scrapy框架整理
0.安装scrapy框架
pip install scrapy
注:找不到的库,或者安装部分库报错,去python第三方库中找,很详细
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
1.创建一个scrapy框架
scrapy startproject 项目名

2.使用scrapy框架爬虫的三个步骤
a.配置items文件,确定需要爬取的字段
b.配置pipeline文件,确定文件的存储方式,并在setting文件中配置管道文件
注:如果存的是json数据,json.dumps(dict(item), ensure_ascii=False)
这里要记得将ensure_ascii置为False,原因是因为默认为ascii编码,但是中文用ascii编码会有问题
c.配置爬虫文件(分为两种,父类为Spider,CrawlSpider)
在终端中进入到项目目录下,执行:
scrapy genspider 爬虫名 限制的域名范围(创建Spider模板)
scrapy genspider -t crawl 爬虫名 限制的域名范围(创建CrawlSpider模板)
3.Spider类的使用
a.三个变量:name(爬虫名), allowed_domains(限定域), start_urls(最先请求的网站)
b.重写parse()方法,方法名必须是这个
c.在函数的最后yield item,会把item交给管道文件处理
d.如果需要再次发送请求的话需要 yield scrapy.Request(url,meta,callback)方法
url:为再次请求的地址
meta:请求携带的内容(字典格式),可以被response.meta取到,用于两个函数之间变量的传递
callback:请求的回调函数
4.CrawlSpider类的使用
a.三个变量(与Spider类一致)
b.rules规则的定义(用于匹配需要爬取的链接内容,且每次请求的页面也遵循这个规则)
优点:比Spider类更简洁,不需要写scrapy.Request()再次发送请求
注:rule规则可以写多条,如第一个规则用于翻页,第二个规则用于匹配当前页内中的链接
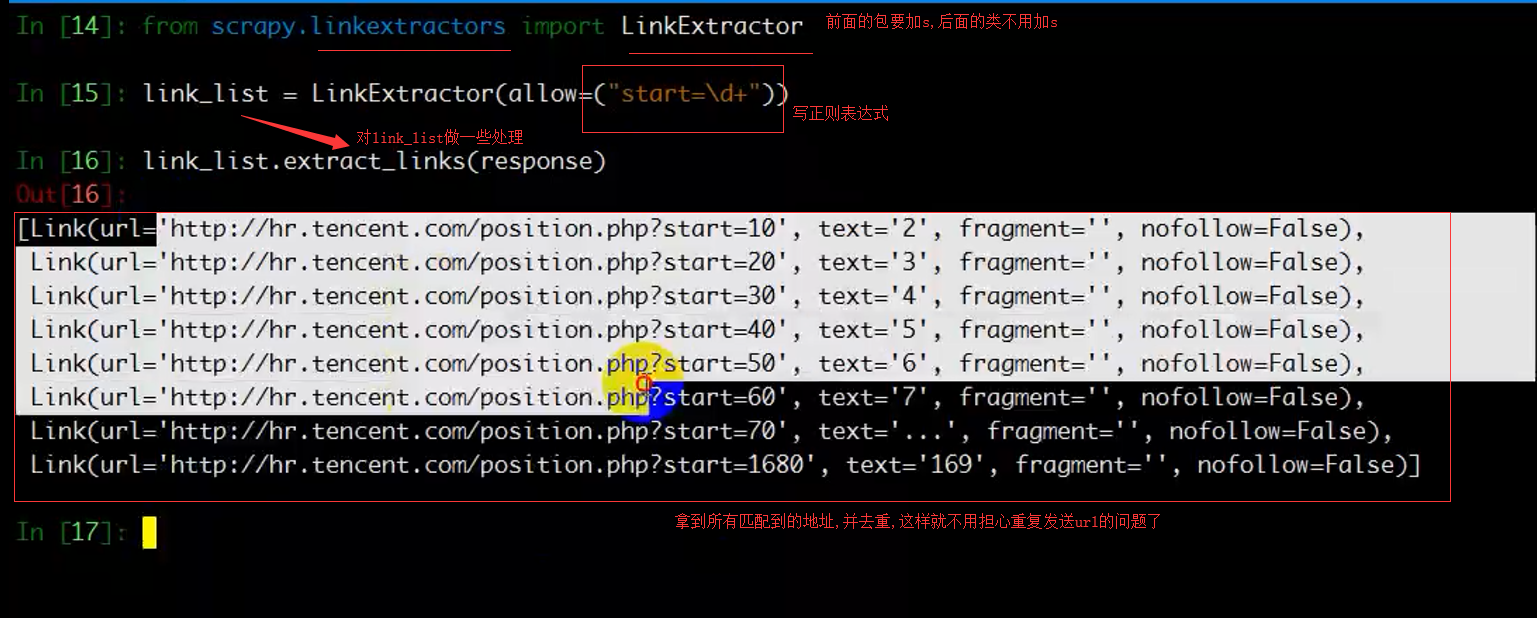
例:rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
allow:代表使用正则来匹配链接
restrict_xpaths:代表使用xpath来匹配链接
restrict_css:代表使用beautifulsoup4来匹配链接

callback:回调函数
follow:是否跟进(如果没有callback,follow默认为True),应用在匹配页码链接时,需要跟进
如果有callback,follow默认为False
注:在使用CrawlSpider时,callback不能再写parse,因为框架使用了parse实现其逻辑,我们在使用时,需要另起一个名字
5.中间件的设置
1.定义User-Agent列表,循环使用

2.如果需要使用代理服务器,需要设置代理,并附上对应的host和账号密码

scrapy框架整理的更多相关文章
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- Scrapy 框架流程详解
框架流程图 Scrapy 使用了 Twisted 异步非阻塞网络库来处理网络通讯,整体架构大致如下(绿线是数据流向): 简单叙述一下每层图的含义吧: Spiders(爬虫):它负责处理所有Respon ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- 12.scrapy框架
一.Scrapy 框架简介 1.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个 ...
- Scrapy 框架 安装
Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 ...
- Scrapy框架学习笔记
1.Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- scrapy框架系列 (1) 初识scrapy
Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页 ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
随机推荐
- Docker入门4------Dockerfile
转自:https://www.cnblogs.com/jsonhc/p/7766841.html https://www.cnblogs.com/jsonhc/p/7767669.html Docke ...
- python中的单例
使用__new__ 因为一个类每一次实例化的时候,都会走它的__new__方法.所以我们可以使用__new__来控制实例的创建过程,代码如下: class Single: instance = Non ...
- Hive为什么要启用Metastore?
转载来自: https://blog.csdn.net/qq_40990732/article/details/80914873 https://blog.csdn.net/tp15868352616 ...
- MATLAB变量
序言 在Matlab中,变量名由A~Z.a~z.数字和下划线组成,且变量的第一个字符必须是字母. 尽管变量名可以是任意长度, 但是Matlab只识别名称的前N=namelengthmax个字符, 这里 ...
- 10.4 再探迭代器-插入/IO/反向
10.4.1 插入迭代器 插入迭代器接受一个容器,生成一个迭代器,通过向该迭代器赋值可以实现向容器添加元素 (1)back_inserter: 接受一个参数, 示例: auto iter = back ...
- python进阶(三) 内建函数getattr工厂模式
getattr()这个方法最主要的作用是实现反射机制.也就是说可以通过字符串获取方法实例. 传入不同的字符串,调用的方法不一样. 原型:getattr(对象,方法名) 举个栗子: pyMethod类 ...
- How do you explain Machine Learning and Data Mining to non Computer Science people?
How do you explain Machine Learning and Data Mining to non Computer Science people? Pararth Shah, ...
- JS关键字和保留字汇总(小记)
ECMA-262 描述了一组具有特定用途的关键字.这些关键字可用于表示控制语句的开始或结束,或者用于执行特定操作等.按照规则,关键字也是语言保留的,不能用作标识符.以下就是ECMAScript的全部关 ...
- Unity中实现人物平滑转身
using UnityEngine; public class PlayerController : MonoBehaviour { ; ; ; void Update() { hor = Input ...
- Python记录10:模块
''' 1. 什么是模块 模块就一系列功能的集合体 模块有三种来源: 1. 内置的模块 2. 第三方的模块:pip install +模块名称 ...