MySQL技巧(二)——无限级分类表设计
无限级分类表的设计(掌握'自身连接')
类似图书这种,会有很多种分类,而且在现实生活中这种分类会无限的往下分,所以不可能每有一个分类就创建一个分类表。应该使用下面这种语句
DROP TABLE IF EXISTS tdb_goods_types;
CREATE TABLE tdb_goods_types(
type_id SMALLINT PRIMARY KEY AUTO_INCREMENT COMMENT '分类ID',
type_name VARCHAR(50) COMMENT '分类名称',
parent_id SMALLINT NOT NULL DEFAULT 0 COMMENT '父类ID'
);
然后再模拟图书类的分类来个小demo
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('电子书',DEFAULT);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('文学',1);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('影视原著',2);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('中外名著',2);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('漫画杂志',2);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('文学',2);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('小说',2);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('传记',2);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('经管',1);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('金融投资',9);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('市场营销',9);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('管理学',9);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('职场进阶',9);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('科学新知',1);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('人工智能',14);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('电子商务',14);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('大数据',14);
INSERT INTO tdb_goods_types(type_name,parent_id) VALUES('科普',14);
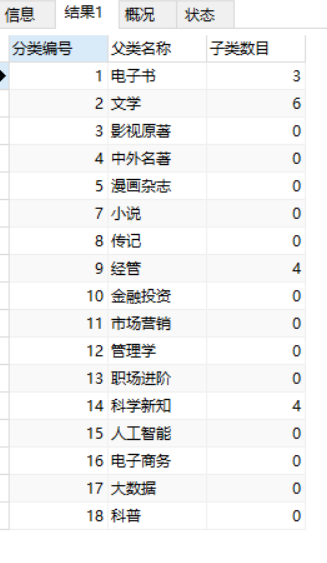
从下图中很容易可以看到,'电子书'为顶级分类,所以parent_id为0,以此类推....

这时候我们需要查询具体分类以及对应父类,我们就需要假想有两张相同的表,一张是父表(parent),一张是子表(son),自己连接自己查询,子表的parent_id = 父表的type_id,子表中的type_name就是子类分类,父表中的type_name就是父类分类名称
SELECT
s.type_id AS 分类编号,
s.type_name AS 分类名称,
p.type_name AS 父类名称
FROM
tdb_goods_types AS s
LEFT JOIN tdb_goods_types AS p ON s.parent_id = p.type_id;

也可以用另一种思路,查看父类,以及对应的子类
SELECT
p.type_id AS 分类编号,
p.type_name AS 父类名称,
s.type_name AS 子类名称
FROM
tdb_goods_types AS p
LEFT JOIN tdb_goods_types AS s ON s.parent_id = p.type_id;

改进:获取的是子类的数量
SELECT
p.type_id AS 分类编号,
p.type_name AS 父类名称,
COUNT(s.type_name) AS 子类数目
FROM
tdb_goods_types AS p
LEFT JOIN tdb_goods_types AS s ON s.parent_id = p.type_id
GROUP BY
p.type_name
ORDER BY
p.type_id ASC;
MySQL技巧(二)——无限级分类表设计的更多相关文章
- MySQL之无限级分类表设计
首先查找一下goods_cates表和table_goods_brands数据表 分别使用命令: root@localhost test>show columns from goods_cate ...
- FreeSql 使用 ToTreeList/AsTreeCte 查询无限级分类表
关于无限级分类 第一种方案: 使用递归算法,也是使用频率最多的,大部分开源程序也是这么处理,不过一般都只用到四级分类. 这种算法的数据库结构设计最为简单.category表中一个字段id,一个字段fi ...
- MySql(二)索引的设计与使用
MySql(二)索引的设计与使用 一.索引概述 二.设计索引的原则 三.BTREE索引与HASH索引 一.索引概述 所有Mysql列类型都可以被索引,对相关列使用索引时提高select操作性能的最佳途 ...
- MySQL分类表设计--根据ID删除全部子类
在做数据库分类表的时候,通常会有这样的设计:一个字段是ID,另一个字段PID,PID指向自己的上级分类: 这样的设计带来的问题是:我要删除一个类,我希望它的子类全部一起删除: 在不知道分类有多少层级的 ...
- Java电商支付系统手把手实现(二) - 数据库表设计的最佳实践
1 数据库设计 1.1 表关系梳理 仔细思考业务关系,得到如下表关系图 1.2 用户表结构 1.3 分类表结构 id=0为根节点,分类其实是树状结构 1.4 商品表结构 注意价格字段的类型为 deci ...
- Mysql配置优化,库表设计
Mysql 服务器参数类型: 基于参数的作用域: 全局参数:set global autocommit = ON/OFF; 会话参数(会话参数不单独设置则会采用全局参数):set session au ...
- MySQL树形结构的数据库表设计和查询
1.邻接表(Adjacency List) 实例:现在有一个要存储一下公司的人员结构,大致层次结构如下: 那么怎么存储这个结构?并且要获取以下信息: 1.查询小天的直接上司. 2.查询老宋管理下的直属 ...
- 在mysql数据库中,文章表设计有啥好的思路
Q: 用mysql设计一张文章表,不知道有啥好的思路! 我是这样的,应为考虑附件和图片,所以我的文章表除了有varchar(1000)的文章内容,还设置了个Bolb接收附件和图片. 我用的是mysql ...
- DF学Mysql(二)——数据表的基本操作
1.创建数据表 先使用“USE <数据库名>”指定在哪个数据库中操作 CREATE TABLE <表名> ( 字段1 数据类型 [列级别约束条件] [默认值], 字段2 数据类 ...
随机推荐
- delphi压缩与解压_不需要特别的控件
unit unzip; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...
- python 二分查找法
@source_data:数据集 @binary_num:要查找的数 @mid:中间数的键值 def binary_search(source_data,search_num): #传入数据集计算中间 ...
- 理解 Linux 的虚拟内存
前言 前不久组内又有一次我比较期待的分享:”Linux 的虚拟内存”.是某天晚上加班时,我们讨论虚拟内存的概念时,leader 发现几位同事对虚拟内存认识不清后,特意给这位同学挑选的主题(笑). 我之 ...
- JVM之垃圾收集器与内存分配回收策略(二)
上一篇JVM垃圾收集器与内存分配策略(一),下面是jdk1.7版本的垃圾收集器之间的关系,其中连线两端的两种垃圾收集器可以进行搭配使用,下面来总结一下这些收集器的一些特点以及关系. 一.Serial收 ...
- Python编程练习:使用 turtle 库完成玫瑰花的绘制
绘制效果: 源代码: import turtle # 设置初始位置 turtle.penup() turtle.left(90) turtle.fd(200) turtle.pendown() tur ...
- CTF中文件包含的一些技巧
i春秋作家:lem0n 原文来自:浅谈内存取证 0x00 前言 网络攻击内存化和网络犯罪隐遁化,使部分关键数字证据只存在于物理内存或暂存于页面交换文件中,这使得传统的基于文件系统的计算机取证不能有效应 ...
- 程序员跳槽有一份好的简历,offer让你拿到手软
作者:果汁简历 工欲善其事必先利其器,这是自古以来的道理,所以如果想找到一份好的工作,一定要先整理一份好的简历. 模板 写简历首先要有一个好的模板,我们做技术的不同于 UX,UED,我们不需要那么花哨 ...
- TextView的跑马灯效果实现
TextView的跑马灯效果实现 问题描述 当文字内容过长,但是只允许显示一行时,可以将文字显示为跑马灯效果,即文字滚动显示. 代码实现 第一种方法实现 先查询TextView控件的属性,得到以下信息 ...
- 使用HttpClient发送Get/Post请求 你get了吗?
HttpClient 是Apache Jakarta Common 下的子项目,可以用来提供高效的.最新的.功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议 ...
- GITHUB(github)初级使用
Github顾名思义是一个Git版本库的托管服务,是目前全球最大的软件仓库,拥有上百万的开发者用户,也是软件开发和寻找资源的最佳途径,Github不仅可以托管各种Git版本仓库,还拥有了更美观的Web ...