Pytorch数据加载与使用
前言
在训练的时候通常使用Dataset来处理数据集。
Dataset的作用
提供一个方式获取数据内容和标签(label)。
实战
from torch.utils.data import Dataset
from PIL import Image
import os
class get_data(Dataset):
def __init__(self,root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.img_dir = os.path.join(root_dir,label_dir)
self.img_list = os.listdir(self.img_dir)
def __getitem__(self, indx):
img_path = os.path.join(self.img_dir,self.img_list[indx])
img_label = self.label_dir
img_data = Image.open(img_path)
return img_data,img_label
def __len__(self):
return len(self.img_list)
root_dir = "C:\\Users\\Traveler\\Pictures"
label_dir = "Screenshots"
test = get_data(root_dir,label_dir)
img , label = test[1]
# img.show()
print(label)
print(len(test))
此代码定义了一个fet_data类,继承了Dataset,主要提供两个方法,获取数据(getitem)和获取大小(len)。
然而这两个方法使用的是内置的类,当达到一定条件时自动触发,比如__getitem__当需要获取数据时自动触发这个方法。
getitem
返回两个数据,一个是data,一个是label,实现原理就是主要看这两个函数,
os.listdir()是获取一个路径下的文件名(包含后缀)列表。类似于[‘1.txt’,'2.jpg']
Image.open()是打开图片文件的,打开一个图片后会赋值很多属性:如下图
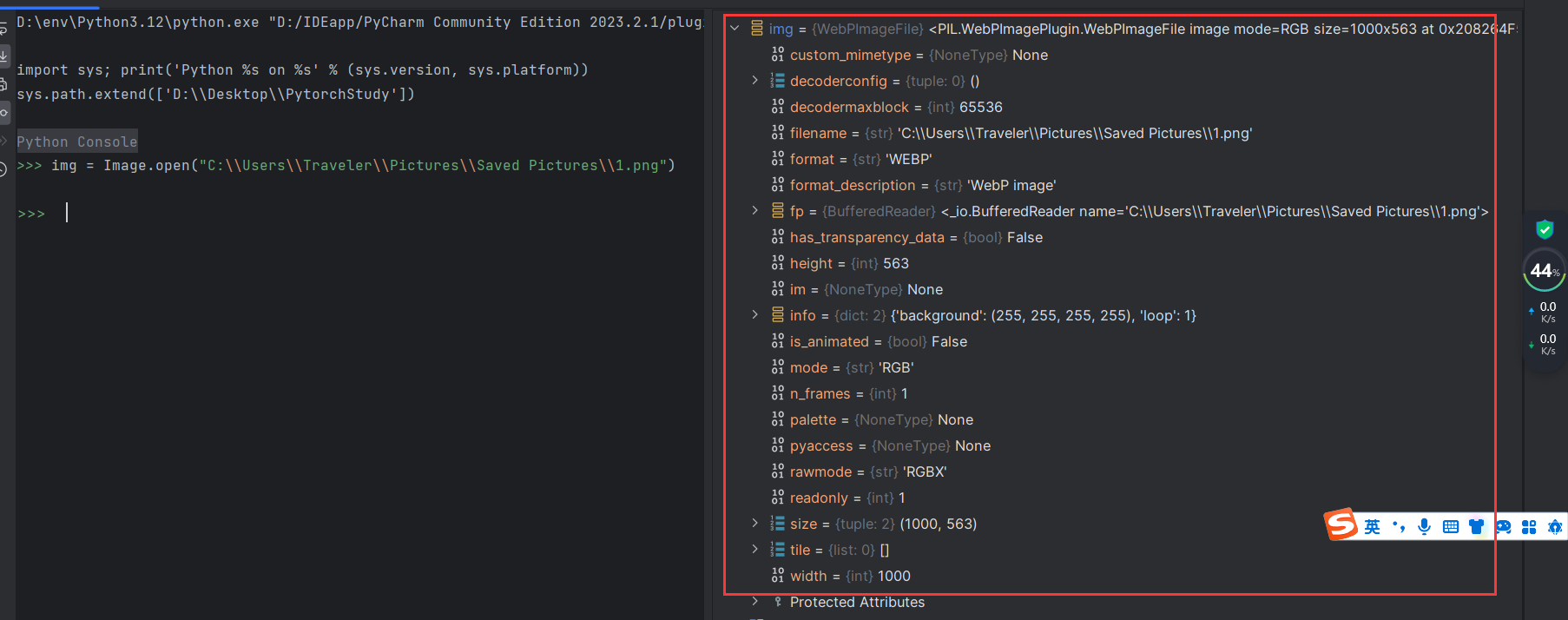
使用img.show()就可以打开,img.size()就可以获取大小。
另外os的其他函数也挺重要,比如os.path.join()就是拼接路径,这个的好处是防止Linux和Windows之间的路径不匹配问题。
Pytorch数据加载与使用的更多相关文章
- PyTorch数据加载处理
PyTorch数据加载处理 PyTorch提供了许多工具来简化和希望数据加载,使代码更具可读性. 1.下载安装包 scikit-image:用于图像的IO和变换 pandas:用于更容易地进行csv解 ...
- pytorch数据加载
一.方法一数据组织形式dataset_name----train----val from torchvision import datasets, models, transforms # Data ...
- pytorch数据加载器
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, ...
- PyTorch 数据集类 和 数据加载类 的一些尝试
最近在学习PyTorch, 但是对里面的数据类和数据加载类比较迷糊,可能是封装的太好大部分情况下是不需要有什么自己的操作的,不过偶然遇到一些自己导入的数据时就会遇到一些问题,因此自己对此做了一些小实 ...
- [源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampler
[源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampler 目录 [源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampl ...
- [源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader
[源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader 目录 [源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader 0x00 摘要 0x01 ...
- transformers 之Trainer对应的数据加载
基础信息说明 本文以Seq2SeqTrainer作为实例,来讨论其模型训练时的数据加载方式 预训练模型:opus-mt-en-zh 数据集:本地数据集 任务:en-zh 机器翻译 数据加载 Train ...
- ScrollView嵌套ListView,GridView数据加载不全问题的解决
我们大家都知道ListView,GridView加载数据项,如果数据项过多时,就会显示滚动条.ScrollView组件里面只能包含一个组件,当ScrollView里面嵌套listView,GridVi ...
- python多种格式数据加载、处理与存储
多种格式数据加载.处理与存储 实际的场景中,我们会在不同的地方遇到各种不同的数据格式(比如大家熟悉的csv与txt,比如网页HTML格式,比如XML格式),我们来一起看看python如何和这些格式的数 ...
- flask+sqlite3+echarts3+ajax 异步数据加载
结构: /www | |-- /static |....|-- jquery-3.1.1.js |....|-- echarts.js(echarts3是单文件!!) | |-- /templates ...
随机推荐
- 基于JQ使用原生js构造一个自动回复随机消息的机器人
某些业务会使用到页面里存在一个机器人,类似于假客服一样,可以回复游客的问题. 那么如何自己写一个自动回复消息的机器人呢? 源码献上 /** * 基于jq的自动对话机器人 * @param {Objec ...
- 第二部分:关键技术领域的开源实践【内网穿透FRP】
FRP简介 FRP(Fast Reverse Proxy)作为一种高性能的内网穿透工具,支持 TCP.UDP.HTTP.HTTPS 等多种协议.可以将内网服务以安全.便捷的方式通过具有公网IP节点(云 ...
- 玄机-第一章 应急响应- Linux入侵排查
目录 前言 简介 应急开始 准备工作 步骤 1 步骤 2 步骤 3 步骤 4 步骤5 总结 前言 作者这一次也是差一点一次过,因为没有经验的原因,或者说题目对问题描述不太对,如果说是求黑客反连的ip的 ...
- 写写Redis十大类型zset的常用命令
其实这些命令官方上都有,而且可读性很强,还有汉化组翻译的http://redis.cn/commands.html,不过光是练习还是容易忘,写一写博客记录一下 从zset类型开始写||zset类型适合 ...
- 云计算:基于Redis的文章投票系统(Python完整版)
| Redis的安装不懂的可前往 https://www.zeker.top/posts/9d3a5b2a/ 网上搜到的代码很多,但大多都有点小毛病(方法不可用,逻辑错误等) 自己基于网上找到的代码进 ...
- 【Java】部门集合树状顺序展示
一.需求效果: 表单的部门下拉选择时,可以展示部门的层级: 按照这个效果展示,但是不是树,还是原来的集合 二.实现方案: 用Java代码实现两个部分 1.展示Label效果处理 2.处理集合的树状排序 ...
- 【Uni-App】组件笔记
官网文档地址: https://uniapp.dcloud.io/component/README 组件是视图层的基本组成单元. 组件是一个单独且可复用的功能模块的封装. 每个组件,包括如下几个部分: ...
- 【Hibernate】03 配置文件 & API
映射器文件: - 字段的Column属性可以不写缺省,这将表示和实体类的属性标识一样 - type 属性用于声明表字段在Java中的类型,这个属性可不写缺省,自动匹配 Hibernate 4个核心AP ...
- 【Hibernate】Re04 JPA规范使用
都忘了前面一些小前提,就是数据库需要是存在的,不过写链接参数都会写上的 JPA实现就是和Hibernate类似,也需要对应的配置文件等等... 1.配置文件必须命名[persistence.xml]且 ...
- 【Spring源码分析】Spring Scope功能中的动态代理 - Scoped Proxy
本文基于Springboot 3.3.2及Springcloud 2023.0.1版本编写. Spring Scoped Proxy是什么 在使用Spring cloud配置中心动态配置更新功能时,笔 ...