Docker 部署 ELK 收集 Nginx 日志
一、简介
1、核心组成
ELK由Elasticsearch、Logstash和Kibana三部分组件组成;
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用
kibana 是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
2、四大组件
Logstash: logstash server端用来搜集日志;
Elasticsearch: 存储各类日志;
Kibana: web化接口用作查寻和可视化日志;
Logstash Forwarder: logstash client端用来通过lumberjack 网络协议发送日志到logstash server;
3、ELK工作流程
在需要收集日志的所有服务上部署logstash,作为logstash agent(logstash shipper)用于监控并过滤收集日志,将过滤后的内容发送到Redis,然后logstash indexer将日志收集在一起交给全文搜索服务ElasticSearch,可以用ElasticSearch进行自定义搜索通过Kibana 来结合自定义搜索进行页面展示。
第一步:上传docker安装包
第二步:解压安装包,进行安装
[root@nginx ~]# tar zxf docker.tar.gz
[root@nginx ~]# cd docker
[root@nginx docker]# ls
ca.crt docker-app.tar.gz docker.sh remove.sh
[root@nginx docker]# sh docker.sh
docker
docker-compose
docker-containerd
docker-containerd-ctr
docker-containerd-shim
dockerd
docker-init
docker-proxy
docker-runc
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /etc/systemd/system/docker.service.
第三步:查看是否安装成功
[root@nginx docker]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
第四步:vm.max_map_count至少需要262144,永久修改vm.max_map_count方法如下图:
直接执行如下命令:sysctl -w vm.max_map_count=
第五步:关闭防火墙
[root@docker ~]# systemctl stop firewalld
[root@docker ~]# setenforce 0
第六步:拉取ELK镜像
[root@nginx ~]# docker pull sebp/elk
第七步:下载镜像之后可以使用docker的命令来验证是否成功,参考命令如下:
[root@nginx ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
sebp/elk latest 0c1a88826f47 7 days ago 1.93GB
第八步:容器运行:运行此容器的时候,需要将宿主机的端口转发到该容器,其中ES端口为9200,kibana端口为5601,logbate端口为5044;建议将配置文件和数据存放在宿主机,便于后期维护,因此还需要将宿主机目录挂载到容器/data当中;最后构造的命令如下:
docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -v /Users/song/dockerFile:/data -it -d --name elk sebp/elk
第九步:检查端口是否开启
[root@nginx ~]# ss -tnl
第十步:数据导入与校验
容器运行之后,需要验证是否启动成功,通过浏览器访问kibana和ES的页面是否成功来判断。
http://localhost:5601/
当浏览器访问成功之后,参考如下图所示:
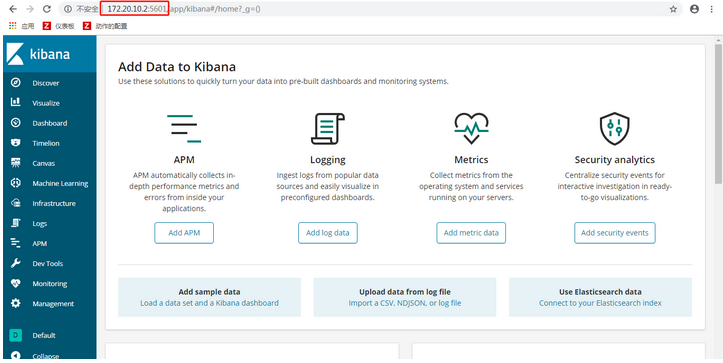
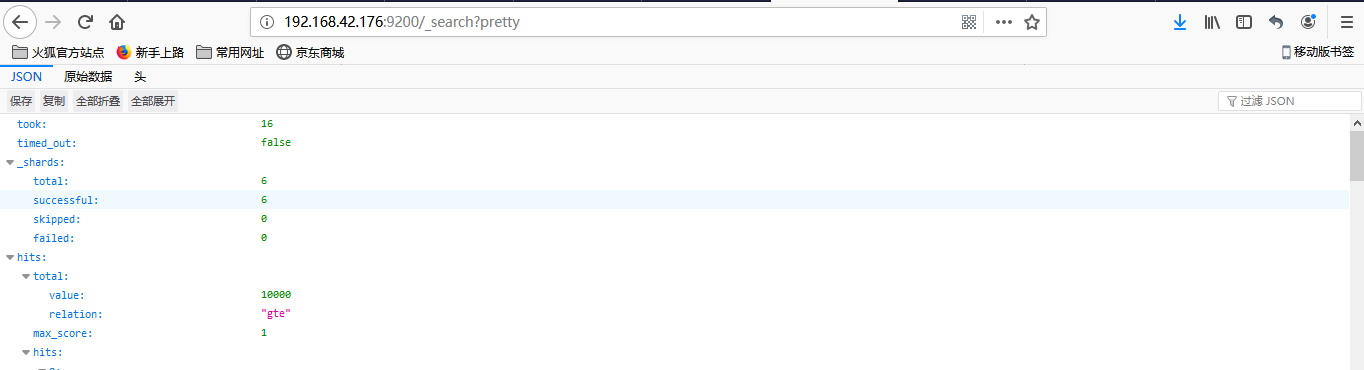
ES服务检查:验证kibana启动成功之后,接着继续验证ES服务是否启动成功,URL地址如下
http://localhost:9200/_search?pretty
访问之后,此时ES里面应该是没有数据的,出现的界面如下
第十一步:配置与验证
logstash配置:
logstash配置主要有三个地方要处理,首先是输入源在什么位置,然后是对数据进行过滤或者格式化,最后是需要将数据输出到什么地方;我在下方的配置只做了其中两项,因为在nginx日志当中已经将日志格式化了,编辑配置文件命令参考如下:
在/Users/song/dockerFile/目录下创建config目录,在config目录下创建logstash.yml文件
[root@nginx ~]# vim /Users/song/dockerFile/config/logstash.yml
input {
file {
path => "/data/logs/access.log"
codec => "json"
}
}
output {
elasticsearch { hosts => ["主机ip:9200"] }
stdout { codec => rubydebug }
}
在配置文件当中,可以看到日志文件存放的位置在 "/data/logs/access.log"当中,输出的地址是主机ip:9200,这是本机的ES服务
nginx日志格式
下载nginx
[root@nginx ~]# yum install nginx -y
更改nginx中的日志格式,将nginx的日志文件设置为json格式,在更改nginx配置文件之前,需要获取nginx配置文件路径,参考如下命令
[root@nginx ~]# sudo nginx -t
返回结果
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
在返回的结果当中已经可以看到配置文件所在的位置,使用vim编辑配置文件,参考命令
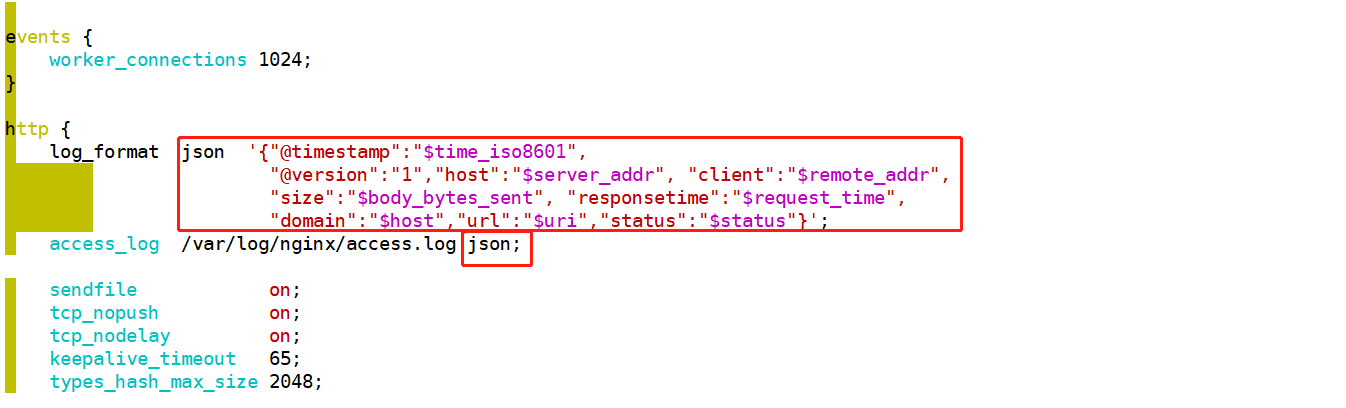
[root@nginx ~]# vim /etc/nginx/nginx.conf
http { log_format json '{"@timestamp":"$time_iso8601", "@version":"1","host":"$server_addr", "client":"$remote_addr", "size":"$body_bytes_sent", "responsetime":"$request_time", "domain":"$host","url":"$uri","status":"$status"}'; access_log /var/log/nginx/access.log json;
启动logstash
需要启动logstash开始收集日志,启动logstash之前需要先进入容器里面,进入容器参考命令如下:
[root@nginx ~]# docker exec -it elk bash
进入容器之后,需要启动logstash来收集数据,启动的时候需要带两个参数进去,第一个是logstash的数据暂存位置,第二个是使用的配置文件,因此构造的命令如下所示:
1、/opt/logstash/bin/logstash --path.data /tmp/logstash/data -f /data/config/logstash.yml
2、/opt/logstash/bin/logstash -e 'input { stdin { } } output { elasticsearch { hosts => ["localhost"] } }'
注意:如果看到报错信息:
Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the "path.data" setting. 请执行命令:service logstash stop 然后在执行就可以了。
当命令成功被执行后,看到:Successfully started Logstash API endpoint {:port=>9600} 信息后,输入:this is a dummy entry 然后回车,模拟一条日志进行测试。
第十一步:添加数据
只要nginx产生日志,logstash就会实时将日志发送到ES服务当中,在发送数据时,终端窗口也会发生变化,如下图所示

kibana索引配置:
通过浏览器访问kibana,URL地址如下
http://127.0.0.1:5601/app/kibana#/management/kibana/index?_g=()
点击左侧导航栏的Discover链接,便可进入创建索引模式界面,如下图所示

点击页面右下方的next按钮,会跳转到下一个页面,在此页面还需要选择一个时间维度,如下图所示

在此点击下一步,便创建kibana的索引完成,此时再次点击左侧导航栏的Discover链接,便可以看到刚才创建索引的一些视图,如下图所示

在图中有一个input输入框,笔者可以在里面填写筛选所需要的关键词;如果没有筛选出结果,也可检查左侧的时间筛选项是否设置正确,如笔者的时间筛选项设置的是Today,也就代表筛选当天的数据。
ELK的整体操作流程比较简单,首先是logstash收集各种日志并进行过滤,然后将过滤后的内容发送到ES服务中,最后用户通过Kibana的页面查看ES中的日志数据;
Docker 部署 ELK 收集 Nginx 日志的更多相关文章
- 使用Docker快速部署ELK分析Nginx日志实践
原文:使用Docker快速部署ELK分析Nginx日志实践 一.背景 笔者所在项目组的项目由多个子项目所组成,每一个子项目都存在一定的日志,有时候想排查一些问题,需要到各个地方去查看,极为不方便,此前 ...
- 使用Docker快速部署ELK分析Nginx日志实践(二)
Kibana汉化使用中文界面实践 一.背景 笔者在上一篇文章使用Docker快速部署ELK分析Nginx日志实践当中有提到如何快速搭建ELK分析Nginx日志,但是这只是第一步,后面还有很多仪表盘需要 ...
- Docker 部署ELK之Sentinl日志报警
前篇文章简单介绍了Docker 部署ELK,以及使用filebeat收集java日志.这篇我们介绍下日志报警配置,这里我们使用Sentinl插件. 1.修改kibana参数 进入elk容器,修改对应参 ...
- ELASTIC 5.2部署并收集nginx日志
elastic 5.2集群安装笔记 设计架构如下: nginx_json_log ->filebeat ->logstash ->elasticsearch ->kiban ...
- 搭建ELK收集Nginx日志
众所周知,ELK是日志收集套装,这里就不多做介绍了. 画了一个粗略的架构图,如下: 这里实际用了三个节点,系统版本为CentOS6.6,ES版本为2.3.5,logstash版本为2.4.0,kiba ...
- ELK日志系统之使用Rsyslog快速方便的收集Nginx日志
常规的日志收集方案中Client端都需要额外安装一个Agent来收集日志,例如logstash.filebeat等,额外的程序也就意味着环境的复杂,资源的占用,有没有一种方式是不需要额外安装程序就能实 ...
- 利用docker部署elk交换机日志分析
今天我们来聊一下利用docker部署elk日志分析系统,这里解析一下elk是啥东西.elk分别是Elasticsearch,Logstash和Kibana的首字母缩写. Elasticsearch是一 ...
- ELK收集Nginx|Tomcat日志
1.Nginx 日志收集,先安装Nginx cd /usr/local/logstash/config/etc/,创建如下配置文件,代码如下 Nginx.conf input { file { typ ...
- ELK Stack (2) —— ELK + Redis收集Nginx日志
ELK Stack (2) -- ELK + Redis收集Nginx日志 摘要 使用Elasticsearch.Logstash.Kibana与Redis(作为缓冲区)对Nginx日志进行收集 版本 ...
随机推荐
- m_atoi
自己实现atoi函数 函数定义:将字符串转换成整型数:atoi()会扫描参数nptr字符串,跳过前面的空格字符,直到遇上数字或正负号才开始做转换,而再遇到非数字或字符串时('\0')才结束转化,并将结 ...
- 云计算(8)--MapReduce如何处理fault
一些常见的故障 NM周期性的给RM发送heartbeats,如果RM发现server fails,则它会让所有与这个server有关的AM知道,让受影响的job的AM采取一些action,重新分配它的 ...
- 《SVN的操作流程及规范》
安装说明: 下载路径:https://tortoisesvn.net/downloads.html 选择对应版本: 安装中文语言包: 右键进入setting设置,选择中文简体. 使用说 ...
- python - pycharm 配置虚拟环境出现的中文命名问题
说一个困扰我很久的问题,当使用 pycharm 配置新的虚拟环境想要与之前的环境隔离的时候,正常的点击 New Project 创建项目时,不勾选 Inherit global site-packag ...
- Selenium3学习中遇到的问题
pytesseract识别验证码 TesseractNotFoundError: tesseract is not installed or it's not in your path brew in ...
- Linux命令的详解
cat /etc/passwd文件中的每个用户都有一个对应的记录行,记录着这个用户的一下基本属性.该文件对所有用户可读. /etc/shadow 文件正如他 ...
- struts--CRUD优化(图片上传)
1.上传方式 上传到指定文件目录,添加服务器与真实目录的映射关系,从而解耦上传文件与tomcat的关系 文件服务器 2.web代码优化 package com.yuan.crud.web; impo ...
- 遍历器Iterator--指针对象
一. 什么是遍历器 1. 遍历器对象(Iterator) 遍历器对象本质上是一个指针对象,该对象有一个next方法,调用next方法返回一个 含有value和done属性的对象{value: val/ ...
- JAVA的变量,数据类型与运算符
1. 变量 计算机处理数据,变量被用来存储处理的数据,之所以叫做变量因为你可以改变存储的值.更确切的说,一个变量指向着一块存储特定类型值的地址,换句话说,一个变量有名称.类型和值.一个变量有一个名称, ...
- HSSFWorkbook 模版使用
Java中导入.导出Excel 一.介绍当前B/S模式已成为应用开发的主流,而在企业办公系统中,常常有客户这样子要求:你要把我们的报表直接用Excel打开(电信系统.银行系统).或者是:我们已经习惯用 ...