利用selenium爬取前程无忧招聘数据
1.背景介绍
selenium通过驱动浏览器,模拟浏览器的操作,进而爬取数据。此外,还需要安装浏览器驱动,相关步骤自行解决。
2.导入库
import csv
import random
import time
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.by import By
3.去除浏览器识别
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('detach', True)
去除浏览器上方的“Chrome正受到自动测试软件的控制”字眼。
4.实例化一个浏览器对象(传入浏览器的驱动程序)
driver = webdriver.Chrome(options=option)
5. 发起请求
driver.get("https://www.51job.com/")
time.sleep(2) #防止加载缓慢,休眠2秒
6.解决特征识别
script = 'Object.defineProperty(navigator, "webdriver", {get: () => false,});'
driver.execute_script(script)
没有出现验证框或验证滑块,说明已经成功屏蔽selenium识别。
7.定位输入框并查找相关职位
driver.find_element(By.XPATH, '//*[@id="kwdselectid"]').click()
driver.find_element(By.XPATH, '//*[@id="kwdselectid"]').clear()
driver.find_element(By.XPATH, '//*[@id="kwdselectid"]').send_keys('老师')
driver.find_element(By.XPATH, '/html/body/div[3]/div/div[1]/div/button').click()
# driver.implicitly_wait(10)
time.sleep(5)
print(driver.current_url)
输入关键词“老师”
8.利用xpath和css选择器提取数据
jobData = driver.find_elements(By.XPATH, '//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[2]/div[1]/div')
for job in jobData:
jobName = job.find_element(By.CLASS_NAME, 'jname.at').text
time.sleep(random.randint(5, 15) * 0.1)
jobSalary = job.find_element(By.CLASS_NAME, 'sal').text
time.sleep(random.randint(5, 15) * 0.1)
jobCompany = job.find_element(By.CLASS_NAME, 'cname.at').text
time.sleep(random.randint(5, 15) * 0.1)
company_type_size = job.find_element(By.CLASS_NAME, 'dc.at').text
time.sleep(random.randint(5, 15) * 0.1)
company_status = job.find_element(By.CLASS_NAME, 'int.at').text
time.sleep(random.randint(5, 15) * 0.1)
address_experience_education = job.find_element(By.CLASS_NAME, 'd.at').text
time.sleep(random.randint(5, 15) * 0.1) try:
job_welf = job.find_element(By.CLASS_NAME, 'tags').get_attribute('title')
except:
job_welf = '无数据'
time.sleep(random.randint(5, 15) * 0.1) update_date = job.find_element(By.CLASS_NAME, 'time').text
time.sleep(random.randint(5, 15) * 0.1) print(jobName, jobSalary, jobCompany, company_type_size, company_status, address_experience_education, job_welf,
update_date)
因为防止网站防爬,获取数据的同时,让程序休眠随机长度的时间。(根据自我需要设定合适的时间长度)
9.定位页面输入框并实现跳转
xpath定位页码输入框,输入页码,完成跳转
driver.find_element(By.XPATH, '//*[@id="jump_page"]').click()
time.sleep(random.randint(10, 30) * 0.1)
driver.find_element(By.XPATH, '//*[@id="jump_page"]').clear()
time.sleep(random.randint(10, 40) * 0.1)
driver.find_element(By.XPATH, '//*[@id="jump_page"]').send_keys(page)
time.sleep(random.randint(10, 30) * 0.1)
driver.find_element(By.XPATH,
'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[3]/div/div/span[3]').click()
10.数据存储
将提取的数据保存进csv中
with open('wuyou_teacher.csv', 'a', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(
[jobName, jobSalary, jobCompany, company_type_size, company_status, address_experience_education,
job_welf,
update_date])
csv结果如下图:
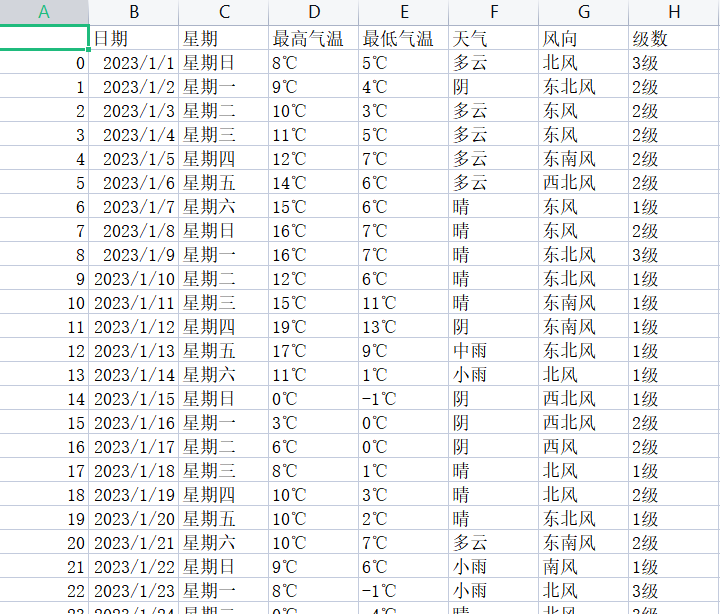
利用selenium爬取前程无忧招聘数据的更多相关文章
- 利用selenium 爬取豆瓣 武林外传数据并且完成 数据可视化 情绪分析
全文的步骤可以大概分为几步: 一:数据获取,利用selenium+多进程(linux上selenium 多进程可能会有问题)+kafka写数据(linux首选必选耦合)windows直接采用的是写my ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- 使用selenium爬取网站动态数据
处理页面动态加载的爬取 selenium selenium是python的一个第三方库,可以实现让浏览器完成自动化的操作,比如说点击按钮拖动滚轮等 环境搭建: 安装:pip install selen ...
- 利用Python爬取朋友圈数据,爬到你开始怀疑人生
人生最难的事是自我认知,用Python爬取朋友圈数据,让我们重新审视自己,审视我们周围的圈子. 文:朱元禄(@数据分析-jacky) 哲学的两大问题:1.我是谁?2.我们从哪里来? 本文 jacky试 ...
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- 爬虫(十七):Scrapy框架(四) 对接selenium爬取京东商品数据
1. Scrapy对接Selenium Scrapy抓取页面的方式和requests库类似,都是直接模拟HTTP请求,而Scrapy也不能抓取JavaScript动态谊染的页面.在前面的博客中抓取Ja ...
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- python selenium爬取自如租房数据保存到TXT文件
# -*- coding: utf-8 -*-"""Created on Fri Aug 31 2018 @author: chenlinlab"" ...
- 利用selenium爬取豆瓣电影Top250
这几天在学习selenium,顺便用selenium + python写了一个比较简陋的爬虫,现附上源码,有时间再补充补充: from selenium import webdriver from s ...
随机推荐
- 一种基于Modbus的工业通信网关设计
近年来,随着工业自动化领域的发展,工业现场对网络的可靠性及成本有极高的要求.传统基于串口的工业网关可以满足工业现场的应用,但却要付出高额成本.一种基于 ModBus 设计的工业通信网关就走进人们的眼中 ...
- 简介Hadoop
Hadoop 简介 Hadoop 是什么 Hadoop 是一个提供分布式存储和计算的开源软件框架,它具有无共享.高可用(HA).弹性可扩展的特点,非常适合处理海量数量. Hadoop 是一个开源软件框 ...
- 蓝桥2020 B组 第一场考试
2. 纪念日 问题描述: 请问从 1921 年 7 月 23 日中午 12 时到 2020 年 7 月 1 日中午 12 时一共包 含多少分钟? 答案提交: 这是一道结果填空题,你只需要算出结果后提交 ...
- openwrt扩容
方法二.三记得先使用Linux系统打开 GParted -- Download 方法三偏移地址获取: 1. 运行的openwrt安装losetup 2. 安装完毕后执行:losetup 获取偏移地址. ...
- PS将多个图片合并成长图
1.将所有图片拖到ps里面排好序.这里图层需要倒序,合成长图上面的图片要在图层的下面.图层倒序的方法:图层→排列→反向. 2.设置画布大小.假设18张图片,每个图片的高度是1448像素,则设置画布的高 ...
- hdu: 改革春风吹满地(叉乘求面积)
Problem Description" 改革春风吹满地,不会AC没关系;实在不行回老家,还有一亩三分地.谢谢!(乐队奏乐)" 话说部分学生心态极好,每天就知道游戏,这次考试如此简 ...
- 导出数据库表以及备注为excel
import com.alibaba.excel.annotation.ExcelProperty; import lombok.AllArgsConstructor; import lombok.D ...
- shortcuts
关闭选项卡 Ctrl+W 关闭当前窗口 alt + F4 alt + 空格 + c alt + 空格 + n 最小化窗口 alt + 空格 + x 最大化窗口 ALT+F4 关闭当前应用程序 ctrl ...
- 在为 DataGridView 添加数据列时,弹出 将要添加的列 CellType 属性为空 错误提示与说明
事务:为 DataGridView 添加数据列[也可以说是直接操作 DataGridView 数据列...]... 原由:在为 DataGridView 添加列的时候,[至少这是第三次遇到] 弹出 添 ...
- python读书笔记-网页制作
socket()函数 Python 中,我们用 socket()函数来创建套接字,语法格式如下: Socket 对象(内建)方法 Python Internet 模块: