Hive笔记及配置
Hive
基于Hadoop的数据仓库工具;
将结构化的数据文件,映射为一张表,并提供类SQL查询功能;
本质:将HQL转化为MapReduce程序;
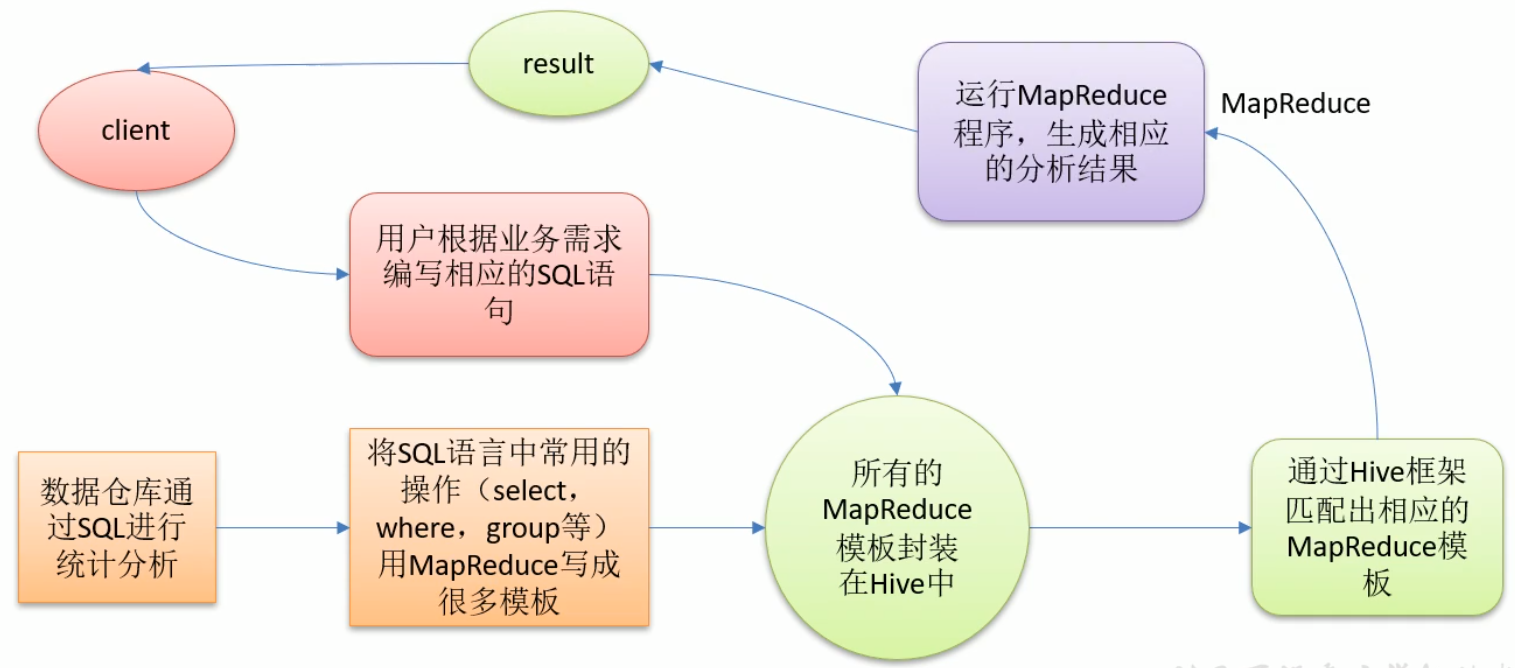

Hive处理的数据存储在HDFS;
Hive分析数据底层的默认实现是MapReduce;
执行程序是在Yarn上;
特点
Hive执行延迟高,适用于对实时性要求不高的场景;优势在于处理大数据,不适合处理小数据
(MR)不适合迭代式运算,不适合数据挖掘;
(MR)效率低;
调优困难,粒度太粗;
作为数据仓库的Hive,是读多写少,基本不修改;
没有索引,查询数据,要暴力扫描所有的数据(分区表可以减少搜索范围),延迟较高(主要由于MapReduce的框架本身延迟较高);
Hive配置
准备
hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/metastore?createDatabaseIfNotExist=true</value>
<description>metastore地址</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver name</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>whr</value>
<description>username</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<!--交互界面显示数据库名-->
</property>
</configuration>hive.env.sh
# 添加两个配置
HADOOP_HOME=/home/whr/workbench/hadoop
export HIVE_CONF_DIR=/home/whr/workbench/hive/conf初始化,也可以先创建数据库,这里有点简化了mysql的操作,mysql中的数据库以及用户权限要配置好,不然会初始化失败:
schematool -dbType mysql -initSchema
元数据
将derby元数据,放进mysql;
在mysql的hivedb中存在很多张表,记录着元数据代表着各种信息:
COLUMNS_V2 # 记录着列的信息
TBLS # 记录着已创建的表名以及创建时间,OWNER...
VERSION # hive版本信息
...
Hive笔记及配置的更多相关文章
- Hive学习笔记——基本配置及测试
1.什么是Hive Hive 是建立在 Hadoop上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在Hadoop中的大规模数据的机 ...
- hadoop2.2.0 + hbase 0.94 + hive 0.12 配置记录
一开始用hadoop2.2.0 + hbase 0.96 + hive 0.12 ,基本全部都配好了.只有在hive中查询hbase的表出错.以直报如下错误: java.io.IOException: ...
- 【转】hive简介安装 配置常见问题和例子
原文来自: http://blog.csdn.net/zhumin726/article/details/8027802 1 HIVE概述 Hive是基于Hadoop的一个数据仓库工具,可以将结构化 ...
- Hive的安装配置
Hive的安装配置 Hive的安装配置 安装前准备 下载Hive版本1.2.1: 1.[root@iZ28gvqe4biZ ~]# wget http://mirror.bit.edu.cn/apac ...
- Hive安装与配置详解
既然是详解,那么我们就不能只知道怎么安装hive了,下面从hive的基本说起,如果你了解了,那么请直接移步安装与配置 hive是什么 hive安装和配置 hive的测试 hive 这里简单说明一下,好 ...
- 《玩转Django2.0》读书笔记-Django配置信息
<玩转Django2.0>读书笔记-Django配置信息 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 项目配置是根据实际开发需求从而对整个Web框架编写相应配置信息. ...
- [hive] hive 安装、配置
一.hive安装 1.官网下载 1.2.2版本 http://apache.fayea.com/hive/hive-1.2.2/ 2. 解压,此处目录为 /opt/hadoop/hive-1.2.2 ...
- Hive安装与配置--- 基于MySQL元数据
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行. 其优点是学习成本低,可以通过 ...
- 【Hive一】Hive安装及配置
Hive安装及配置 下载hive安装包 此处以hive-0.13.1-cdh5.3.6版本的为例,包名为:hive-0.13.1-cdh5.3.6.tar.gz 解压Hive到安装目录 $ tar - ...
随机推荐
- Qt编写气体安全管理系统16-云端同步
一.前言 云端同步功能是为了后期的拓展做准备的,他的目的就是将本地的数据库中的记录,比如实时采集到的数据以及存储的运行记录等,同步到云端数据库上,默认采用阿里云的mysql数据库,阿里云速度还是挺快的 ...
- Django model中的save后的return
先给结论吧:在Django model的操作函数中,obj.save()后再执行return obj会返回obj的ID. 看例子: ... def create_session(self,bind_h ...
- 安卓apk反编译
在win环境反编译安卓APP的.apk文件 安卓apk 反编译为 Java源码图文教程 Android安全攻防战,反编译与混淆技术完全解析(上)
- mongodb多个条件查询in,日期查询,嵌套查询,统计集合总数等常用实例
1. 多个条件查询in in db.inventory.find( { qty: { $in: [ 5, 15 ] } } ) 2. 日期查询 db.books.find({}) 查询时间大于6-,结 ...
- HTML用table布局排版 padding清零
之前博文:HTML布局排版2如何设置div总是相对于页面居中 中是用div进行排版的,div是切了三条,顶部的图片,下部的图片,中间的平铺条,中间的div不设高度,根据内容,该区域的大小不固定,便于后 ...
- node.js web应用优化之读写分离
概述 先了解读写分离是什么,什么原理,解决了什么问题.什么是读写分离? 其实就是将数据库分为了主从库,一个主库用于写数据,多个从库完成读数据的操作,主从库之间通过某种机制进行数据的同步,是一种常见的数 ...
- tcp内存占用/socket内存占用
net.ipv4.tcp_mem 内核分配给TCP连接的内存,单位是Page,1 Page = 4096 Bytes,可用命令查看: #getconf PAGESIZE 4096 net.ipv4.t ...
- labelme2coco问题:TypeError: Object of type 'int64' is not JSON serializable
最近在做MaskRCNN 在自己的数据(labelme)转为COCOjson格式遇到问题:TypeError: Object of type 'int64' is not JSON serializa ...
- MongoDB 空间定位(点) 与 距离检索
转自: http://blog.csdn.net/flamingsky007/article/details/39208837 基于 MongoDB 2.6 GeoJSON 格式 { "ty ...
- [转帖]Linux运维工程师的十个基本技能点
Linux运维工程师的十个基本技能点 https://cloud.tencent.com/developer/article/1115068 本人是Linux运维工程师,对这方面有点心得,现在我说 ...