Python新手爬虫三:爬取PPT模板
爬取网站:第一PPT(http://www.1ppt.com/) 此网站真的良心
老样子,先上最后成功的源码(在D盘创建一个"D:\PPT"文件夹,直接将代码执行就可获取到PPT):
import requests
import urllib
import os
from bs4 import BeautifulSoup
from fake_useragent import UserAgent def getPPT(url):
f = requests.get(url,headers=headers) #发送GET请求
f.encoding = f.apparent_encoding #设置编码方式
soup1 = BeautifulSoup(f.text,'lxml') #使用lxml解析器解析
classHtml = soup1.find('div',class_="col_nav i_nav clearfix").select('a') #在html中查找标签为div,class属性为 col_nav...的代码块并获取所有的 a 标签
for i in classHtml[:56]: #只要前56个类别
classUrl = i['href'].split('/')[2] #将ppt模板类别关键词存到classUrl,i['href']表示获取i中href属性的值,split('/')[2]表示以'/'为分隔符区第二个值
if not os.path.isdir(r'D:\PPT\\'+i['title']): #判断有无此目录,两个\\,第一个\转义了第二个\
os.mkdir(r'D:\PPT\\'+i['title']) #若无,创建此目录。
else:
continue #若有此目录,直接退出循环,就认为此类别已经下载完毕了
n = 0 #定义一个变量用来统计模板的个数
for y in range(1,15): #假设每个类别都有14页ppt(页数这一块找了很久,没找到全部获取的方法,只能采取此措施)
pagesUrl = url+i['href']+'/ppt_'+classUrl+'_'+str(y)+'.html' #获取每一页的URL
a = requests.get(pagesUrl,headers=headers)
if a.status_code != 404: #排除状态码为404的网页
soup2 = BeautifulSoup(a.text,'lxml')
for downppt in soup2.find('ul',class_='tplist').select('li > a'): #获取每一个模板下载界面的URL,find作用不再赘述,select('li > a')表示查看li标签下的a标签的内容
b = requests.get(url+downppt['href'],headers=headers) #获取最后的下载界面的html
b.encoding = b.apparent_encoding #设置编码类型
soup3 = BeautifulSoup(b.text,'lxml') #因为到了一个新的界面,要重新获取当前界面html
downList = soup3.find('ul',class_='downurllist').select('a') #获取下载PPT的URL
pptName = soup3.select('h1') #获取ppt模板名称
print('Downloading......')
try:
urllib.request.urlretrieve(downList[0]['href'],r'D:\PPT\\'+i['title']+'/'+pptName[0].get_text()+'.rar') #开始下载模板
print(i['title']+'type template download completed the '+str(n)+' few.'+pptName[0].get_text())
n += 1
except:
print(i['title']+'type download failed the '+str(n)+' few.')
n += 1 if __name__ == '__main__':
headers = {'user-agent':UserAgent().random} #定义请求头
getPPT('http://www.1ppt.com')
效果图:

逻辑其实挺简单的,代码也不算复杂。
代码基本都有注释,先一起捋一遍逻辑吧,逻辑搞清楚,代码不在话下。
1、首先网站首页:F12—>选择某个类别(比如科技模板)右击—>检查—>查看右侧的html代码

发现类别的URL保存在 <div class="col_nav" i_nav clearfix> 下的 <li> 标签里的 <a> 标签的 href 属性值中
于是想到用 BeautifulSoup 库的 find() 方法和 select() 方法
2、进入类别界面
同样:F12—>选择某个PPT(例如第一个)右击—>检查—>查看右侧html代码

照葫芦画瓢,继续获取进入下载界面的URL,方法同上
但在此页面需要注意的是,下边有选页标签:
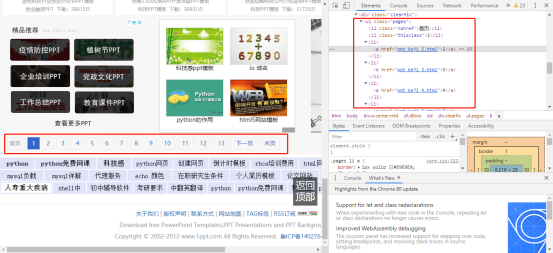
我暂时没有想到准确获取一共有多少页的方式,所以我在此代码中选择用range()函数来假设每个类别都有14页,然后再进行一步判断,看返回的http状态码是否为200。
3、进入具体PPT的下载界面
与上操作相同,获取最终PPT的下载URL
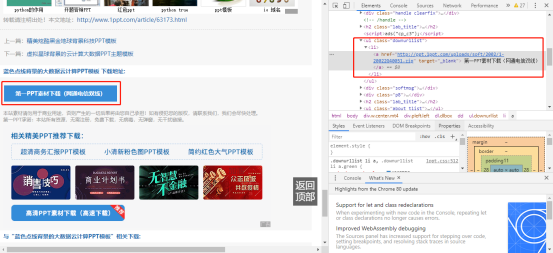
我在此代码中选择用 urllib 库来进行下载,最终将相对应类别的PPT放置同一文件夹中。
文件夹操作我是调用 os 库,具体代码还是往上翻一翻吧。
具体流程就这么几步了,剩下的就是循环 循环 再循环......
循环语句写好,就大功告成了!一起努力。
Python新手爬虫三:爬取PPT模板的更多相关文章
- 利用python的爬虫技术爬取百度贴吧的帖子
在爬取糗事百科的段子后,我又在知乎上找了一个爬取百度贴吧帖子的实例,为了巩固提升已掌握的爬虫知识,于是我打算自己也做一个. 实现目标:1,爬取楼主所发的帖子 2,显示所爬去的楼层以及帖子题目 3,将爬 ...
- python网络爬虫《爬取get请求的页面数据》
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在python3中的为urllib.request和urllib. ...
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- Python网络爬虫 | Scrapy爬取妹子图网站全站照片
根据现有的知识,写了一个下载妹子图(meizitu.com)Scrapy脚本,把全站两万多张照片下载到了本地. 网站的分析 网页的网址分析 打开网站,发现网页的网址都是以 http://www.mei ...
- python之爬虫(爬取.ts文件并将其合并为.MP4文件——以及一些异常的注意事项)
//20200115 最近在看“咱们裸熊——we bears”第一季和第三季都看完了,单单就第二季死活找不到,只有腾讯有资源,但是要vip……而且还是国语版……所以就瞄上了一个视频网站——可以在线观看 ...
- Python学习 —— 爬虫入门 - 爬取Pixiv每日排行中的图片
更新于 2019-01-30 16:30:55 我另外写了一个面向 pixiv 的库:pixiver 支持通过作品 ID 获取相关信息.下载等,支持通过日期浏览各种排行榜(包括R-18),支持通过 p ...
- 初识python 之 爬虫:爬取双色球中奖号码信息
人生还是要有梦想的,毕竟还有python.比如,通过python来搞一搞彩票(双色球).注:此文仅用于python学习,结果仅作参考.用到知识点:1.爬取网页基础数据2.将数据写入excel文件3.将 ...
- 初识python 之 爬虫:爬取中国天气网数据
用到模块: 获取网页并解析:import requests,html5lib from bs4 import BeautifulSoup 使用pyecharts的Bar可视化工具"绘制图表& ...
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
随机推荐
- yb课堂实战之订单和播放记录事务控制 《十六》
开启事务控制 启动类:@EnableTransactionManagement 业务类,或者业务方法@Transactional 默认事务的隔离级别和传播属性 启动类上加注解 Service层加注解
- PTA数据结构和答案解析
背景:期末数据结构复习题 绪论和线性表 判断题 The Fibonacci number sequence {F N } is defined as: F 0 =0, F 1 =1, F N =F N ...
- mysql Using join buffer (Block Nested Loop) join连接查询优化
最近在优化链表查询的时候发现就算链接的表里面不到1w的数据链接查询也需要10多秒,这个速度简直不能忍受 通过EXPLAIN发现,extra中有数据是Using join buffer (Block N ...
- oeasy教您玩转vim - 58 - # 块可视化
块可视化编辑 回忆上节课内容 上次我们了解到行可视模式 行可视模式 V 也可配合各种motion o切换首尾 选区的开头和结尾是mark标记 开头是 '< 结尾是 '> 可以在选区内进 ...
- salesforce零基础学习(一百四十)Record Type在实施过程中的考虑
本篇参考: salesforce 零基础学习(二十九)Record Types简单介绍 https://help.salesforce.com/s/articleView?id=sf.customiz ...
- npm私服 verdaccio 搭建
1.什么是npm 私服 我们前端(web,nodejs)平常使用的各种包,什么vue,react,react-router, zustand等,都会从 https://registry.npmjs.o ...
- LeetCode860. 柠檬水找零
题目链接:https://leetcode.cn/problems/lemonade-change/description/ 题目叙述: 在柠檬水摊上,每一杯柠檬水的售价为 5 美元.顾客排队购买你的 ...
- selenium获取验证码截图
获取验证码截图代码: 获取验证码代码: #!/user/bin/env python3 # -*- coding: utf-8 -*- import requests from selenium im ...
- git 提交备注规范
git 提交规范commit message = subject + :+ 空格 + message 主体 例如:feat:增加用户注册功能 常见的 subject 种类以及含义如下: feat: 新 ...
- java面试一日一题:java内存区域
问题:请讲下java内存区域? 分析:该问题比较容易和jvm内存模型相混淆,内存模型说的是java的内存规范,规定的是多线程下访问主内存的规则:而内存区域,说的是java运行时的内存划分,换句话说就是 ...