【Python3爬虫】百度一下,坑死你?
一、写在前面
这个标题是借用的路人甲大佬的一篇文章的标题(百度一下,坑死你),而且这次的爬虫也是看了这篇文章后才写出来的,感兴趣的可以先看下这篇文章。
前段时间有篇文章《搜索引擎百度已死》引起了很多讨论,而百度对此的回复是:百家号的内容在百度搜索结果中不超过10%。但是这个10%是第一页的10%还是所有数据的10%,我们不得而知,但是由于很多人都只会看第一页的内容,而如果这第一页里有十分之一的内容都来自于百家号,那搜索体验恐怕不怎么好吧?然后我这次写的爬虫就是把百度上面的热搜事件都搜索一下,然后把搜索结果的第一页上的标题链接提取出来,最后对这些链接进行一些简单的分析,看看百家号的内容占比能有多少。
二、具体步骤
1.页面分析
首先打开网页查看百度的热点事件,页面如下:
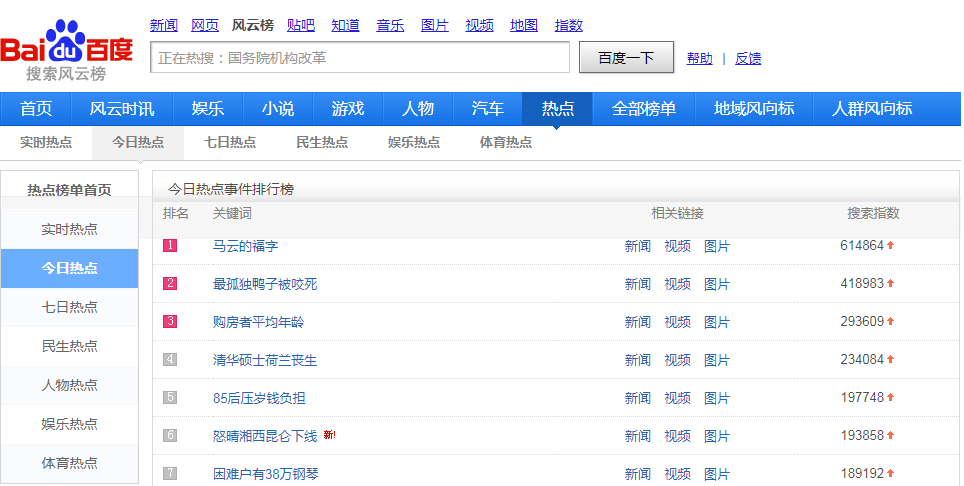
这次我主要对今日热点、娱乐热点、体育热点进行了爬取,每个热点下面有50条热点事件,然后对每个事件进行搜索,比如第一条--马云的福字:
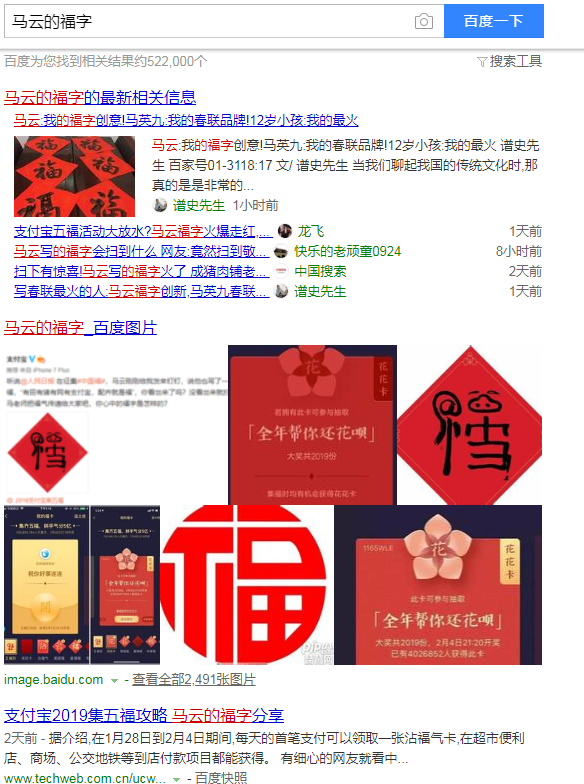
可以看到搜索结果的第一页上有很多标题,然后对这些标题的链接进行爬取,再保存到一个txt文件里,最后对这些数据进行分析。
2.主要代码
(1)获取真实链接
这些搜索结果页面上的链接都是经过加密的,如下图:
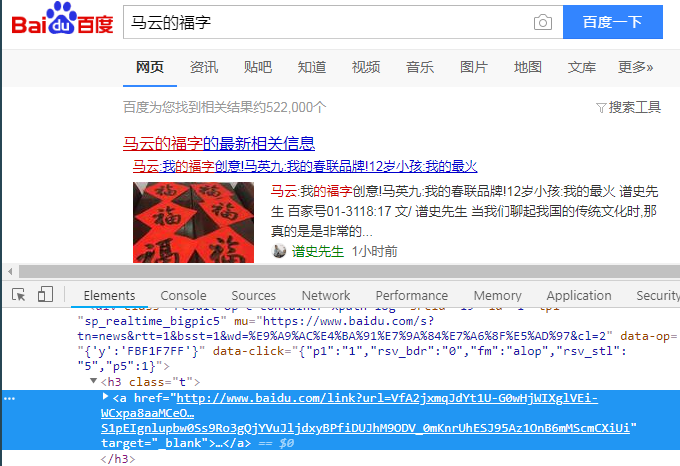
所以我们爬取得到的链接都是http://www.baidu.com/link?url=VfA2jxmqJdYt1U-G0wHjWIXglVEi-WCxpa8aaMCeOzkqK-c5CgYngPiJT6_-kmWE3ePTHCpgYlX5oq9SQDJgEukKCY19o26JlS1pEIgnlupbw0Ss9Ro3gQjYVuJljdxyBPfiDUJhM9ODV_0mKnrUhESJ95Az1OnB6mMScmCXiUi这种,但是我们点进去之后就能得到真实的链接https://www.baidu.com/s?tn=news&rtt=1&bsst=1&wd=%E9%A9%AC%E4%BA%91%E7%9A%84%E7%A6%8F%E5%AD%97&cl=2&origin=ps,那我们要怎么得到真实的链接呢?相关代码如下:
def get_real_url(self, fake_url):
# 获取真实的链接
try:
res = requests.get(fake_url, headers=self.headers)
real_url = res.url
except Exception as e:
print(e)
(2)数据处理
这里我总共爬取了1051条链接,如下图:
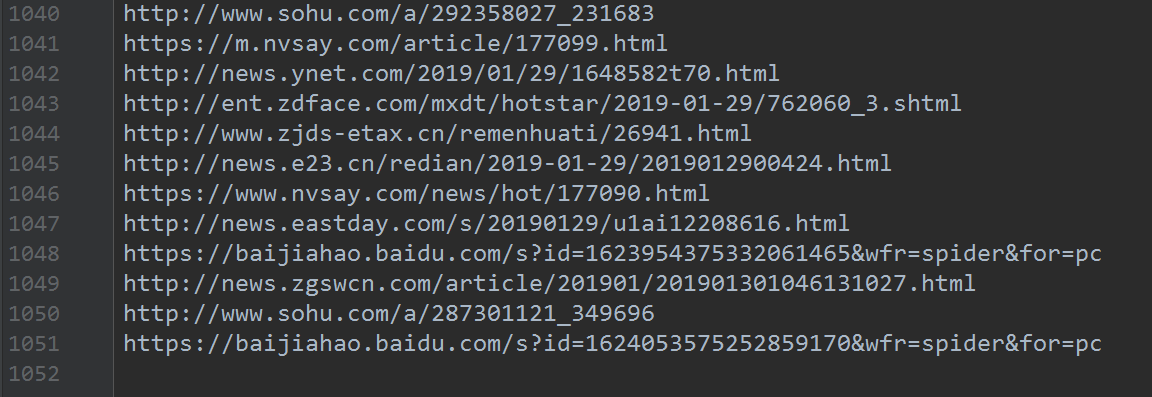
但是这样的数据是明显没有办法进行分析的,所以需要进行一下处理,比如将https://baijiahao.baidu.com/s?id=1624053575252859170&wfr=spider&for=pc变成baijiahao.baidu,相关代码如下:
href = "https://baijiahao.baidu.com/s?id=1624053575252859170&wfr=spider&for=pc"
match = re.match("(http[s]?://.+?[com,cn,net]/)", href)
href = match.group()
href = href.replace('cn', 'com').replace('net', 'com')
href = href[href.index(':') + 3:].rstrip('.com/')
print(href)
# baijiahao.baidu
(3)数据分析
这里主要使用了matplotlib绘图帮助我们分析数据。首先需要统计出各个网站出现的次数,然后进行一个排序,得到排名前十的网站,结果如下(前面是网站,后面是出现次数):
https://baijiahao.baidu.com/ 188
https://www.baidu.com/ 114
http://www.sohu.com/ 60
https://news.china.com/ 29
http://www.guangyuanol.cn/ 27
http://image.baidu.com/ 24
http://3g.163.com/ 20
https://sports.qq.com/ 19
https://www.iqiyi.com/ 17
https://baike.baidu.com/ 17
可以看到百家号出现的次数是最多的。然后进行绘图分析,这里主要是绘图的代码,因为使用的是百分数,所以在绘图的时候会稍微麻烦一点:
def plot(self, index_list, value_list):
b = self.ax.barh(range(len(index_list)), value_list, color='blue', height=0.8)
# 添加数据标签
for rect in b:
w = rect.get_width()
self.ax.text(w, rect.get_y() + rect.get_height() / 2, '{}%'.format(w),
ha='left', va='center')
# 设置Y轴刻度线标签
self.ax.set_yticks(range(len(index_list)))
self.ax.set_yticklabels(index_list)
# 设置X轴刻度线
lst = ["{}%".format(i) for i in range(0, 20, 2)]
self.ax.set_xticklabels(lst) plt.subplots_adjust(left=0.25)
plt.xlabel("占比")
plt.ylabel("网站")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.savefig("bjh.jpg")
print("已保存为bjh.jpg!")
三、运行结果
由于每个事件的搜索结果都是不同的,所以在解析网页的时候可能会出错,然后就是请求频率太高了会被ban掉,而且有时候UA会被识别出来然后就被ban掉了,运行情况如下图:

最后看一下绘制出来的图片:

可以看到百家号的内容占比达到了17%,而排在第二的也是百度自家的产品,内容占比也达到了10%。当然了,由于搜索的都是百度上的热搜事件,所以得到的结果百度自家的内容会多一点,但是光百家号的内容就占了17%,是不是也太多了点呢?
完整代码已上传到GitHub!
【Python3爬虫】百度一下,坑死你?的更多相关文章
- python3爬虫中文乱码之请求头‘Accept-Encoding’:br 的问题
当用python3做爬虫的时候,一些网站为了防爬虫会设置一些检查机制,这时我们就需要添加请求头,伪装成浏览器正常访问. header的内容在浏览器的开发者工具中便可看到,将这些信息添加到我们的爬虫代码 ...
- python3爬虫(4)各种网站视频下载方法
python3爬虫(4)各种网站视频下载方法原创H-KING 最后发布于2019-01-09 11:06:23 阅读数 13608 收藏展开理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够 ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- Python3 爬虫之 Scrapy 核心功能实现(二)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的搭建过程请参照本人的另一篇博客:Python3 爬虫之 Scrap ...
- Python3 爬虫之 Scrapy 框架安装配置(一)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scr ...
- python3爬虫--反爬虫应对机制
python3爬虫--反爬虫应对机制 内容来源于: Python3网络爬虫开发实战: 网络爬虫教程(python2): 前言: 反爬虫更多是一种攻防战,针对网站的反爬虫处理来采取对应的应对机制,一般需 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- Python3爬虫:(一)爬取拉勾网公司列表
人生苦短,我用Python 爬取原因:了解一下Python工程师在北上广等大中城市的薪资水平与入职前要求. Python3基础知识 requests,pyquery,openpyxl库的使用 爬取前的 ...
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
随机推荐
- 关于Random(47)与randon.nextInt(100)的区别
参考https://blog.csdn.net/md_shmily92/article/details/44059313 相关文章random.nextInt()与Math.random()基础用法 ...
- WPF 列表开启虚拟化的方式
正确开启虚拟化的方式 列表如ListBox,ListView,TreeView,GridView等,开启虚拟化 ScrollViewer设置CanContentScroll=True 直接在模板中,设 ...
- SQL数据库的一些操作
--以 MySQL为例 //登陆 mysql -u root -p //创建一个名为test_lib的数据库 CREATE DATABASE test_lib //删除一个名为test_lib的数据库 ...
- 张高兴的 Windows 10 IoT 开发笔记:串口红外编解码模块 YS-IRTM
This is a Windows 10 IoT Core project on the Raspberry Pi 2/3, coded by C#. GitHub: https://github.c ...
- Java开源生鲜电商平台-优惠券设计与架构(源码可下载)
Java开源生鲜电商平台-优惠券设计与架构(源码可下载) 说明:现在电商白热化的程度,无论是生鲜电商还是其他的电商等等,都会有促销的这个体系,目的就是增加订单量与知名度等等 那么对于Java开源生鲜电 ...
- pyqt5将图片插入面板
from PyQt5.QtWidgets import * from PyQt5 import QtCore,QtWidgets from PyQt5.QtGui import * import sy ...
- Vue学习小结(二)
接上一批,小结(二). 三.导航内容(含左侧导航及顶部面包屑导航) 其实导航条主要根据element-ui的教程进行编写,官网:http://element-ui.cn/#/zh-CN/compone ...
- 十分钟学会Java8的lambda表达式和Stream API
01:前言一直在用JDK8 ,却从未用过Stream,为了对数组或集合进行一些排序.过滤或数据处理,只会写for循环或者foreach,这就是我曾经的一个写照. 刚开始写写是打基础,但写的多了,各种乏 ...
- Scala脚本化-Ammonite
Scala语言定义: Scala combines object-oriented and functional programming in one concise, high-level lang ...
- 网络协议 22 - RPC 协议(下)- 二进制类 RPC 协议
前面我们认识了两个常用文本类的 RPC 协议,对于陌生人之间的沟通,用 NBA.CBA 这样的缩略语,会使得协议约定非常不方便. 在讲 CDN 和 DNS 的时候,我们讲过接入层的设计 ...