爬取70城房价到oracle数据库并6合1
学习数据分析,然后没有合适的数据源,从国家统计局的网页上抓取一页数据来玩玩(没有发现robots协议,也仅仅发出一次连接请求,不对网站造成任何负荷)
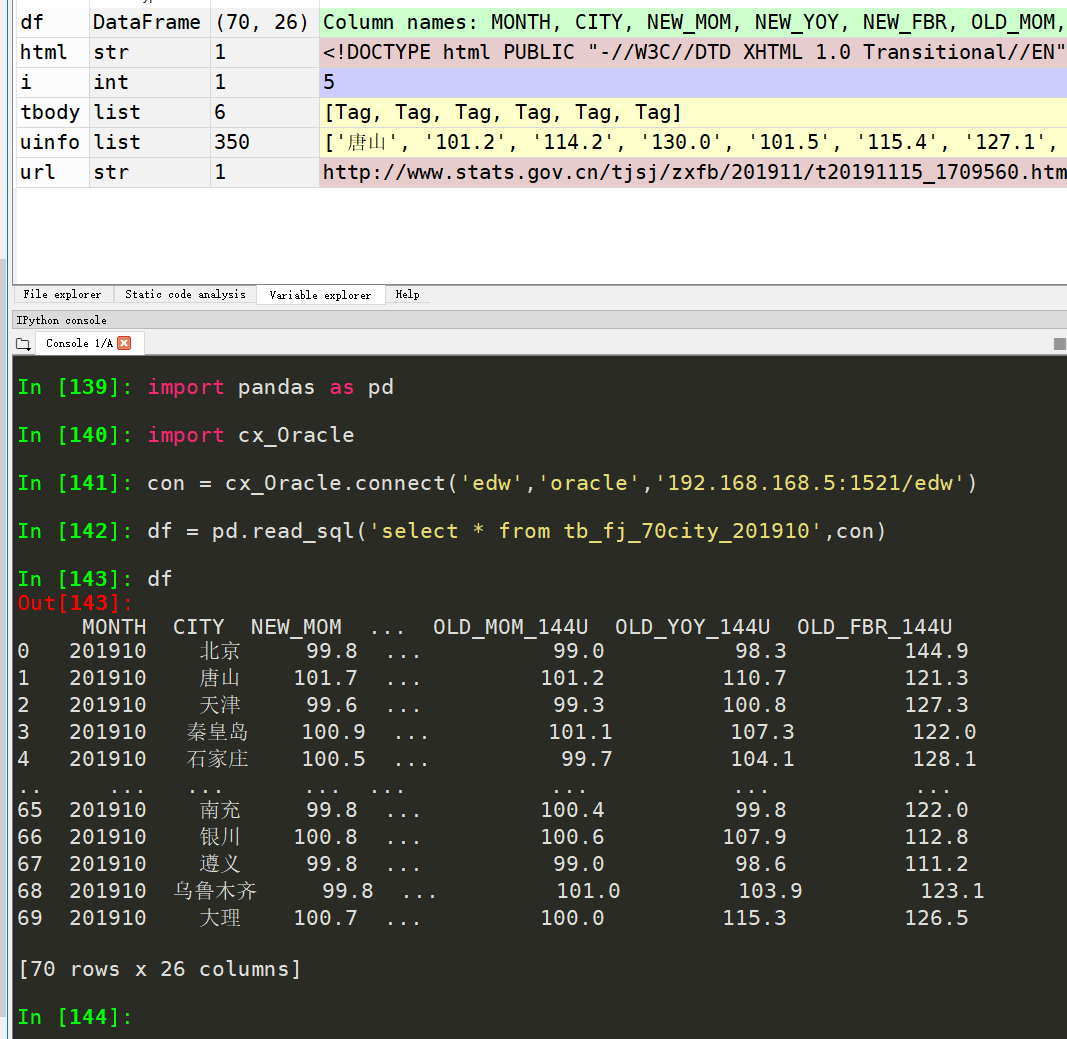
运行效果

源码
python代码
'''
本脚本旨在爬取70城房价进入oracle数据库以供学习
code by 九命猫幺 网页中有6个表格 最终爬取到数据库中形成6合1报表
'''
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
from sqlalchemy import create_engine #爬取网页
def getHTMLText(url):
try:
headers={'User-Agent':'Baiduspider'}
r = requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常' #解析出列表
def getTrText(tbody,tnum):
uinfo1 = []
uinfo2 = []
for i in tbody.strings:
if i != ' ':
uinfo1.append(str(i.string).replace('\u3000','').replace(' ',''))
for i in uinfo1:
if i not in ['皇','岛', '家','庄','丹','江','尔','滨','顶','山']:
uinfo2.append(i.replace('秦','秦皇岛').replace('石','石家庄').replace('牡','牡丹江').replace('哈','哈尔滨').replace('平','平顶山'))
uinfo2 = uinfo2[{1:-280,2:-280,3:-350,4:-350,5:-350,6:-350}[tnum]::]
return uinfo2 #将解析出的列表加工转换传入oracle库
def toSql(uinfo,tnum):
if tnum in [1,2]:
df = pd.DataFrame(np.array(uinfo).reshape(70,4),columns=['city','mom','yoy','fbr'])
else:
df = pd.DataFrame(np.array(uinfo).reshape(35,10),columns=['city','mom_90l','yoy_90l','fbr_90l','mom_90t144','yoy_90t144','fbr_90t144','mom_144u','yoy_144u','fbr_144u'])
con = create_engine('oracle+cx_oracle://edw:oracle@192.168.168.5:1521/?service_name=edw')
df.to_sql('tb_fj_70city_t'+str(tnum),con,if_exists='replace',index=False) if __name__ == "__main__":
uinfo = []
url = 'http://www.stats.gov.cn/tjsj/zxfb/201911/t20191115_1709560.html' #爬网页
html = getHTMLText(url)
soup = BeautifulSoup(html,'html.parser')
tbody = soup.select('table.MsoNormalTable tbody')
#解析存储
for i in range(6):
#解析表
uinfo = getTrText(tbody[i],i+1)
#存表入数据库
toSql(uinfo,i+1)
数据库代码
--70个大中城市商品住宅销售价格变动情况
CREATE TABLE tb_fj_70city_201910 AS
WITH tmp1 AS(
SELECT to_char(a.city) city,to_number(a.mom) new_mom,to_number(a.yoy) new_yoy,to_number(a.fbr) new_fbr
FROM tb_fj_70city_t1 a),
tmp2 AS(
SELECT to_char(a.city) city,to_number(a.mom) old_mom,to_number(a.yoy) old_yoy,to_number(a.fbr) old_fbr
FROM tb_fj_70city_t2 a),
tmp3 AS(
SELECT to_char(a.city) city,to_number(a.mom_90l) new_mom_90l,to_number(a.yoy_90l) new_yoy_90l,to_number(a.fbr_90l) new_fbr_90l,
to_number(a.mom_90t144) new_mom_90t144,to_number(a.yoy_90t144) new_yoy_90t144,to_number(a.fbr_90t144) new_fbr_90t144,
to_number(a.mom_144u) new_mom_144u,to_number(a.yoy_144u) new_yoy_144u,to_number(a.fbr_144u) new_fbr_144u
FROM tb_fj_70city_t3 a
UNION
SELECT to_char(a.city) city,to_number(a.mom_90l) new_mom_90l,to_number(a.yoy_90l) new_yoy_90l,to_number(a.fbr_90l) new_fbr_90l,
to_number(a.mom_90t144) new_mom_90t144,to_number(a.yoy_90t144) new_yoy_90t144,to_number(a.fbr_90t144) new_fbr_90t144,
to_number(a.mom_144u) new_mom_144u,to_number(a.yoy_144u) new_yoy_144u,to_number(a.fbr_144u) new_fbr_144u
FROM tb_fj_70city_t4 a),
tmp4 AS(
SELECT to_char(a.city) city,to_number(a.mom_90l) old_mom_90l,to_number(a.yoy_90l) old_yoy_90l,to_number(a.fbr_90l) old_fbr_90l,
to_number(a.mom_90t144) old_mom_90t144,to_number(a.yoy_90t144) old_yoy_90t144,to_number(a.fbr_90t144) old_fbr_90t144,
to_number(a.mom_144u) old_mom_144u,to_number(a.yoy_144u) old_yoy_144u,to_number(a.fbr_144u) old_fbr_144u
FROM tb_fj_70city_t5 a
UNION
SELECT to_char(a.city) city,to_number(a.mom_90l) old_mom_90l,to_number(a.yoy_90l) old_yoy_90l,to_number(a.fbr_90l) old_fbr_90l,
to_number(a.mom_90t144) old_mom_90t144,to_number(a.yoy_90t144) old_yoy_90t144,to_number(a.fbr_90t144) old_fbr_90t144,
to_number(a.mom_144u) old_mom_144u,to_number(a.yoy_144u) old_yoy_144u,to_number(a.fbr_144u) old_fbr_144u
FROM tb_fj_70city_t6 a)
SELECT 201910 month,aa.city,aa.new_mom,aa.new_yoy,aa.new_fbr,bb. old_mom,bb.old_yoy,bb.old_fbr,
cc.new_mom_90l,cc.new_yoy_90l,cc.new_fbr_90l,
cc.new_mom_90t144,cc.new_yoy_90t144,cc.new_fbr_90t144,
cc.new_mom_144u,cc.new_yoy_144u,cc.new_fbr_144u,
dd.old_mom_90l,dd.old_yoy_90l,dd.old_fbr_90l,
dd.old_mom_90t144,dd.old_yoy_90t144,dd.old_fbr_90t144,
dd.old_mom_144u,dd.old_yoy_144u,dd.old_fbr_144u
FROM tmp1 aa
JOIN tmp2 bb ON aa.city=bb.city
JOIN tmp3 cc ON aa.city=cc.city
JOIN tmp4 dd ON aa.city=dd.city; CALL p_drop_table_if_exist('tb_fj_70city_t1');
CALL p_drop_table_if_exist('tb_fj_70city_t2');
CALL p_drop_table_if_exist('tb_fj_70city_t3');
CALL p_drop_table_if_exist('tb_fj_70city_t4');
CALL p_drop_table_if_exist('tb_fj_70city_t5');
CALL p_drop_table_if_exist('tb_fj_70city_t6'); SELECT * FROM tb_fj_70city_201910;
就这样,表名中列名,取英文首字母:
mom:month on month ,环比
yoy:year on year,同比
fbr:fixed base ratio,定基比
90l:90 lower,90平米以下
144u:144 upper,144平米以上
90t144:90 to 144,90到144平米之间
优化后
上述脚本只能爬取一个月的,并且6表合1操作在数据库中执行,现在优化为批量爬取多个月份的数据
'''
本脚本旨在爬取70城房价进入oracle数据库以供学习
code by 九命猫幺 网页中有6个表格 最终爬取到数据库中形成6合1报表 网址:
'''
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
import cx_Oracle #爬取网页
def getHTMLText(url):
try:
headers={'User-Agent':'Baiduspider'}
r = requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常' #解析出列表
def getTrText(tbody,tnum):
uinfo1 = []
uinfo2 = []
for i in tbody.strings:
if i != ' ':
uinfo1.append(str(i.string).replace('\u3000','').replace(' ',''))
for i in uinfo1:
if i not in ['皇','岛', '家','庄','丹','江','尔','滨','顶','山']:
uinfo2.append(i.replace('秦','秦皇岛').replace('石','石家庄').replace('牡','牡丹江').replace('哈','哈尔滨').replace('平','平顶山'))
uinfo2 = uinfo2[{1:-280,2:-280,3:-350,4:-350,5:-350,6:-350}[tnum]::]
return uinfo2 #将解析出的列表加工转换传入oracle库
def toSql(uinfo,tnum):
if tnum in [1,2]:
df = pd.DataFrame(np.array(uinfo).reshape(70,4),columns=['city','mom','yoy','fbr'])
else:
df = pd.DataFrame(np.array(uinfo).reshape(35,10),columns=['city','mom_90l','yoy_90l','fbr_90l','mom_90t144','yoy_90t144','fbr_90t144','mom_144u','yoy_144u','fbr_144u'])
con = create_engine('oracle+cx_oracle://edw:oracle@192.168.168.5:1521/?service_name=edw')
df.to_sql('tb_fj_70city_t'+str(tnum),con,if_exists='replace',index=False) #6合1 并插入历史宽表
def intoWideTable(month):
con = cx_Oracle.connect('edw','oracle','192.168.168.5:1521/edw')
cur = con.cursor()
cur.execute("CALL p_drop_table_if_exist('tb_fj_70city_"+str(month)+"')")
cur.execute('''CREATE TABLE tb_fj_70city_'''+str(month)+''' AS
WITH tmp1 AS(
SELECT to_char(a.city) city,to_number(a.mom) new_mom,to_number(a.yoy) new_yoy,to_number(a.fbr) new_fbr
FROM tb_fj_70city_t1 a),
tmp2 AS(
SELECT to_char(a.city) city,to_number(a.mom) old_mom,to_number(a.yoy) old_yoy,to_number(a.fbr) old_fbr
FROM tb_fj_70city_t2 a),
tmp3 AS(
SELECT to_char(a.city) city,to_number(a.mom_90l) new_mom_90l,to_number(a.yoy_90l) new_yoy_90l,to_number(a.fbr_90l) new_fbr_90l,
to_number(a.mom_90t144) new_mom_90t144,to_number(a.yoy_90t144) new_yoy_90t144,to_number(a.fbr_90t144) new_fbr_90t144,
to_number(a.mom_144u) new_mom_144u,to_number(a.yoy_144u) new_yoy_144u,to_number(a.fbr_144u) new_fbr_144u
FROM tb_fj_70city_t3 a
UNION
SELECT to_char(a.city) city,to_number(a.mom_90l) new_mom_90l,to_number(a.yoy_90l) new_yoy_90l,to_number(a.fbr_90l) new_fbr_90l,
to_number(a.mom_90t144) new_mom_90t144,to_number(a.yoy_90t144) new_yoy_90t144,to_number(a.fbr_90t144) new_fbr_90t144,
to_number(a.mom_144u) new_mom_144u,to_number(a.yoy_144u) new_yoy_144u,to_number(a.fbr_144u) new_fbr_144u
FROM tb_fj_70city_t4 a),
tmp4 AS(
SELECT to_char(a.city) city,to_number(a.mom_90l) old_mom_90l,to_number(a.yoy_90l) old_yoy_90l,to_number(a.fbr_90l) old_fbr_90l,
to_number(a.mom_90t144) old_mom_90t144,to_number(a.yoy_90t144) old_yoy_90t144,to_number(a.fbr_90t144) old_fbr_90t144,
to_number(a.mom_144u) old_mom_144u,to_number(a.yoy_144u) old_yoy_144u,to_number(a.fbr_144u) old_fbr_144u
FROM tb_fj_70city_t5 a
UNION
SELECT to_char(a.city) city,to_number(a.mom_90l) old_mom_90l,to_number(a.yoy_90l) old_yoy_90l,to_number(a.fbr_90l) old_fbr_90l,
to_number(a.mom_90t144) old_mom_90t144,to_number(a.yoy_90t144) old_yoy_90t144,to_number(a.fbr_90t144) old_fbr_90t144,
to_number(a.mom_144u) old_mom_144u,to_number(a.yoy_144u) old_yoy_144u,to_number(a.fbr_144u) old_fbr_144u
FROM tb_fj_70city_t6 a)
SELECT '''+str(month)+''' month,aa.city,aa.new_mom,aa.new_yoy,aa.new_fbr,bb. old_mom,bb.old_yoy,bb.old_fbr,
cc.new_mom_90l,cc.new_yoy_90l,cc.new_fbr_90l,
cc.new_mom_90t144,cc.new_yoy_90t144,cc.new_fbr_90t144,
cc.new_mom_144u,cc.new_yoy_144u,cc.new_fbr_144u,
dd.old_mom_90l,dd.old_yoy_90l,dd.old_fbr_90l,
dd.old_mom_90t144,dd.old_yoy_90t144,dd.old_fbr_90t144,
dd.old_mom_144u,dd.old_yoy_144u,dd.old_fbr_144u
FROM tmp1 aa
JOIN tmp2 bb ON aa.city=bb.city
JOIN tmp3 cc ON aa.city=cc.city
JOIN tmp4 dd ON aa.city=dd.city''')
cur.close()
con.close() if __name__ == "__main__":
uinfo = []
urls = {201910:'http://www.stats.gov.cn/tjsj/zxfb/201911/t20191115_1709560.html',
201909:'http://www.stats.gov.cn/tjsj/zxfb/201910/t20191021_1704063.html',
201908:'http://www.stats.gov.cn/tjsj/zxfb/201909/t20190917_1697943.html',
201907:'http://www.stats.gov.cn/statsinfo/auto2074/201908/t20190815_1691536.html',
201906:'http://www.stats.gov.cn/tjsj/zxfb/201907/t20190715_1676000.html',
201905:'http://www.stats.gov.cn/tjsj/zxfb/201906/t20190618_1670960.html',
201904:'http://www.stats.gov.cn/tjsj/zxfb/201905/t20190516_1665286.html',
201903:'http://www.stats.gov.cn/tjsj/zxfb/201904/t20190416_1659682.html'
}
for key in urls:
#爬网页
html = getHTMLText(urls[key])
soup = BeautifulSoup(html,'html.parser')
tbody = soup.select('table.MsoNormalTable tbody')
#解析存储
for i in range(6):
#解析表
uinfo = getTrText(tbody[i],i+1)
#存表入数据库
toSql(uinfo,i+1)
#存入宽表
intoWideTable(key)
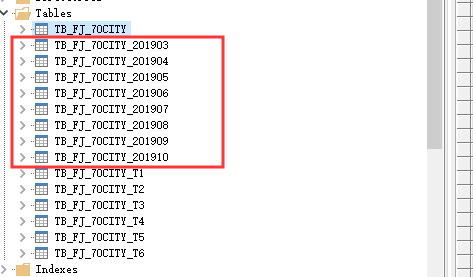 数据库中同时得到了多个月份的
数据库中同时得到了多个月份的
再优化单一月份爬取的代码
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
import cx_Oracle#爬取网页
def getHTMLText(url):
try:
headers={'User-Agent':'Baiduspider'}
r = requests.get(url,headers=headers,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常'#解析出列表
def getTrText(tbody,tnum):
uinfo1 = []
uinfo2 = ['...']
for i in tbody.strings:
if i not in [' ',' ']:
uinfo1.append(str(i.string).replace(' ',''))
for i in uinfo1:
if '\u4e00'
ok了
爬取70城房价到oracle数据库并6合1的更多相关文章
- 【nodejs 爬虫】使用 puppeteer 爬取链家房价信息
使用 puppeteer 爬取链家房价信息 目录 使用 puppeteer 爬取链家房价信息 页面结构 爬虫库 pupeteer 库 实现 打开待爬页面 遍历区级页面 方法一 方法二 遍历街道页面 遍 ...
- pymysql 使用twisted异步插入数据库:基于crawlspider爬取内容保存到本地mysql数据库
本文的前提是实现了整站内容的抓取,然后把抓取的内容保存到数据库. 可以参考另一篇已经实现整站抓取的文章:Scrapy 使用CrawlSpider整站抓取文章内容实现 本文也是基于这篇文章代码基础上实现 ...
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- python之scrapy爬取jingdong招聘信息到mysql数据库
1.创建工程 scrapy startproject jd 2.创建项目 scrapy genspider jingdong 3.安装pymysql pip install pymysql 4.set ...
- Python爬取全球是最大的电影数据库网站IMDb数据
在使用 Python 开发爬虫的过程中,requests 和 BeautifulSoup4(别名bs4) 应用的比较广泛,requests主要用于模拟浏览器的客户端请求,以获取服务器端响应,接收到的响 ...
- python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图: 我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库. 因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis ...
- 将爬取的网页数据保存到数据库时报错不能提交JPA,Caused by: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\xB6 \xE2...' for column 'content' at row 1
错误原因:我们可以看到错误提示中的字符0xF0 0x9F 0x98 0x84 ,这对应UTF-8编码格式中的4字节编码(UTF-8编码规范).正常的汉字一般不会超过3个字节,为什么为出现4个字节呢?实 ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- (3)分布式下的爬虫Scrapy应该如何做-递归爬取方式,数据输出方式以及数据库链接
放假这段时间好好的思考了一下关于Scrapy的一些常用操作,主要解决了三个问题: 1.如何连续爬取 2.数据输出方式 3.数据库链接 一,如何连续爬取: 思考:要达到连续爬取,逻辑上无非从以下的方向着 ...
随机推荐
- vs code切换中英文界面
1. 在vs code的应用扩展中搜索这个插件: Chinese (Simplified) Language Pack for Visual Studio Code 这个插件,安装完毕重新加载即可生效 ...
- redis删除策略
redis 设置过期时间 Redis 中有个设置时间过期的功能,即对存储在 redis 数据库中的值可以设置一个过期时间.作为一个缓存数据库,这是非常实用的.如我们一般项目中的 token 或者一些登 ...
- putty 配色方案
putty 配色方案 修改地点: Default Foreground: 255/255/255 Default Background: 51/51/51 ANSI Black: 77/77/77 A ...
- easyui入门
什么是easyui! easyui=jquery+html4(用来做后台的管理界面) 1.通过layout布局 我们先把该导的包导下 然后就是JSP页面布局 2.通过tree加载菜单 先来一个实体类 ...
- url中的20%、22%、26%、28%、29%怎么解析还原成真实的字符
- Luogu P5363 [SDOI2019]移动金币
话说这题放在智推里好久了的说,再不写掉对不起自己233 首先你要知道一个叫做阶梯Nim的东西,具体的可以看这篇博客 那么我们发现这和这道题的关系就很明显了,我们把两个金币之间的距离看作阶梯Nim的每一 ...
- [日常] SNOI2019场外VP记
SNOI2019场外VP记 教练突然说要考一场别省省选来测试水平...正好还没看题那就当VP咯w... Day 1 八点开题打 .vimrc. 先看了看题目名...一股莫名鬼畜感袭来... 怎么T1就 ...
- Paper | FFDNet: Toward a Fast and Flexible Solution for CNN based Image Denoising
目录 故事背景 核心思想 FFDNet 网络设置 噪声水平图 对子图像的去噪 保证噪声水平图的有效性 如何盲处理 为啥不用短连接 裁剪像素范围 实验 关于噪声水平图的敏感性 盲处理 发表在2018 T ...
- vue+elementui+netcore混合开发
1.VueController.cs using Bogus; using System; using System.Collections.Generic; using System.Linq; u ...
- win7 下docker 镜像加速
打开 Kitematic 运行 docker cli 注册镜像 https://www.daocloud.io/mirror#accelerator-doc 上有镜像地址 sudo sed -i &q ...