Python爬虫教程-04-response简介
Spider-04-response简介
本小节介绍urlopen的返回对象,和简单调试方法
案例v3
- 研究request的返回值,输出返回值类型,打印内容
- geturl:返回请求对象的url
- info:请求返回对象的meta信息
- getcode:返回的http code
- py04v3.py文件:https://xpwi.github.io/py/py爬虫/py04v3.py
# py04v3.py
from urllib import request
if __name__ == '__main__':
url = 'https://jobs.zhaopin.com/CC375882789J00033399409.htm'
rsp = request.urlopen(url)
# 按住Ctrl键不送,同时点击urlopen,可以查看文档,有函数的具体参数和使用方法
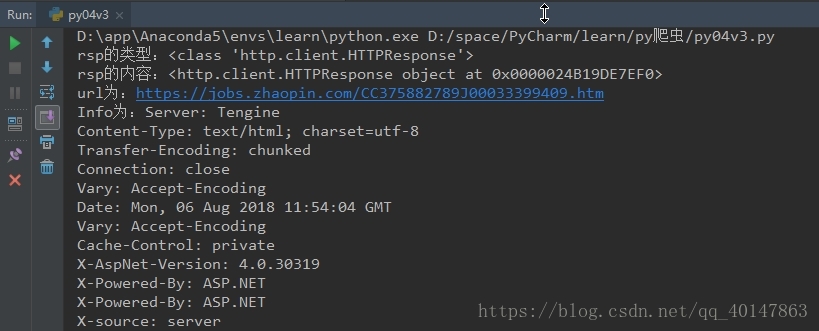
print("rsp的类型:{0}".format(type(rsp)))
print("rsp的内容:{0}".format(rsp))
print("url为:{0}".format(rsp.geturl()))
print("Info为:{0}".format(rsp.info()))
print("Code为:{0}".format(rsp.getcode()))
html = rsp.read()
右键运行,截图如下
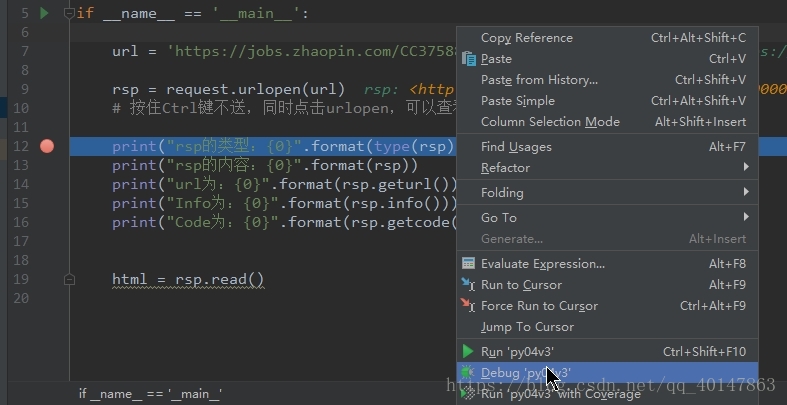
关于调试
- 在代码左侧【行号】上单击,出现红点,及断点
- 右键【Debug '项目名'】
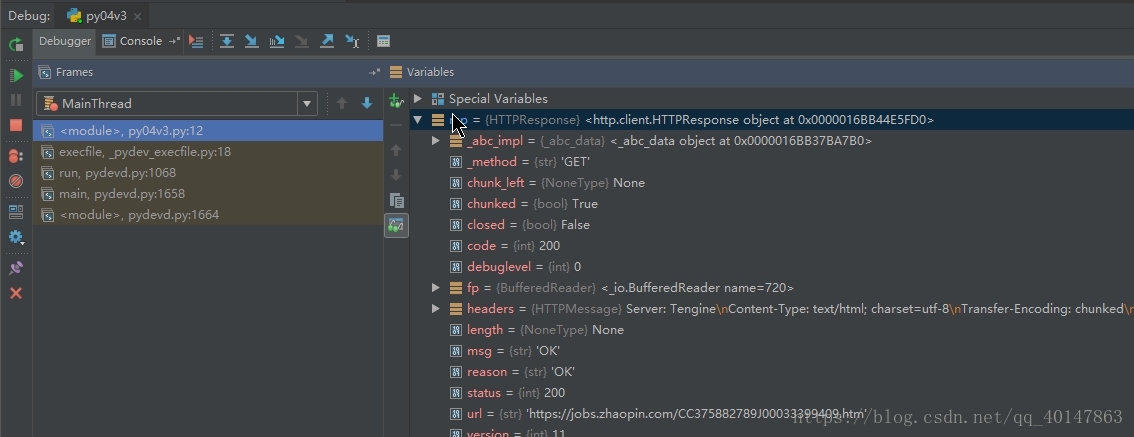
控制台截图如下
包括请求过程中的参数
urlopen的返回对象,和简单调试方法就介绍到这里了
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-04-response简介的更多相关文章
- Python爬虫教程-20-xml 简介
本篇简单介绍 xml 在python爬虫方面的使用,想要具体学习 xml 可以到 w3school 查看 xml 文档 xml 文档链接:http://www.w3school.com.cn/xmld ...
- Python爬虫教程-21-xpath 简介
本篇简单介绍 xpath 在python爬虫方面的使用,想要具体学习 xpath 可以到 w3school 查看 xpath 文档 xpath文档:http://www.w3school.com.cn ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
随机推荐
- .NET中的async和await关键字使用及Task异步调用实例
其实早在.NET 4.5的时候M$就在.NET中引入了async和await关键字(VB为Async和Await)来简化异步调用的编程模式.我也早就体验过了,现在写一篇日志来记录一下顺便凑日志数量(以 ...
- (转)C# 正则表达式
最近写爬虫时需要用到正则表达式,有段时间没有使用正则表达式现在渐渐感觉有些淡忘,现在使用还需要去查询一些资料.为了避免以后这样的情况,在此记录下正则表达式的一些基本使用方法附带小的实例.让以后在使用时 ...
- js中的正则表达式【常用】
正则表达式是一种用于处理字符串匹配的强大工具,正则的核心在于匹配语法. 以下是常用的匹配规则 . 除了换行符之外的任意一个字符 \ 转义符,取消后面一个字符的含义,使其成为一个普通字符 [] 括号里的 ...
- Linus' Law
Given enough eyeballs, all bugs are shallow. ------埃里克 ...
- python-树形结构和遍历
#!/usr/bin/python class TreeNode(object): def __init__(self,data = 0,left = None,right = None): self ...
- Maven项目中Spring整合Mybatis
Maven项目中Spring整合Mybatis 添加jar包依赖 spring需要的jar包依赖 <dependency> <groupId>org.springframewo ...
- c++ 同步阻塞队列
参考:<C++11深入应用> 用同步阻塞队列解决生产者消费者问题. 生产者消费者问题: 有一个生产者在生产产品,这些产品将提供给若干个消费者去消费,为了使生产者和消费者能并发执行,在两者之 ...
- IntelliJ IDEA 转移 C盘.IntelliJIdea 索引目录
IntelliJ IDEA 索引目录默认路径是 C:\Users\用户\.IntelliJIdea 转移步骤 1. 将 C:\Users\用户\.IntelliJIdea 索引目录剪切到要移动到的 ...
- 注解完成spring json返回数据格式配置
import com.fasterxml.jackson.databind.ObjectMapper;import com.fasterxml.jackson.databind.module.Simp ...
- MyEclipse部署web项目的关键
我自己的经验: 主要有3点: 自己的代码要正确 数据库服务确保已经启动 确保你的访问路径是正确的 1.自己的代码要正确 比如jdbc驱动,正确的写法:private static final Stri ...