用Python实现支持向量机并处理Iris数据集
SVM全称是Support Vector Machine,即支持向量机,是一种监督式学习算法。它主要应用于分类问题,通过改进代码也可以用作回归。所谓支持向量就是距离分隔面最近的向量。支持向量机就是要确保这些支持向量距离超平面尽可能的远以保证模型具有相当的泛化能力。
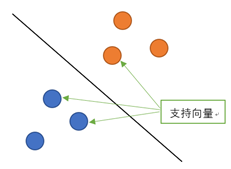
当训练数据线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性分类器,即线性支持向量机;当训练数据线性不可分时,通过使用核技巧,将低维度的非线性问题转化为高维度下的线性问题,学习得到非线性支持向量机。
所谓核技巧就是将低维数据映射到高维空间的办法。如果原始数据是有限维的,那么一定存在一个高维特征空间使样本可分。

支持向量机的一些证明推导公式不在这里说明。我简单说明一下支持向量机在Python中的实现。
在Python中sklearn算法包已经实现了所有基本机器学习的算法。直接from sklearn import svm就可以调用该算法。
以Iris数据集为例,从UCI数据库(archive.ics.uci.edu)中下载的data文件比较工整,无需做进一步处理可以直接使用。
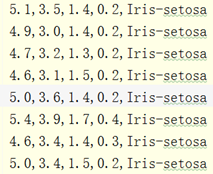
从网上其他地方下载下来的csv格式数据集可能比较混乱,如下图:

这种有样本序号有列名的数据集需要预处理一下才方便做实验。处理时需要导入pandas,将csv格式转换成便于处理的DataFrame格式。

其中names是设置列名称。
然后是使用drop方法消除原数据集中的第一行(列名称)以及第一列(样本序号)。

其中('a',axis=1)代表消除的是列名称为a的一整列。(0 ,axis=0)代表消除第0行。
最后使用to_csv方法输出文件即可处理完毕。

其中'newiris.csv'是指生成文件名,sep指的是分割符号(空格为\t),index为行索引(即序列号),header为列名称。
处理结果如下:

接下来开始SVM实验。首先读取我们刚才处理好的数据集。具体方法是使用numpy中的loadtxt方法此方法可以读取txt、csv、data格式的数据。

第一个位置path指的文件路径,dtype指的是读出来的数据类型,delimiter指的是分隔符,converters指的是将数据列与转换函数进行映射的字典。
我们数据的第五列显然不是float类型,因此要写一个函数进行转换。

读取后的结果如下:

接下来需要将读取到的数据集特征指标与结果分开,并划分为训练集与测试集,此处为了方便作图只取了前两列特征值做实验:

其中size指的是样本数量,若此数小于1表示样本比例,大于1的整数表示样本数量。random_state指的是随机数的种子。
准备好后就可以开始训练SVM了。

kernel指的是核函数rbf是高斯核。高斯核的gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。linear为线性核。线性核C越大分类效果越好,但有可能会过拟合。
decision_function_shape有两个取值,一个是ovr,即一个类别与其他类别进行划分;另一个是ovo,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
最后用测试集去查看分类准确度,此处可以直接调用score方法查看准确度,也可以调用sklearn中metrics的accuracy_scor方法查看。两者没有区别。

结果为0.7333333。结果不尽如人意但可以慢慢改参数改进。
最后绘制图片:

可以看到绿点几乎可以被很好的区分,但是蓝点和红点存在不易区分的地方。这时候调整核技巧或者将更多的特征属性加入学习可能会有更好的效果。
用Python实现支持向量机并处理Iris数据集的更多相关文章
- 机器学习笔记2 – sklearn之iris数据集
前言 本篇我会使用scikit-learn这个开源机器学习库来对iris数据集进行分类练习. 我将分别使用两种不同的scikit-learn内置算法--Decision Tree(决策树)和kNN(邻 ...
- Iris数据集实战
本次主要围绕Iris数据集进行一个简单的数据分析, 另外在数据的可视化部分进行了重点介绍. 环境 win8, python3.7, jupyter notebook 目录 1. 项目背景 2. 数据概 ...
- 从Iris数据集开始---机器学习入门
代码多来自<Introduction to Machine Learning with Python>. 该文集主要是自己的一个阅读笔记以及一些小思考,小总结. 前言 在开始进行模型训练之 ...
- 85、使用TFLearn实现iris数据集的分类
''' Created on 2017年5月21日 @author: weizhen ''' #Tensorflow的另外一个高层封装TFLearn(集成在tf.contrib.learn里)对训练T ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- Python实现bp神经网络识别MNIST数据集
title: "Python实现bp神经网络识别MNIST数据集" date: 2018-06-18T14:01:49+08:00 tags: [""] cat ...
- iris数据集(.csv .txt)免费下载
我看CSDN下载的iris数据集都需要币,我愿意免费共享,希望下载后的朋友们给我留个言 分享iris数据集(供学习使用): 链接: https://pan.baidu.com/s/1Knsp7zn-C ...
- R语言实现分层抽样(Stratified Sampling)以iris数据集为例
R语言实现分层抽样(Stratified Sampling)以iris数据集为例 1.观察数据集 head(iris) Sampling)以iris数据集为例"> 选取数据集中前6个 ...
随机推荐
- 递归函数 Vue ElementUI
对树形菜单的递归操作,首先应该对树形菜单数据进行整理,优化成自己需要的类型 比如Vue + ElementUI的动态侧边栏数据 export function routerRoleToPretty ( ...
- CentOS7 源码编译安装Tengine
简介 Tengine是由淘宝网发起的Web服务器项目.它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性.它的目的是打造一个高效.安全的Web平台. 发展 Tengine的性能和 ...
- 信步漫谈之JDK—源码编译
一.环境 Linux 系统:CentOS_6.5_x86_64 JDK 安装包:jdk-7u80-linux-x64.rpm OpenJDK 源码包:OpenJDK7 下载路径:http://down ...
- 使用docker试用各种软件及docker-ES设置
试用开源软件的优劣势 由于现在容器化的热度,大部分软件都有docker official镜像,那么使用docker就是试用软件很好的方法: 优势: 1.可以免去安装部署的过程. 2.不会对当前系统环境 ...
- decimal(19,6)什么意思
decimal(19,6)什么意思 数字长度19位,精确到小数点后6位例如0.123456 mysql中varchar(50)最多能存多少个汉字 首先要确定mysql版本4.0版本以下,varchar ...
- linux中的strings命令
strings - print the strings of printable characters in files. 意思是, 打印文件中可打印的字符. 我来补充一下吧 ...
- eq
<a class="s">1</a> <a class="s">2</a> <a class=" ...
- Sql语法注意事项
#分组 group by 作用:group by 子句可以将结果集按照指定的字段值一样的记录进行分组,配合聚合函数 可以进行组内统计的工作. 注意1:当在select中时,查询的内容中如果包含聚合函数 ...
- Nodejs“实现”Dubbo Provider
背景 目前nodejs应用越来越广泛,但和java的dubbo体系接入困难,所以我们需要实现node端的dubbo provider逻辑.java的dubbo provider是和consumer在一 ...
- Raphael.js--基础1
Raphael.js 特点: 1.兼容VML和SVG 2.扩展功能——动画 用法: //1.创建画布 let paper=Raphael(x,y,width,height); //2.创建形状 let ...