梯度下降(Gradient Descent)小结 -2017.7.20
在求解算法的模型函数时,常用到梯度下降(Gradient Descent)和最小二乘法,下面讨论梯度下降的线性模型(linear model)。
1.问题引入
给定一组训练集合(training set)yi,i = 1,2,...,m,引入学习算法参数(parameters of learning algorithm)θ1,θ2,.....,θn,构造假设函数(hypothesis function)h(x)如下:
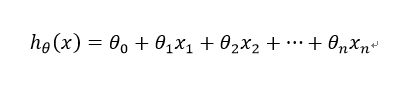
定义x0 = 1,则假设函数h(x)也可以记为以下形式:
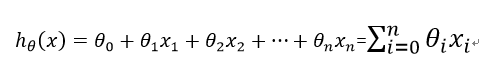
这里xi(i = 1,2,...,n)称为输入特征(input feature),n为特征数。
对于训练集合yi,要使假设函数h(x)拟合程度最好,就要使损失函数(loss function)J(θ)达到最小,J(θ)表达式如下:
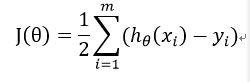
2.问题推导
目标是使J(θ)达到最小,此时的θ值即为所求参数,首先来看梯度下降的几何形式。
(1)梯度下降的几何形式

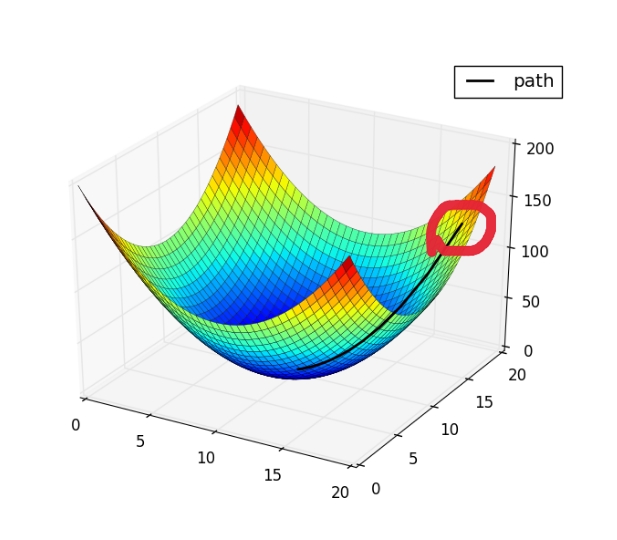
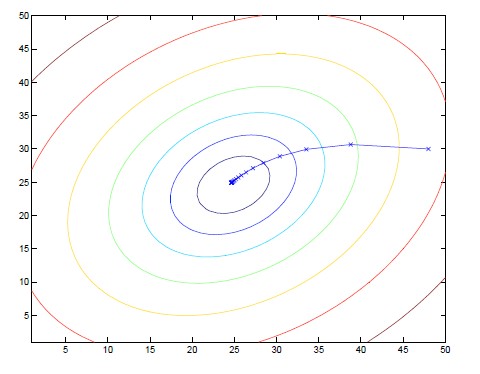
上图圈内点为初始设置的参考点,想象这是一座山的地形图,你站在参考点上准备下山,要从哪里走,下山的速度最快?选择一个方向,每次移动一小点步伐,直到移动到图正下方的蓝色区域,找到了局部最优解。显然,对于此图来说,设置的初始参考点不同,找到的局部最优解也不同。其实,真正的J(θ)大部分是如下图的形状,只有一个全局最优解:
(2)批量梯度下降(Batch Gradient Descent)法
方法是对θi进行多次迭代,迭代减去速率因子α(learning rate)乘以J(θ)对θi的偏导数。

下面推导过程取m = 1的特殊情况,即只有一个训练样本,并逐步推导至一般过程。
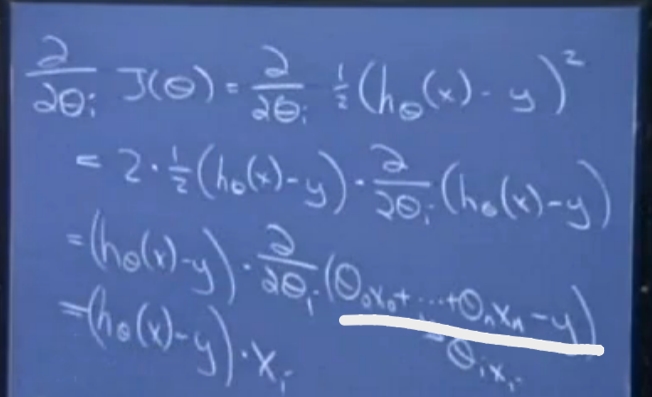
划线部分只有θixi与θi有关,得到的θi迭代表达式为:

推广至m个训练样本,则迭代表达式为:
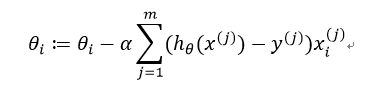
但批量梯度下降的每一次迭代都要遍历所有训练样本,不适用于训练样本数量极多的情况,于是提出了随机梯度下降(Stochastic Gradient Descent)法
(3)随机梯度下降(Stochastic Gradient Descent)法

每次都只使用第j个样本,速度比批量梯度下降快了很多。
(4)两种梯度下降方法比较
下面是两种梯度下降算法的迭代等高图
批量梯度下降:
随机梯度下降(紫色线所示):
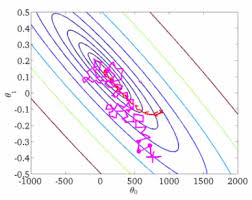
随机梯度下降的每次迭代,有可能变大或变小,但总体趋势接近全局最优解,通常参数值会十分接近最小值。
3.注意事项
(1)α的取值不宜太大或太小。
if α is too small then will take very tiny steps and take long time to converge;
if α is too large then the steepest descent may end up overshooting the minimum.
(2)由于向最优解收敛过程中偏导数会逐渐变小,收敛至最小值时偏导为0,则θi会逐渐变小,因此不需要改变α使其越来越小。
(3)α的取值需要不断测试更改,直至达到效果最好的α。
(4)当梯度下降到一定数值后,每次迭代的变化很小,这时可以设定一个阈值,只要变化小于该阈值,就停止迭代,而得到的结果也近似于最优解。
图片来源:百度
参考博客:http://www.cnblogs.com/ooon/p/4947688.html
梯度下降(Gradient Descent)小结 -2017.7.20的更多相关文章
- 机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent) 题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记. 梯度下降是线性回归的一种(Line ...
- 梯度下降(gradient descent)算法简介
梯度下降法是一个最优化算法,通常也称为最速下降法.最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的.最速下降法是用 ...
- (二)深入梯度下降(Gradient Descent)算法
一直以来都以为自己对一些算法已经理解了,直到最近才发现,梯度下降都理解的不好. 1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 ...
- CS229 2.深入梯度下降(Gradient Descent)算法
1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 目标是优化J(θ1),得到其最小化,下图中的×为y(i),下面给出TrainS ...
- 梯度下降(Gradient descent)
首先,我们继续上一篇文章中的例子,在这里我们增加一个特征,也即卧室数量,如下表格所示: 因为在上一篇中引入了一些符号,所以这里再次补充说明一下: x‘s:在这里是一个二维的向量,例如:x1(i)第i间 ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- 回归(regression)、梯度下降(gradient descent)
本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: 上次写过一篇 ...
- 吴恩达深度学习:2.3梯度下降Gradient Descent
1.用梯度下降算法来训练或者学习训练集上的参数w和b,如下所示,第一行是logistic回归算法,第二行是成本函数J,它被定义为1/m的损失函数之和,损失函数可以衡量你的算法的效果,每一个训练样例都输 ...
- (3)梯度下降法Gradient Descent
梯度下降法 不是一个机器学习算法 是一种基于搜索的最优化方法 作用:最小化一个损失函数 梯度上升法:最大化一个效用函数 举个栗子 直线方程:导数代表斜率 曲线方程:导数代表切线斜率 导数可以代表方向, ...
随机推荐
- 1.1.EJB概述
1.EJB概述: Enterprice JavaBeans是一个用于分布式业务应用的标准服务端组件模型.采用Enterprice JavaBeans架构编写的应用是可伸的.事务性的. 多用户安全的.采 ...
- python面向对象、类、socket网络编程
类和对象 python3统一了类与类型的概念:类==类型:从一组对象中提取相似的部分就是类:特征与技能的结合体就叫做对象: 类的功能: 初始实例化: 属性引用: 1.数据属性: 2.函数属性: 对于一 ...
- linux 远程配置docker加速器
https://www.jianshu.com/p/dca49964af04 curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh ...
- Java动态绑定与多态
在面向对象的程序设计语言中,多态是继数据抽象和继承之后的第三种基本特性.多态通过分离做什么和怎么做,从另一个角度将接口和实现分离开来.在一开始接触多态这个词的时候,我们或许会因为这个词本身而感到困惑, ...
- 源码安装 qemu-2.0.0 及其依赖 glib-2.12.12
源码安装qemu-2.0.0 下载源代码并解压 http://wiki.qemu-project.org/download/qemu-2.0.0.tar.bz2 .tar.gz 编译及安装: cd q ...
- App 仿淘宝:控制详情和购买须知样式切换,控制商品详情和购买须知选项卡的位置(固定在顶部还是正常)
CSS: <div id="details" ref="details" class="details" :class="t ...
- composer (一)
composer参考文档: composer中文网 安装composer: Windows安装:使用安装程序:https://docs.phpcomposer.com/00-intro.html#U ...
- jquery mouseenter()方法 语法
jquery mouseenter()方法 语法 作用:当鼠标指针穿过元素时,会发生 mouseenter 事件.该事件大多数时候会与 mouseleave 事件一起使用.mouseenter() 方 ...
- luogu3812 【模板】线性基
Code: #include <cstdio> #include <algorithm> #define ll long long #define N 64 #define s ...
- 9.一次简单的Web作业
Web作业 <!DOCTYPE html> <!-- 作业描述:由于引用了JQuery库,所以请在联网的时候打开该页面. 本次作业是在上次作业的基础上的进一步完善,上次作业页面预留的 ...