Elastic学习之旅 (5) 倒排索引和Analyzer分词
大家好,我是Edison。
上一篇:ES文档的CRUD操作
重要概念1:倒排索引
在学习ES时,倒排索引是一个非常重要的概念。要了解倒排索引,就得先知道什么是正排索引。举个简单的例子,书籍的目录页(从章节名称快速知道页码)其实就是一个典型的正排索引。

而一般书籍的末尾部分的索引页,则是一个典型的倒排索引,是从关键词 到 章节名称 / 页码。

由上可知,对于图书来讲:目录页就是正排索引,索引页就是倒排索引。
而对于搜索引擎来讲:文档ID到文档内容和单词的关联是正排索引,而单词到文档ID的关系则是倒排索引。
我们可以从下面的两个表格来感受下正排索引和倒排索引的区别:

倒排索引的核心内容
倒排索引包含两个部分:
单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系。单词词典一般都很大,一般都通过B+树 或 哈希拉链法 实现,以满足高性能的插入和查询。
倒排列表(Posting List):记录了单词对应的文档结合,由倒排索引项组成。倒排索引项(Posting)包括 文档ID、词频(TF,该单词在文档中出现的次数,用于相关性评分)、位置(Postion,单词在文档中分词的位置,用于语句搜索) 以及 偏移(Offset,记录单词的开始结束为止,实现高亮显示)
下图展示了ES中的一个例子:
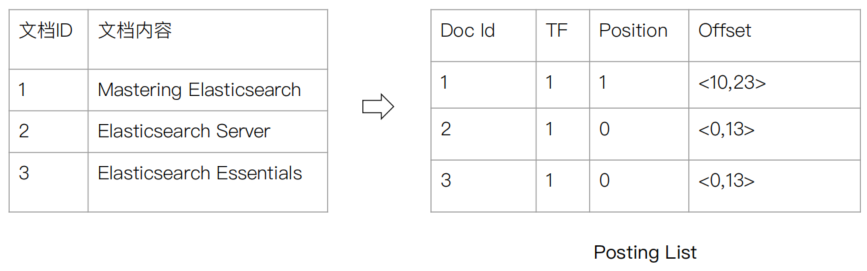
ES中的JSON文档中的每个字段,都有自己的倒排索引。当然,我们可以指定对某些字段不做索引,以节省存储空间,但是这些字段就无法被搜索。
重要概念2:Analyzer
在ES中文本分析是其最常见的功能之一,文本分析(Analysis)是把全文转换为一系列单词(term)的过程,也叫作分词。
文本分析是通过Analyzer来实现,我们可以使用ES内置的分析器,也可以按需定制分析器。
除了在数据写入时会进行全文转换词条,在匹配Query语句时也需要用相同的分析器对查询语句进行分析。
ES中的内置分词器
Standard Analyzer - 默认分词器,按词切分,小写处理
Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
Stop Analyzer - 小写处理,停用词过滤(the, a, is)
Whitespace Analyzer - 按照空格切分,不转小写
Keyword Analyzer - 不分词,直接将输入当做输出
Patter Analyzer - 正则表达式,默认 \W+(非字符分隔)
Language - 提供了30多种常见语言的分词器
Custom Analyzer - 自定义分词器
通过Analyzer进行分词
这里,我们来用_analyzer API做一些demo:
(1)Standard Analyzer
GET /_analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
分词结果:按词切分,默认小写(Quick被转成了quick)
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "<ALPHANUM>",
"position" : 9
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "<ALPHANUM>",
"position" : 10
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "<ALPHANUM>",
"position" : 11
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "<ALPHANUM>",
"position" : 12
}
]
}
(2)Simple Analyzer
GET /_analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
分词结果:非字母切分,忽略了数字2,小写处理
{
"tokens" : [
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
......
]
}
(3)Whitespace Analyzer
GET /_analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
分词结果:按照空格切分,不转小写。可以看到,brown-foxes被看成是一个整体,并未像其他分词一样分为brown 和 foxes。此外,也不会强制换位小写,比如Quick就保留了大写。
{
"tokens" : [
......
{
"token" : "Quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "brown-foxes",
"start_offset" : 16,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
......
]
}
(4)Stop Analyzer
GET /_analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
分词结果:小写处理,停用词过滤(the, a, is),这里原文中的in, over, the都被过滤掉了。
(5)Keyword Analyzer
GET /_analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
分词结果:不做任何分词处理,而是将输入整体作为一个term。通常用于不需要对输入做分词的场景。
{
"tokens" : [
{
"token" : "2 running Quick brown-foxes leap over lazy dogs in the summer evening.",
"start_offset" : 0,
"end_offset" : 70,
"type" : "word",
"position" : 0
}
]
}
(6)Pattern Analyzer
GET /_analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
正则表达式,默认 \W+(非字符分隔)
新增一个表达式analyzer:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_email_analyzer": {
"type": "pattern",
"pattern": "\\W|_",
"lowercase": true
}
}
}
}
} POST my_index/_analyze
{
"analyzer": "my_email_analyzer",
"text": "John_Smith@foo-bar.com"
}
(7)Lanuage Analyzer
ES提供了多种语言的分词器:阿拉伯语、亚美尼亚语、巴斯克语、孟加拉语、巴西语、保加利亚语、加泰罗尼亚语、捷克语、丹麦语、荷兰语、英语、芬兰语、法语、加利西亚语、德语、希腊语、印地语、匈牙利语、印度尼西亚语、爱尔兰语、意大利语、拉脱维亚语、立陶宛语、挪威语、波斯语、葡萄牙语、罗马尼亚语、俄语、索拉尼语、西班牙语、瑞典语、土耳其语、泰国语。
这里我们看看English:
GET /_analyze
{
"analyzer": "english",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
分词结果:将running替换为了run,将foxes替换为fox,dogs替换为dog,evening替换为了even,in被忽略。
可以看到,ES支持的语言分词器中,没有支持中文,这是因为:中文分词存在较大的难点,不像英语那么简单。
不过,我们可以安装一些中文分词器的插件(plugin),比如ICU Analyzer, 它提供了unicode的支持,更好地支持亚洲语言。
elasticsearch-plugin install analysis-icu
ICU Analyzer的示例:
POST /_analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理"
}
分词结果:
[他,说的,确实,在,理]
小结
本篇,我们了解了ElasticSearch的另一个重要概念:倒排索引 和 一个重要工具:Analyzer,还通过一些demo了解了Analyzer的具体使用案例,它们帮助ElasticSearch实现了强大的搜索功能。
参考资料
极客时间,阮一鸣,《ElasticSearch核心技术与实战》

Elastic学习之旅 (5) 倒排索引和Analyzer分词的更多相关文章
- WCF学习之旅—第三个示例之四(三十)
上接WCF学习之旅—第三个示例之一(二十七) WCF学习之旅—第三个示例之二(二十八) WCF学习之旅—第三个示例之三(二十九) ...
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- WCF学习之旅—第三个示例之二(二十八)
上接WCF学习之旅—第三个示例之一(二十七) 五.在项目BookMgr.Model创建实体类数据 第一步,安装Entity Framework 1) 使用NuGet下载最新版的Entity Fram ...
- WCF学习之旅—第三个示例之三(二十九)
上接WCF学习之旅—第三个示例之一(二十七) WCF学习之旅—第三个示例之二(二十八) 在上一篇文章中我们创建了实体对象与接口协定,在这一篇文章中我们来学习如何创建WCF的服务端代码.具体步骤见下面. ...
- WCF学习之旅—WCF服务部署到IIS7.5(九)
上接 WCF学习之旅—WCF寄宿前的准备(八) 四.WCF服务部署到IIS7.5 我们把WCF寄宿在IIS之上,在IIS中宿主一个服务的主要优点是在发生客户端请求时宿主进程会被自动启动,并且你可以 ...
- WCF学习之旅—WCF服务部署到应用程序(十)
上接 WCF学习之旅—WCF寄宿前的准备(八) WCF学习之旅—WCF服务部署到IIS7.5(九) 五.控制台应用程序宿主 (1) 在解决方案下新建控制台输出项目 ConsoleHosting.如下 ...
- WCF学习之旅—WCF服务的Windows 服务程序寄宿(十一)
上接 WCF学习之旅—WCF服务部署到IIS7.5(九) WCF学习之旅—WCF服务部署到应用程序(十) 七 WCF服务的Windows 服务程序寄宿 这种方式的服务寄宿,和IIS一样有一个一样 ...
- WCF学习之旅—WCF服务的WAS寄宿(十二)
上接 WCF学习之旅—WCF服务部署到IIS7.5(九) WCF学习之旅—WCF服务部署到应用程序(十) WCF学习之旅—WCF服务的Windows 服务程序寄宿(十一) 八.WAS宿主 IIS ...
- WCF学习之旅—WCF服务的批量寄宿(十三)
上接 WCF学习之旅—WCF服务部署到IIS7.5(九) WCF学习之旅—WCF服务部署到应用程序(十) WCF学习之旅—WCF服务的Windows 服务程序寄宿(十一) WCF学习之旅—WCF ...
- WCF学习之旅—第三个示例之五(三十一)
上接WCF学习之旅—第三个示例之一(二十七) WCF学习之旅—第三个示例之二(二十八) WCF学习之旅—第三个示例之三(二十九) WCF学习 ...
随机推荐
- 【SpringCloud】zuul路由网关
zuul路由网关 概述描述 路由基本配置 路由访问映射规则 查看路由信息 过滤器 太老旧了,就不做了解了
- dify升级,PostgreSQL数据库字段更新处理
一.概述 dify运行在容器中,PostgreSQL用的是阿里云,已经运行了很长一段时间.某些表的数据量很大,比如workflowruns表,就有100GB.这个主要是,详细记录了工作流的执行情况,包 ...
- DataPermissionInterceptor源码解读
本文首发在我的博客:https://blog.liuzijian.com/post/mybatis-plus-source-data-permission-interceptor.html 一.概述 ...
- sql数据库连接
前言 作为数据存储的数据库,近年来发展飞快,在早期的程序自我存储到后面的独立出中间件服务,再到集群,不可谓不快了.早期的sql数据库一枝独秀,到后面的Nosql,还有azure安全,五花八门,教人学不 ...
- Lock 同步锁
一. /* * 一.用于解决多线程安全问题的方式: * * synchronized:隐式锁 * 1. 同步代码块 * * 2. 同步方法 * * jdk 1.5 后: * 3. 同步锁 Lock * ...
- NetCAT:来自网络的实用缓存攻击
不断增加的外围设备正在增加现代处理器中内存管理子系统的压力,例如:DRAM的可用吞吐量已经不能满足现代网卡的传输速率.为了达到承诺的传输性能,Intel处理器使IO操作直接在末级缓存(LLC)上进行, ...
- 工具 | Hfish
0x00 简介 HFish是一款社区型免费蜜罐. 下载地址 HFish下载: HFish下载 0x01 功能说明 支持多种蜜罐服务 支持自定义Web蜜罐 支持流量牵引 支持端口扫描感知能力 支持多种告 ...
- 4G模块——大夏龙雀DX-CT511-A使用记录
4G模块--大夏龙雀DX-CT511-A使用记录 加回车换行 115200波特率 重启: AT+RESET 6.关闭HTTP服务: AT$HTTPCLOSE 关闭网路 AT+NETCLOSE 1.TC ...
- jdbcTemplate之“rowMapper内部类写法”
jdbcTemplate的rowMapper内部类写法 String sql ="select sku,feature from product"List<Product&g ...
- Vue之“表单修饰符”
1.lazy:失去焦点时处理 案例1 2.number:限制只能输入数字 案例1 3.trim:去掉前后空格 案例1