SVM回归
SVM回归任务是限制间隔违规情况下,尽量防止更多的样本在“街道”上。“街道”的宽度由超参数\(\epsilon\)控制
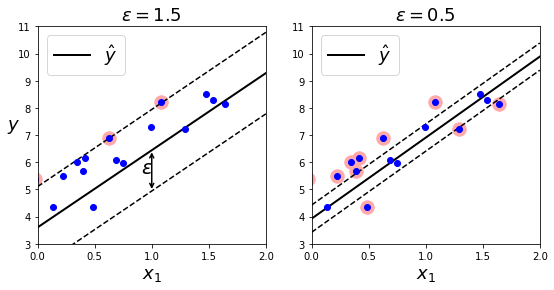
在随机生成的线性数据上,两个线性SVM回归模型,一个有较大的间隔(\(\epsilon=1.5\)),另一个间隔较小(\(\epsilon=0.5\)),训练情况如下:
代码如下:
造数据与训练:
np.random.seed(42)
m = 50
X = 2 * np.random.randn(m,1)
y = (4 + 3 * X + np.random.randn(m,1)).ravel()
from sklearn.svm import LinearSVR
svm_reg1 = LinearSVR(epsilon=1.5, random_state=42)
svm_reg2 = LinearSVR(epsilon=0.5, random_state=42)
svm_reg1.fit(X, y)
svm_reg2.fit(X,y)
可视化编码
def find_support_vectors(svm_reg, X, y):
y_pred = svm_reg.predict(X)
off_margin = (np.abs(y - y_pred) >= svm_reg.epsilon)
return np.argwhere(off_margin)
svm_reg1.support_ = find_support_vectors(svm_reg1, X, y)
svm_reg2.support_ = find_support_vectors(svm_reg2, X, y)
eps_x1 = 1
eps_y_pred = svm_reg1.predict([[eps_x1]])
def plot_svm_regression(svm_reg, X, y, axes):
x1s = np.linspace(axes[0], axes[1], 100).reshape(100, 1)
y_pred = svm_reg.predict(x1s)
plt.plot(x1s, y_pred, "k-", linewidth=2, label=r"$\hat{y}$")
plt.plot(x1s, y_pred + svm_reg.epsilon, "k--")
plt.plot(x1s, y_pred - svm_reg.epsilon, "k--")
plt.scatter(X[svm_reg.support_], y[svm_reg.support_], s=180, facecolors='#FFAAAA')
plt.plot(X, y, "bo")
plt.xlabel(r"$x_1$", fontsize=18)
plt.legend(loc="upper left", fontsize=18)
plt.axis(axes)
plt.figure(figsize=(9, 4))
plt.subplot(121)
plot_svm_regression(svm_reg1, X, y, [0, 2, 3, 11])
plt.title(r"$\epsilon = {}$".format(svm_reg1.epsilon), fontsize=18)
plt.ylabel(r"$y$", fontsize=18, rotation=0)
#plt.plot([eps_x1, eps_x1], [eps_y_pred, eps_y_pred - svm_reg1.epsilon], "k-", linewidth=2)
plt.annotate(
'', xy=(eps_x1, eps_y_pred), xycoords='data',
xytext=(eps_x1, eps_y_pred - svm_reg1.epsilon),
textcoords='data', arrowprops={'arrowstyle': '<->', 'linewidth': 1.5}
)
plt.text(0.91, 5.6, r"$\epsilon$", fontsize=20)
plt.subplot(122)
plot_svm_regression(svm_reg2, X, y, [0, 2, 3, 11])
plt.title(r"$\epsilon = {}$".format(svm_reg2.epsilon), fontsize=18)
plt.show()
可视化展示:
非线性拟合
造数据
np.random.seed(42)
m = 100
X = 2 * np.random.rand(m, 1) - 1
y = (0.2 + 0.1 * X + 0.5 * X**2 + np.random.randn(m, 1)/10).ravel()
from sklearn.svm import SVR
from sklearn.svm import SVR
svm_poly_reg1 = SVR(kernel="poly", degree=2, C=100, epsilon=0.1, gamma="auto")
svm_poly_reg2 = SVR(kernel="poly", degree=2, C=0.01, epsilon=0.1, gamma="auto")
svm_poly_reg1.fit(X, y)
svm_poly_reg2.fit(X, y)
可视化编程
plt.figure(figsize=(9, 4))
plt.subplot(121)
plot_svm_regression(svm_poly_reg1, X, y, [-1, 1, 0, 1])
plt.title(r"$degree={}, C={}, \epsilon = {}$".format(svm_poly_reg1.degree, svm_poly_reg1.C, svm_poly_reg1.epsilon), fontsize=18)
plt.ylabel(r"$y$", fontsize=18, rotation=0)
plt.subplot(122)
plot_svm_regression(svm_poly_reg2, X, y, [-1, 1, 0, 1])
plt.title(r"$degree={}, C={}, \epsilon = {}$".format(svm_poly_reg2.degree, svm_poly_reg2.C, svm_poly_reg2.epsilon), fontsize=18)
plt.show()
可视化展示:

SVM回归的更多相关文章
- SVM-支持向量机(三)SVM回归与原理
SVM回归 我们之前提到过,SVM算法功能非常强大:不仅支持线性与非线性的分类,也支持线性与非线性回归.它的主要思想是逆转目标:在分类问题中,是要在两个类别中拟合最大可能的街道(间隔),同时限制间隔侵 ...
- SVM – 回归
SVM的算法是很versatile的,在回归领域SVM同样十分出色的.而且和SVC类似,SVR的原理也是基于支持向量(来绘制辅助线),只不过在分类领域,支持向量是最靠近超平面的点,在回归领域,支持向量 ...
- svm使用的一般步骤
LIBSVM 使用的一般步骤是:1)准备数据集,转化为 LIBSVM支持的数据格式 :[label] [index1]:[value1] [index2]:[value2] ...即 [l类别标号] ...
- SVM流行库LIBSvm的使用和调参
简介:Libsvm is a simple, easy-to-use, and efficient software for SVM classification and regression. It ...
- 【机器学习】支持向量机(SVM)
感谢中国人民大学胡鹤老师,课程深入浅出,非常好 关于SVM 可以做线性分类.非线性分类.线性回归等,相比逻辑回归.线性回归.决策树等模型(非神经网络)功效最好 传统线性分类:选出两堆数据的质心,并做中 ...
- SVM的简单介绍
ng的MI-003中12 ——SVM 一.svm目标函数的由来 视频先将LR的损失函数: 在上图中,先将y等于0 和y等于1的情况集合到一起成为一个损失函数,然后分别讨论当y等于1的时候损失函数的结果 ...
- 吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用
import pandas as pd # 导入第三方模块from sklearn import svmfrom sklearn import model_selectionfrom sklearn ...
- SVM训练结果参数说明 训练参数说明 归一化加快速度和提升准确率 归一化还原
原文:http://blog.sina.com.cn/s/blog_57a1cae80101bit5.html 举例说明 svmtrain -s 0 -?c 1000 -t 1 -g 1 -r 1 - ...
- (一)使用sklearn做各种回归
#申明,本文章参考于 https://blog.csdn.net/yeoman92/article/details/75051848 import numpy as np import matplot ...
- SVM用于线性回归
SVM用于线性回归 方法分析 在样本数据集()中,不是简单的离散值,而是连续值.如在线性回归中,预测房价.与线性回归类型,目标函数是正则平方误差函数: 在SVM回归算法中,目的是训练出超平面,采用作为 ...
随机推荐
- 万字调研——AI生成内容检测
数据集 TweepFake 地址 摘要:深度伪造(deepfakes).合成或篡改媒体的威胁正变得越来越令人担忧,尤其是对于那些已经被指控操纵公众舆论的社交媒体平台而言.即使是最简单的文本生成技术(例 ...
- [Qt基础-07 QSignalMapper]
QSignalMapper 本文主要根据QT官方帮助文档以及日常使用,简单的介绍一下QSignalMapper的功能以及使用 文章目录 QSignalMapper 简介 使用方法 主要的函数 信号和槽 ...
- CNVD挖掘思路
CNVD挖掘思路 CNVD获取条件 首先,先来了解一下目前cnvd发证资格 1.事件型 事件型漏洞必须是三大运营商(移动.联通.电信)的中高危漏洞,或者党政机关.重要行业单位.科研院所.重要企事业单位 ...
- Calico Kernel's RPF check is set to 'loose'
前言 K8s 集群部署使用了 calico 网络插件,而calico node 节点发生如下报错: 2023-03-13 11:19:36.622 [FATAL][828] int_dataplane ...
- go string转int strconv包
前言 strconv 主要用于字符串和基本类型的数据类型的转换 s := "aa"+100 //字符串和整形数据不能放在一起 所以需要将 100 整形转为字符串类型 //+号在字符 ...
- 掌握 K8s Pod 基础应用 (二)
Pod生命周期 我们一般将pod对象从创建至终的这段时间范围称为pod的生命周期,它主要包含下面的过程: pod创建过程 运行初始化容器(init container)过程 运行主容器(main co ...
- Opencv环境配置一览
OpenCV环境配置一览 专业相关,平时经常会使用到opencv的一些函数,目前主要包括Ubuntu系统,Android系统,本篇文章介绍在两个系统下对应的环境配置策略. Ubuntu环境 附上一个很 ...
- 【Linux】3.10 进程管理(重点)
进程管理 1. 进程管理基础 在Linux中,每个执行的程序(代码)都称为一个进程.每个进程都分配一个ID号 每一个进程,都会对应一个父进程,而这个父进程可以复制多个子进程.例如www服务器. 每个进 ...
- study Rust-2【环境与配置,随机数】
Rust教程资料很多.但是,这是教程学习资料感觉挺好!推荐给你https://doc.rust-lang.org/stable/book/ (简体中文译本)在线阅读 学习rust开始有点感觉了.美好的 ...
- BotSharp + MCP 三步实现智能体开发
1. 简介 1.1 什么是MCP Model Context Protocol(MCP)模型上下文协议是一种标准化协议,它让大模型能够更容易地和外部的数据.工具连接起来.你可以把MCP想象成一个通用的 ...