(转)RL — Policy Gradient Explained
RL — Policy Gradient Explained
2019-05-02 21:12:57
This blog is copied from: https://medium.com/@jonathan_hui/rl-policy-gradients-explained-9b13b688b146

Photo by Alex Read
Policy Gradient Methods (PG) are frequently used algorithms in reinforcement learning (RL). The principle is very simple.
We observe and act.
A human takes actions based on observations. As a quote from Stephen Curry:
You have to rely on the fact that you put the work in to create the muscle memory and then trust that it will kick in. The reason you practice and work on it so much is so that during the game your instincts take over to a point where it feels weird if you don’t do it the right way.

Constant practice is the key to build muscle memory for athletes. For PG, we train a policy to act based on observations. The training in PG makes actions with high rewards more likely, or vice versa.
We keep what is working and throw away what is not.
In policy gradients, Curry is our agent.
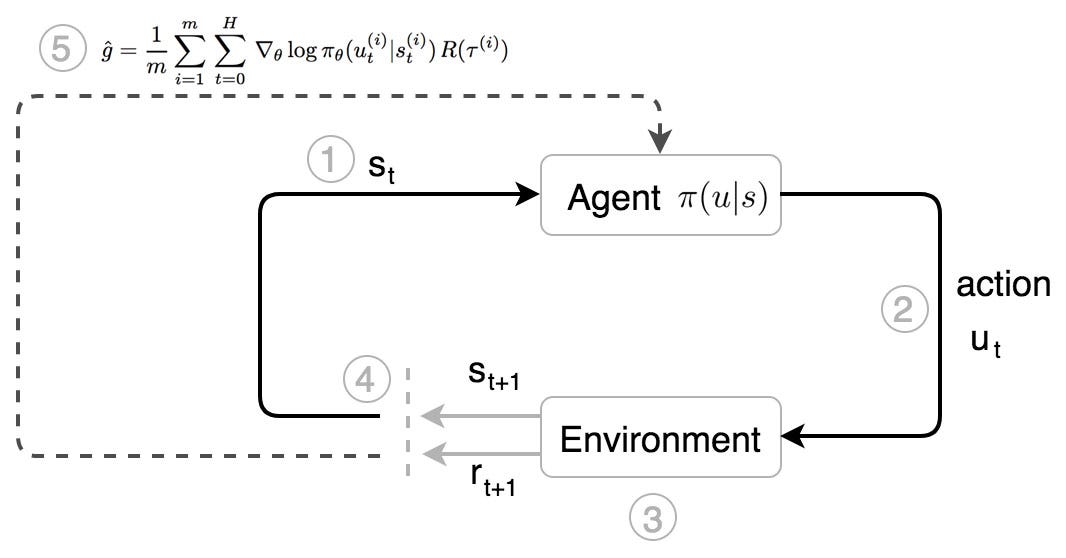
- He observes the state of the environment (s).
- He takes action (u) based on his instinct (a policy π) on the state s.
- He moves and the opponents react. A new state is formed.
- He takes further actions based on the observed state.
- After a trajectory τ of motions, he adjusts his instinct based on the total rewards R(τ) received.
Curry visualizes the situation and instantly knows what to do. Years of training perfects the instinct to maximize the rewards. In RL, the instinct may be mathematically described as:

the probability of taking the action u given a state s. π is the policy in RL. For example, what is the chance of turning or stopping when you see a car in front:

Objective
How can we formulate our objective mathematically? The expected rewards equal the sum of the probability of a trajectory × corresponding rewards:
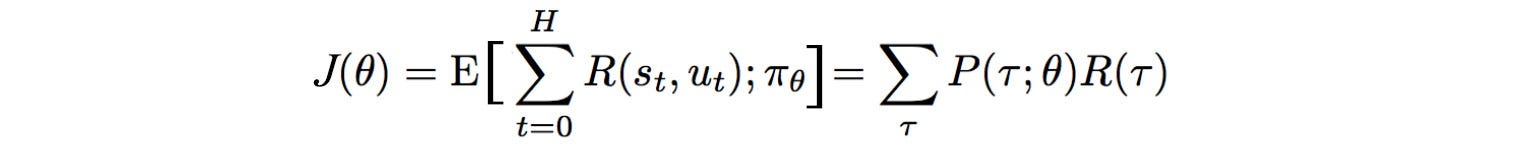
And our objective is to find a policy θ that create a trajectory τ

that maximizes the expected rewards.

Input features & rewards
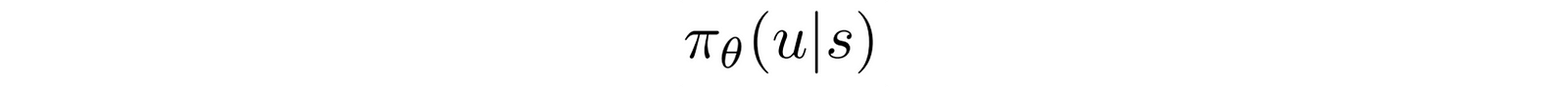
s can be handcrafted features for the state (like the joint angles/velocity of a robotic arm) but in some problem domains, RL is mature enough to handle raw images directly. π can be a deterministic policy which output the exact action to be taken (move the joystick left or right). π can be a stochastic policy also which outputs the possibility of an action that it may take.
We record the reward r given at each time step. In a basketball game, all are 0 except the terminate state which equals 0, 1, 2 or 3.
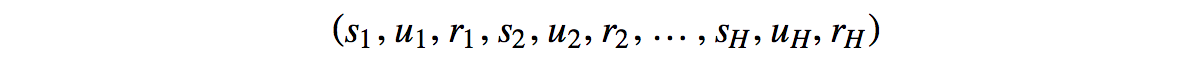
Let’s introduce one more term H called the horizon. We can run the course of simulation indefinitely (h→∞) until it reaches the terminate state, or we set a limit to H steps.
Optimization
First, let’s identify a common and important trick in Deep Learning and RL. The partial derivative of a function f(x) (R.H.S.) is equal to f(x) times the partial derivative of the log(f(x)).
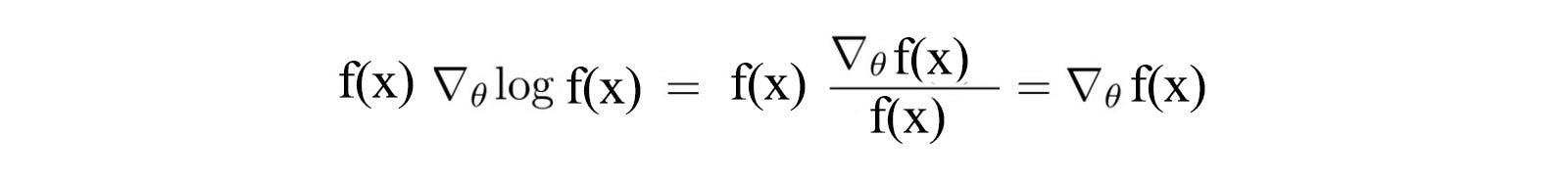
Replace f(x) with π.
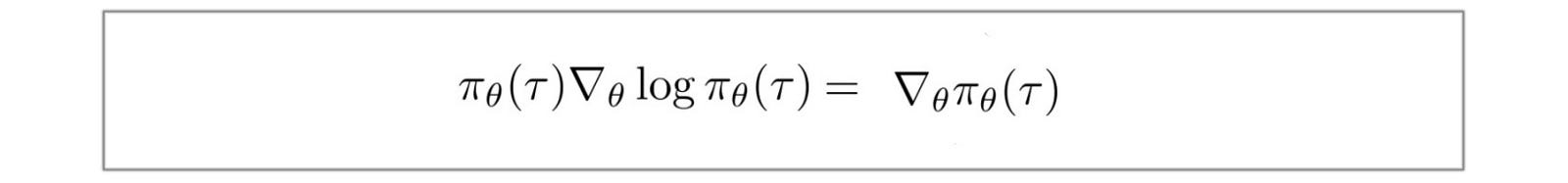
Also, for a continuous space, expectation can be expressed as:
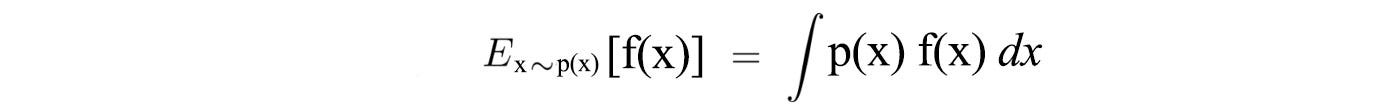
Now, let’s formalize our optimization problem mathematically. We want to model a policy that creates trajectories that maximize the total rewards.
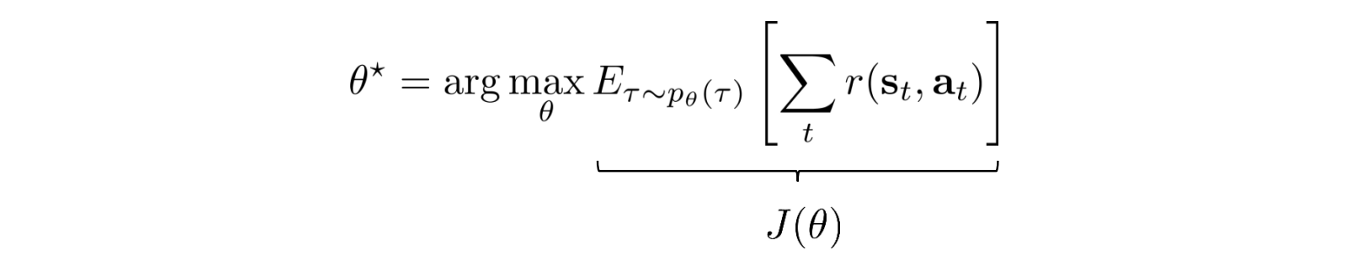
However, to use gradient descent to optimize our problem, do we need to take the derivative of the reward function r which may not be differentiable or formalized?
Let’s rewrite our objective function J as:

The gradient (policy gradient) becomes:

Great news! The policy gradient can be represented as an expectation. It means we can use sampling to approximate it. Also, we sample the value of rbut not differentiate it. It makes sense because the rewards do not directly depend on how we parameterize the model. But the trajectories τ are. So what is the partial derivative of the log π(τ).
π(τ) is defined as:
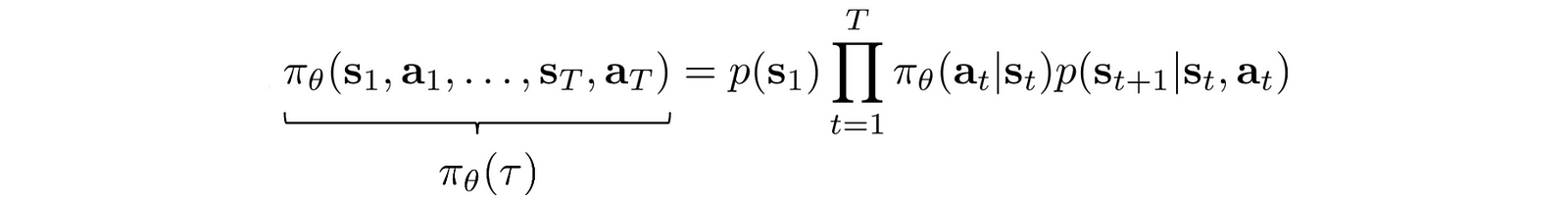
Take the log:

The first and the last term does not depend on θ and can be removed.
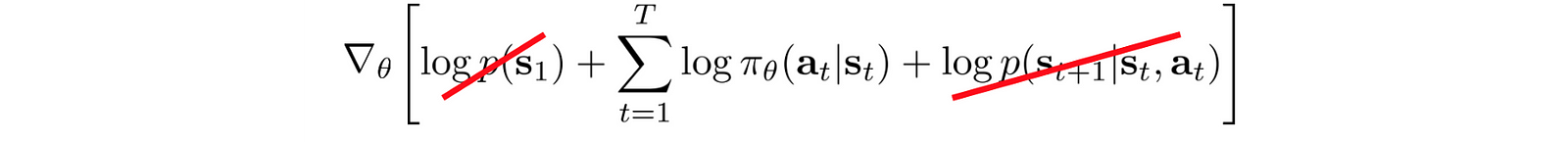
So the policy gradient

becomes:

And we use this policy gradient to update the policy θ.
Intuition

How can we make sense of these equations? The underlined term is the maximum log likelihood. In deep learning, it measures the likelihood of the observed data. In our context, it measures how likely the trajectory is under the current policy. By multiplying it with the rewards, we want to increase the likelihood of a policy if the trajectory results in a high positive reward. On the contrary, we want to decrease the likelihood of a policy if it results in a high negative reward. In short, keep what is working and throw out what is not.
If going up the hill below means higher rewards, we will change the model parameters (policy) to increase the likelihood of trajectories that move higher.

There is one thing significant about the policy gradient. The probability of a trajectory is defined as:
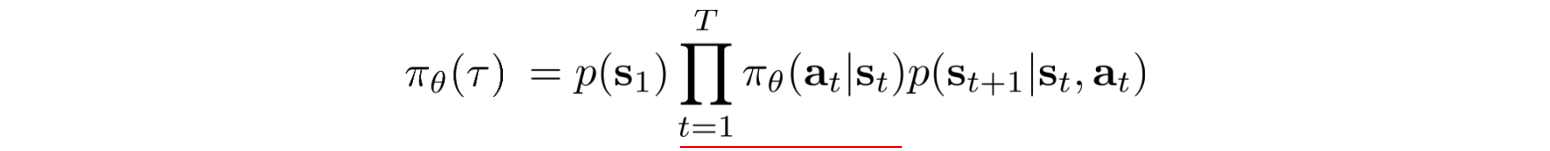
States in a trajectory are strongly related. In Deep Learning, a long sequence of multiplication with factors that are strongly correlated can trigger vanishing or exploding gradient easily. However, the policy gradient only sums up the gradient which breaks the curse of multiplying a long sequence of numbers.

The trick
creates a maximum log likelihood and the log breaks the curse of multiplying a long chain of policy.
Policy Gradient with Monte Carlo rollouts
Here is the REINFORCE algorithm which uses Monte Carlo rollout to compute the rewards. i.e. play out the whole episode to compute the total rewards.

Policy gradient with automatic differentiation
The policy gradient can be computed easily with many Deep Learning software packages. For example, this is the partial code for TensorFlow:

Yes, as often, coding looks simpler than the explanations.
Continuous control with Gaussian policies
How can we model a continuous control?

Let’s assume the values for actions are Gaussian distributed

and the policy is defined using a Gaussian distribution with means computed from a deep network:

With
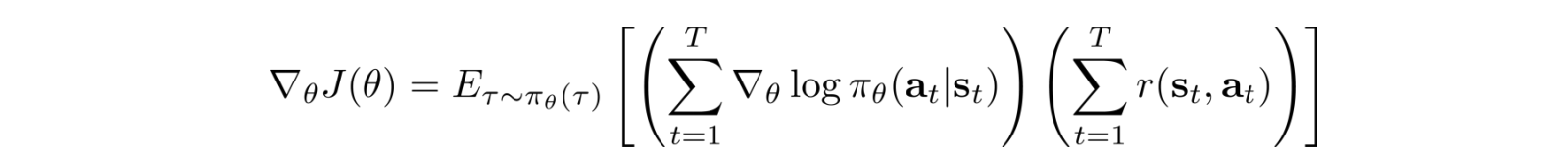
We can compute the partial derivative of the log π as:

So we can backpropagate

through the policy network π to update the policy θ. The algorithm will look exactly the same as before. Just start with a slightly different way in calculating the log of the policy.

Policy Gradients improvements
Policy Gradients suffer from high variance and low convergence.
Monte Carlo plays out the whole trajectory and records the exact rewards of a trajectory. However, the stochastic policy may take different actions in different episodes. One small turn can completely alter the result. So Monte Carlo has no bias but high variance. Variance hurts deep learning optimization. The variance provides conflicting descent direction for the model to learn. One sampled rewards may want to increase the log likelihood and another may want to decrease it. This hurts the convergence. To reduce the variance caused by actions, we want to reduce the variance for the sampled rewards.

Increasing the batch size in PG reduces variance.
However, increasing the batch size significantly reduces sample efficiency. So we cannot increase it too far, we need additional mechanisms to reduce the variance.
Baseline

We can always subtract a term to the optimization problem as long as the term is not related to θ. So instead of using the total reward, we subtract it with V(s).

We define the advantage function A and rewrite the policy gradient in terms of A.
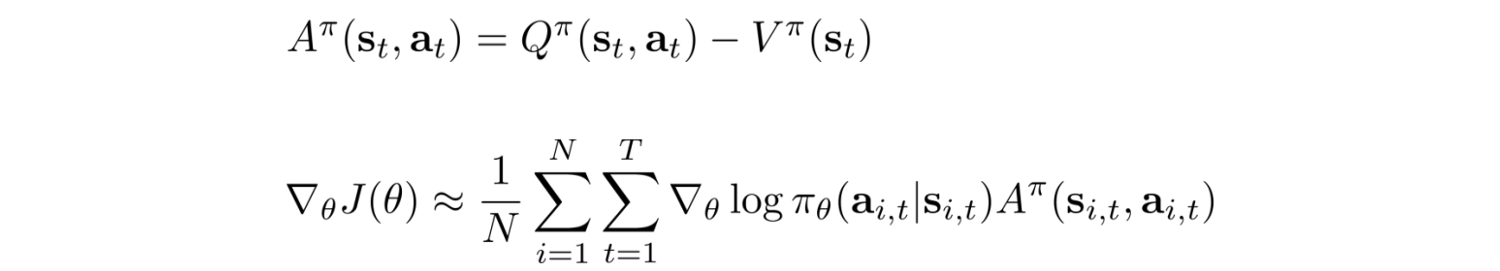
In deep learning, we want input features to be zero-centered. Intuitively, RL is interested in knowing whether an action is performed better than the average. If rewards are always positive (R>0), PG always try to increase a trajectory probability even if it receives much smaller rewards than others. Consider two different situations:
- Situation 1: Trajectory A receives+10 rewards and Trajectory B receives -10 rewards.
- Situation 2: Trajectory A receives +10 rewards and Trajectory B receives +1 rewards.
In the first situation, PG will increase the probability of Trajectory A while decreasing B. In the second situation, it will increase both. As a human, we will likely decrease the likelihood of trajectory B in both situations.
By introducing a baseline, like V, we can recalibrate the rewards relative to the average action.
Vanilla Policy Gradient Algorithm
Here is the generic algorithm for the Policy Gradient Algorithm using a baseline b.
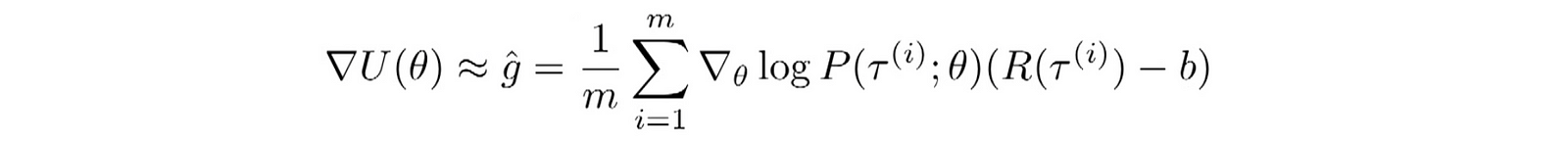

Causality
Future actions should not change past decision. Present actions only impact the future. Therefore, we can change our objective function to reflect this also.

Reward discount
Reward discount reduces variance which reduces the impact of distant actions. Here, a different formula is used to compute the total rewards.
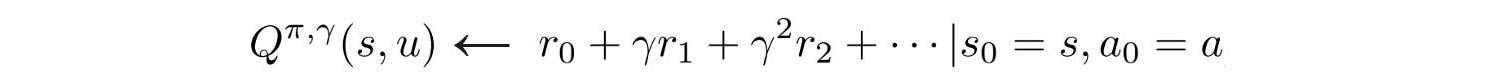
And the corresponding objective function becomes:
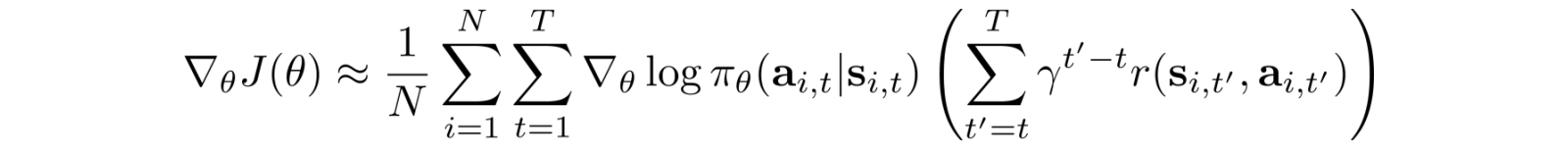
Part 2
This ends part 1 of the policy gradient methods. In the second part, we continue on the Temporal Difference, Hyperparameter tuning, and importance sampling. Temporal Difference will further reduce the variance and the importance sampling will lay down the theoretical foundation for more advanced policy gradient methods like TRPO and PPO.
Credit and references
(转)RL — Policy Gradient Explained的更多相关文章
- DRL之:策略梯度方法 (Policy Gradient Methods)
DRL 教材 Chpater 11 --- 策略梯度方法(Policy Gradient Methods) 前面介绍了很多关于 state or state-action pairs 方面的知识,为了 ...
- [Reinforcement Learning] Policy Gradient Methods
上一篇博文的内容整理了我们如何去近似价值函数或者是动作价值函数的方法: \[ V_{\theta}(s)\approx V^{\pi}(s) \\ Q_{\theta}(s)\approx Q^{\p ...
- 论文笔记之:SeqGAN: Sequence generative adversarial nets with policy gradient
SeqGAN: Sequence generative adversarial nets with policy gradient AAAI-2017 Introduction : 产生序列模拟数 ...
- 强化学习七 - Policy Gradient Methods
一.前言 之前我们讨论的所有问题都是先学习action value,再根据action value 来选择action(无论是根据greedy policy选择使得action value 最大的ac ...
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- Policy Gradient Algorithms
Policy Gradient Algorithms 2019-10-02 17:37:47 This blog is from: https://lilianweng.github.io/lil-l ...
- Ⅶ. Policy Gradient Methods
Dictum: Life is just a series of trying to make up your mind. -- T. Fuller 不同于近似价值函数并以此计算确定性的策略的基于价 ...
- 强化学习(十三) 策略梯度(Policy Gradient)
在前面讲到的DQN系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习.这种Value Based强化学习方法在很多领域都得到比较好的应用,但是Value Based强化学习方法也有很 ...
- 强化学习--Policy Gradient
Policy Gradient综述: Policy Gradient,通过学习当前环境,直接给出要输出的动作的概率值. Policy Gradient 不是单步更新,只能等玩完一个epoch,再 ...
随机推荐
- PyCharm-安装&调试
windows安装pycharm 和python的链接: PyCharm:http://www.jetbrains.com/pycharm/ Python:https://www.python.org ...
- 六、MySQL系列之数据备份(六)
本篇主要介绍用户授权.以及数据备份等知识: 一.用户授权 首先我们需要知道的是: 所有的用户及权限信息都存储在mysql数据库下的user表中,故我们可以通过查看user表的记录来查看用户权限信息,当 ...
- CentOS7怎样安装Jenkins
参考 http://pkg.jenkins-ci.org/redhat/ wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins-ci.org ...
- 最小哈希 minhash
最小哈希 维基百科,自由的百科全书 跳到导航跳到搜索 在计算机科学领域,最小哈希(或最小哈希式独立排列局部性敏感哈希)方法是一种快速判断两个集合是否相似的技术.这种方法是由Andrei Bro ...
- Java精通并发-notify方法详解及线程获取锁的方式分析
wait(): 在上一次https://www.cnblogs.com/webor2006/p/11404521.html中对于无参数的wait()方法的javadoc进行了解读,而它是调用了一个参数 ...
- Java中使用BufferedReader的readLine()方法和read()方法来读取文件内容
目标:读文件 编程时,有很多时候需要读取本地文件,下面介绍一下读取方式: 读单行文件 package com; import java.io.*; import java.util.ArrayList ...
- PHP——最新号码归属地数据库
前言 最近在忙的一个项目,为了数据安全,不能够使用任何第三方的接口~ 号码库 | https://github.com/wangyang0210/Phone-Number-Range 代码 其实就是一 ...
- js中number常用方法
toFixed() 将数字四舍五入为指定小数位数的数字,参数值范围为[0,20],表示四舍五入后保留的小数位数,如果没有传入参数,默认参数值等于整数,没有小数点. toprecision():用于将数 ...
- 瀑布流(基于Django)
# 后端 from django.shortcuts import render, HttpResponse from django.http import JsonResponse from app ...
- VOJ 1049送给圣诞夜的礼物——矩阵快速幂模板
题意 顺次给出 $m$个置换,反复使用这 $m$ 个置换对一个长为 $n$ 初始序列进行操作,问 $k$ 次置换后的序列.$m<=10, k<2^31$. 题目链接 分析 对序列的置换可表 ...