Python3爬取王者官方网站英雄数据
爬取王者官方网站英雄数据
众所周知,王者荣耀已经成为众多人们喜爱的一款休闲娱乐手游,今天就利用python3 爬虫技术爬取官方网站上的几十个英雄的资料,包括官方给出的人物定位,英雄名称,技能名称,CD,英雄克制关系以及官方给出的出装Tips等数据。如下图:
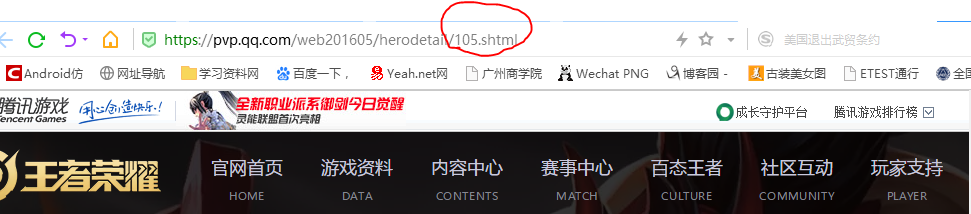
首先,对英雄列表页中的各个英雄子夜进行观察其URL的变动,发现每个英雄页面之后后面的页数会变动且呈递增规律。

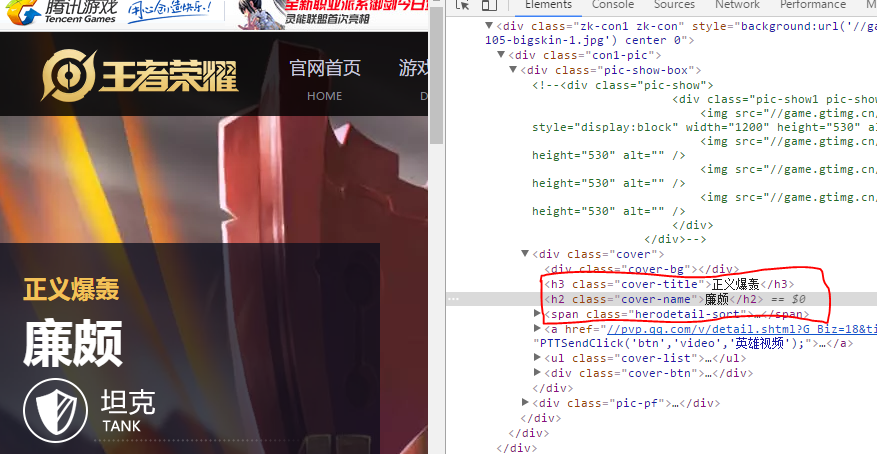
接下来审查要爬取对象的标签元素
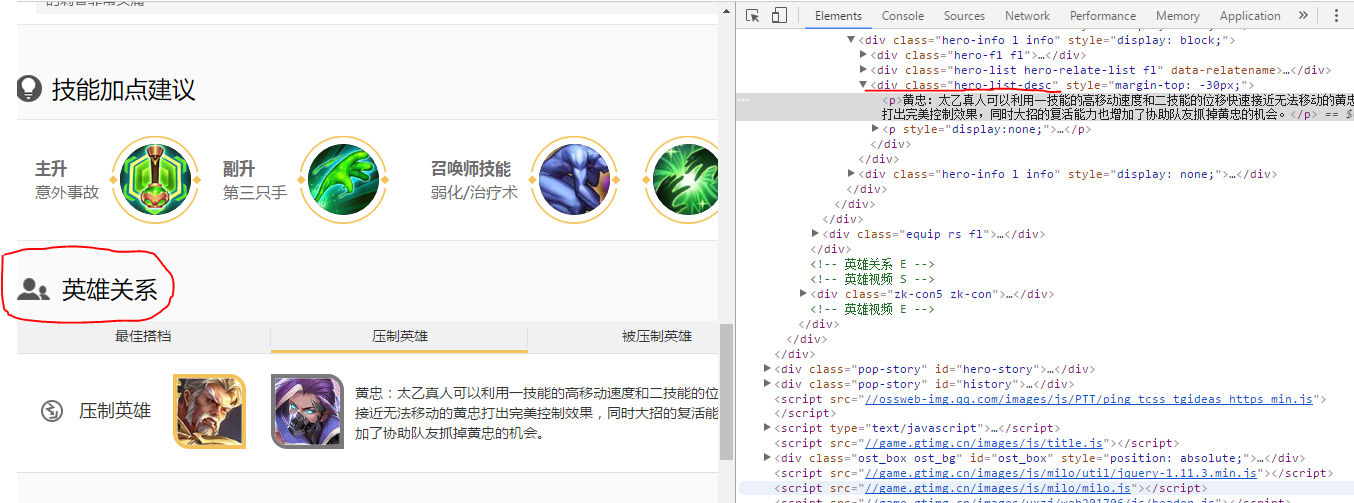
解析网站后,开始准备爬取数据
代码部分
准备要获取的所有英雄页面URL

根据页面上的标签获取数据并保存到字典

游戏部分英雄为虚构世界人物,这里还需要在jieba手动添加英雄名和部分装备名
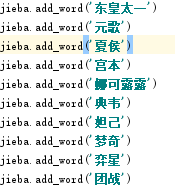

官方某些英雄由于没有在html上标明克制与压制关系的英雄名称,只上传了照片,如下图,并未找到“吕布”、“王昭君”等关键字,为了数据的完整性,部分数据需要手动在代码添加,大部分数据还是可以自动获取。


一切工作准备妥当之后,开始爬虫。
引入英雄名和停用词对其中部分数据进行清洗和分词

词频排序、保存为CSV文件

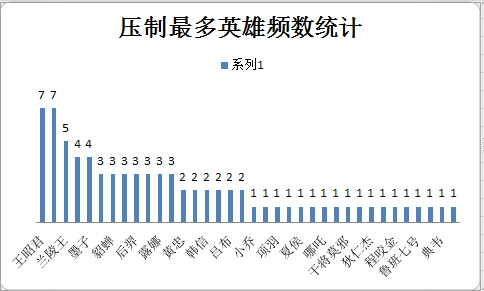
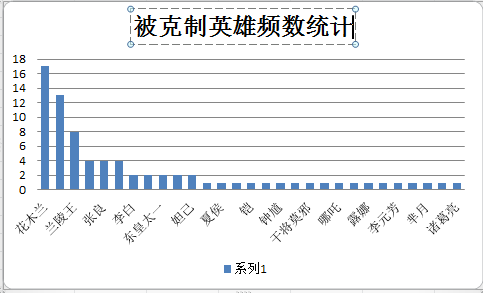
经过筛选,列出搭档出现频数最多,压制英雄数量最多的英雄频数,被克制最多的英雄频数三个数表如图
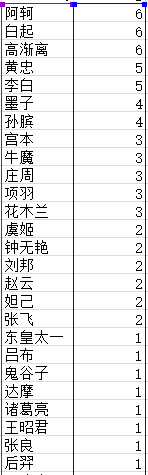
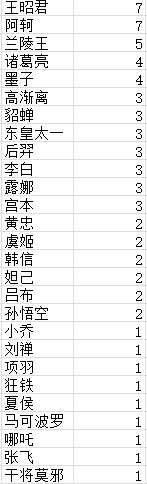
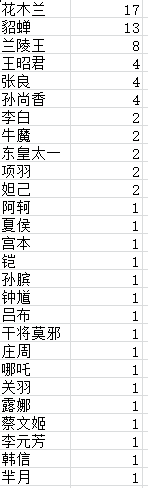
统计为树状图
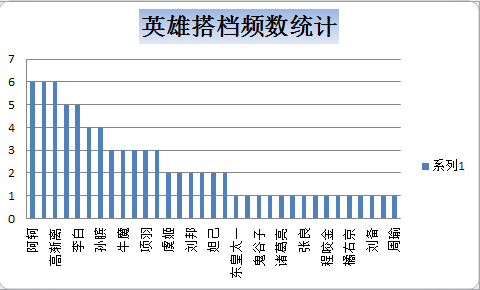
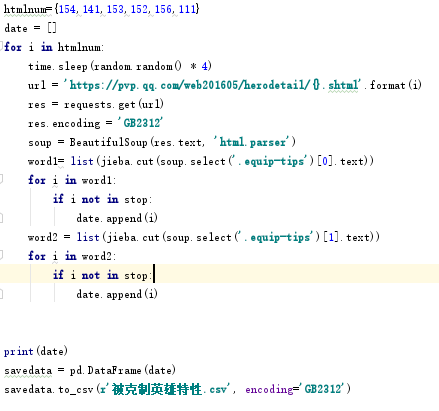
之后分析各类数据前几名英雄的官方tips词频,这里代码相同,爬取只只需改动htmlnum中的数据即可。最后输出csv文件。
在线生成词云如图



PS:以上仅为官网数据,不代表个人观点
Python3爬取王者官方网站英雄数据的更多相关文章
- 1、使用Python3爬取美女图片-网站中的每日更新一栏
此代码是根据网络上其他人的代码优化而成的, 环境准备: pip install lxml pip install bs4 pip install urllib #!/usr/bin/env pytho ...
- 2、使用Python3爬取美女图片-网站中的妹子自拍一栏
代码还有待优化,不过目的已经达到了 1.先执行如下代码: #!/usr/bin/env python #-*- coding: utf-8 -*- import urllib import reque ...
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- 用python的requests第三方模块抓取王者荣耀所有英雄的皮肤
本文使用python的第三方模块requests爬取王者荣耀所有英雄的图片,并将图片按每个英雄为一个目录存入文件夹中,方便用作桌面壁纸 下面时具体的代码,已通过python3.6测试,可以成功运行: ...
- 20行Python代码爬取王者荣耀全英雄皮肤
引言王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. 准备工作 ...
- python 爬取王者荣耀英雄皮肤代码
import os, time, requests, json, re, sys from retrying import retry from urllib import parse "& ...
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- Python开发爬虫之BeautifulSoup解析网页篇:爬取安居客网站上北京二手房数据
目标:爬取安居客网站上前10页北京二手房的数据,包括二手房源的名称.价格.几室几厅.大小.建造年份.联系人.地址.标签等. 网址为:https://beijing.anjuke.com/sale/ B ...
- Scrapy实战篇(七)之爬取爱基金网站基金业绩数据
本篇我们以scrapy+selelum的方式来爬取爱基金网站(http://fund.10jqka.com.cn/datacenter/jz/)的基金业绩数据. 思路:我们以http://fund.1 ...
随机推荐
- angular js根据json文件动态生成路由状态
项目上有一个新需求,就是需要根据json文件动态生成路由状态,查阅了一下资料,现在总结一下发出来: 首先项目用到的是angular的UI-路由,所以必须引入angular.js和angular-ui- ...
- JavaWeb 之 Filter 敏感词汇过滤案例
需求: 1. 对day17_case案例录入的数据进行敏感词汇过滤 2. 敏感词汇参考 src路径下的<敏感词汇.txt> 3. 如果是敏感词汇,替换为 *** 分析: 1. 对reque ...
- Requests库详细的用法
介绍 对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么简单介绍一下 requests 库的基本用法 安装 利用 pip 安装 ...
- kthread_run
头文件 include/linux/kthread.h 创建并启动 /** * kthread_run - create and wake a thread. * @threadfn: the fun ...
- 理解 Cookie,Session,Token 并结合 Redis 的使用
Http 协议是一个无状态协议, 客户端每次发出请求, 请求之间是没有任何关系的.但是当多个浏览器同时访问同一服务时,服务器怎么区分来访者哪个是哪个呢? cookie.session.token 就是 ...
- scrapy随机切换user-agent
使用github的 scrapy-fake-useragent 不用自己改源码继承自带的userAgent中间件 只需要安装后增加配置即可 https://github.com/alecxe/scr ...
- 大数据集群环境 zookeeper集群环境安装
大数据集群环境 zookeeper集群环境准备 zookeeper集群安装脚本,如果安装需要保持zookeeper保持相同目录,并且有可执行权限,需要准备如下 编写脚本: vi zkInstall.s ...
- mysql数据库查询缓存总结
概述 查询缓存(Query Cache,简称QC),存储SELECT语句及其产生的数据结果.闲来无事,做一下这块的总结,也做个备忘! 工作原理 查询缓存工作原理如下: 缓存SELECT操作的结果集和S ...
- Windows定时任务下载linux服务器批量文件到本地
编写批文件 1.1 编写main.bat文件 E: cd logs ftp -n -s:"E:\logs\mget.bat" 1.2 编写mget.bat文件 open ip地址 ...
- spring boot项目打包成jar后请求访问乱码解决
在启动jar的时候添加一个配置 -Dfile.encoding=utf-8 java -Dfile.encoding=utf-8 -jar xxxxtest-0.1.jar