQL 主从复制,可以回家躺平了~
大家好,我是小羽. 我们在平时工作中,使用最多的数据库就是 MySQL 了,随着业务的增加,如果单单靠一台服务器的话,负载过重,就容易造成宕机. 这样我们保存在 MySQL 数据库的数据就会丢失,那么 ...
- 安装jdk env
For centos yum list java-1.8.0-openjdk* yum -y install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk- ...