AB实验的高端玩法系列2 - 更敏感的AB实验, CUPED!
背景
AB实验可谓是互联网公司进行产品迭代增加用户粘性的大杀器。但人们对AB实验的应用往往只停留在开实验算P值,然后let it go。。。let it go 。。。
让我们把AB实验的结果简单的拆解成两个方面:
\[P(实验结果显著) = P(统计检验显著|实验有效)× P(实验有效)\]
如果你的产品改进方案本来就没啥效果当然怎么开实验都没用,但如果方案有效,请不要让 statictical Hack 浪费一个优秀的idea
如果预期实验效果比较小,有哪些基础操作来增加实验显著性呢?
通常情况下为了增加一个AB实验的显著性,有两种常见做法:增加流量或者增长实验时间。但对一些可能对用户体验产生负面影响或者成本较高的实验来说,上述两种方法都略显粗糙。
对于成熟的产品来说大多数的改动带来的提升可能都是微小的!
在数据为王的今天,我们难道不应该采用更精细化的方法来解决问题么?无论是延长实验时间还是增加流量一方面都是为了增加样本量,因为样本越多,方差越小,p值越显著,越容易检测出一些微小的改进。
因此如果能合理的通过统计方法降低方差,就可能更快,更小成本的检测到微小的效果提升
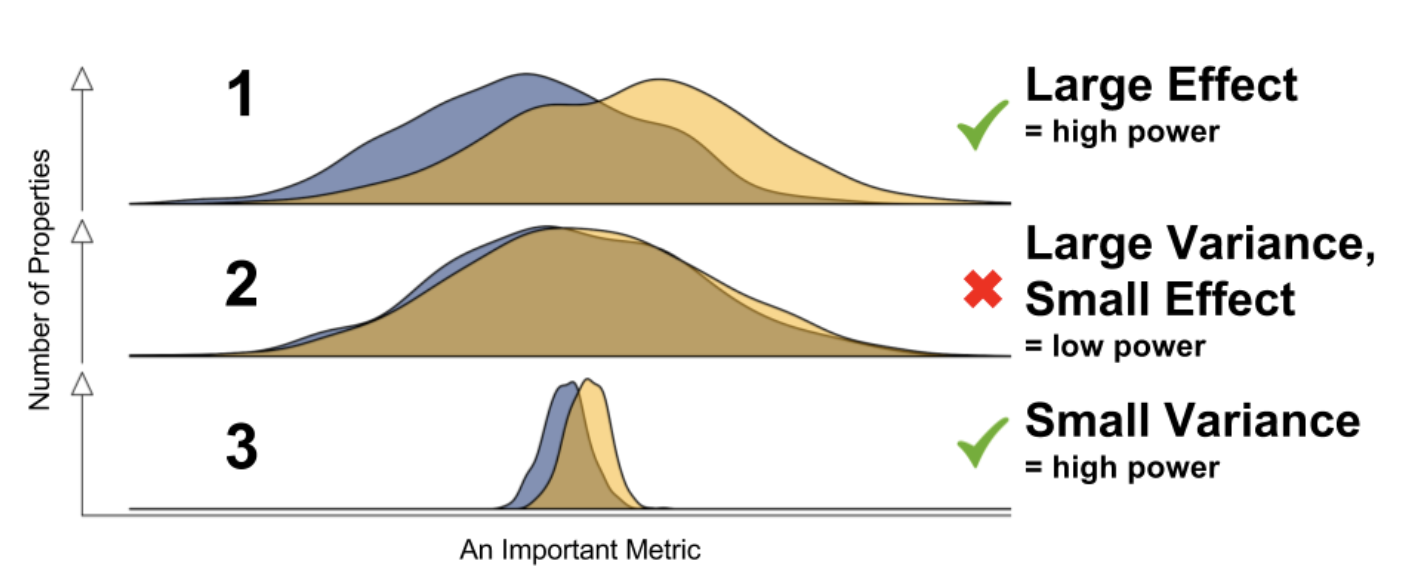
CUPED(Controlled-experiment Using Pre-Experiment Data)应运而生。 下面我会简单总结一下论文的核心方法,还有几个Bing, Netflix 以及Booking的应用案例。
论文
Deng A, Xu Y, Kohavi R, Walker T. Improving the Sensitivity of Online Controlled Experiments by Utilizing Pre-experiment Data. Proceedings of the Sixth ACM International Conference on Web Search and Data Mining. New York, NY, USA: ACM; 2013. pp. 123–132. Paper链接
核心方法总结
论文的核心在于通过实验前数据对实验核心指标进行修正,在保证无偏的情况下,得到方差更低, 更敏感的新指标,再对新指标进行统计检验(p值)。
这种方法的合理性在于,实验前核心指标的方差是已知的,且和实验本身无关的,因此合理的移除指标本身的方差不会影响估计效果。
作者给出了stratification和Covariate两种方式来修正指标,同时给出了在实际应用中可能碰到的一些问题以及解决方法.
stratifiaction
这种方式针对离散变量,一句话概括就是分组算指标。如果已知实验核心指标的方差很大,那么可以把样本分成K组,然后分组估计指标。这样分组估计的指标只保留了组内方差,从而剔除了组间方差。
\[
\begin{align}
k &= {1,2,...,K} \\
\hat{Y}_{strat} &= \sum_{k=1}^{K} w_k * (\frac{1}{n_k}*\sum_{x_i \in k} Y_i )\\
Var(\hat{Y}) &= Var_{\text{within_strat}} + Var_{\text{between_strat}}\\
&=\sum_{k=1}^K\frac{w_k}{n} \sigma_k^2 + \sum_{k=1}^K\frac{w_k}{n} (\mu_k - \mu)^2\\
&>=\sum_{k=1}^K\frac{w_k}{n} \sigma_k^2 = Var(\hat{Y}_{strat})
\end{align}
\]
Covariate
Covariate适用于连续变量。需要寻找和实验核心指标(Y)存在高相关性的另一连续特征(X),然后用该特征调整实验后的核心指标。X和Y相关性越高方差下降幅度越大。因此往往可以直接选择实验前的核心指标作为特征。只要保证特征未受到实验影响,在随机AB分组的条件下用该指标调整后的核心指标依旧是无偏的。
\[
\begin{align}
Y_i^{cov} &= Y_i - \theta(X_i - E(x))\\
\hat{Y}_{cov} &= \hat{Y} - \theta(\bar{x} - E(x))\\
\theta &= cov(X,Y)/cov(X)\\
Var(\hat{Y}_{cov}) & = Var(\hat{Y}) * (1-\theta^2)
\end{align}
\]
stratification和Covariate其实是相同的原理,从两个角度来看:
- 从回归预测的角度,实验核心指标是Y,降低Y的方差就是寻找和Y相关的自变量X来解释Y中信息的过程(提升\(R^2\)),X可以是连续也可以是离散的
- 从投资组合的角度,Y是组合中的一项资产,想要降低交易Y的风险(方差),就要做空和Y相关的X资产来对冲风险,相关性越高对冲效果越好
下图摘自Booking的案例,他们的核心指标是每周的房间预定量,Covariate是实验前的每周房间预定量,博客链接在案例分享里。
实战攻略
covariate的选择
这里的选择包括两个方面,特征的选择和计算特征的pre-experiment时间长度的选择。
核心指标在per-experiment的估计通常是很好的covariate的选择,且估计covariate选择的时间段相对越长效果越好。时间越长covariate的覆盖量越大,且受到短期波动的影响越小估计更稳定。
没有pre-experiment数据怎么办
这个现象在互联网中很常见,新用户或者很久不活跃的用户都会面临没有近期行为特征的问题。作者认为可以结合stratification方法对有/无covariate的用户进一步打上标签。或者其实不仅局限于pre-experiment特征,只要保证特征不受到实验影响post-experiment特征也是可以的。
而在Booking的案例中,作者选择对这部分样本不作处理,因为通常缺失值是用样本均值来填充,在上述式子中就等于是不做处理。
Attention
Covariate选择的核心是\(E(X^{treatment}) = E(X^{control})\),这一点不论你选择什么特征, 是pre-experiment还是post-experiment都要保证。
当然也有用CUPED来矫正实验组对照组差异的,但这个内容不在这里讨论。
应用案例
Bing 加载时间对用户点击率的影响
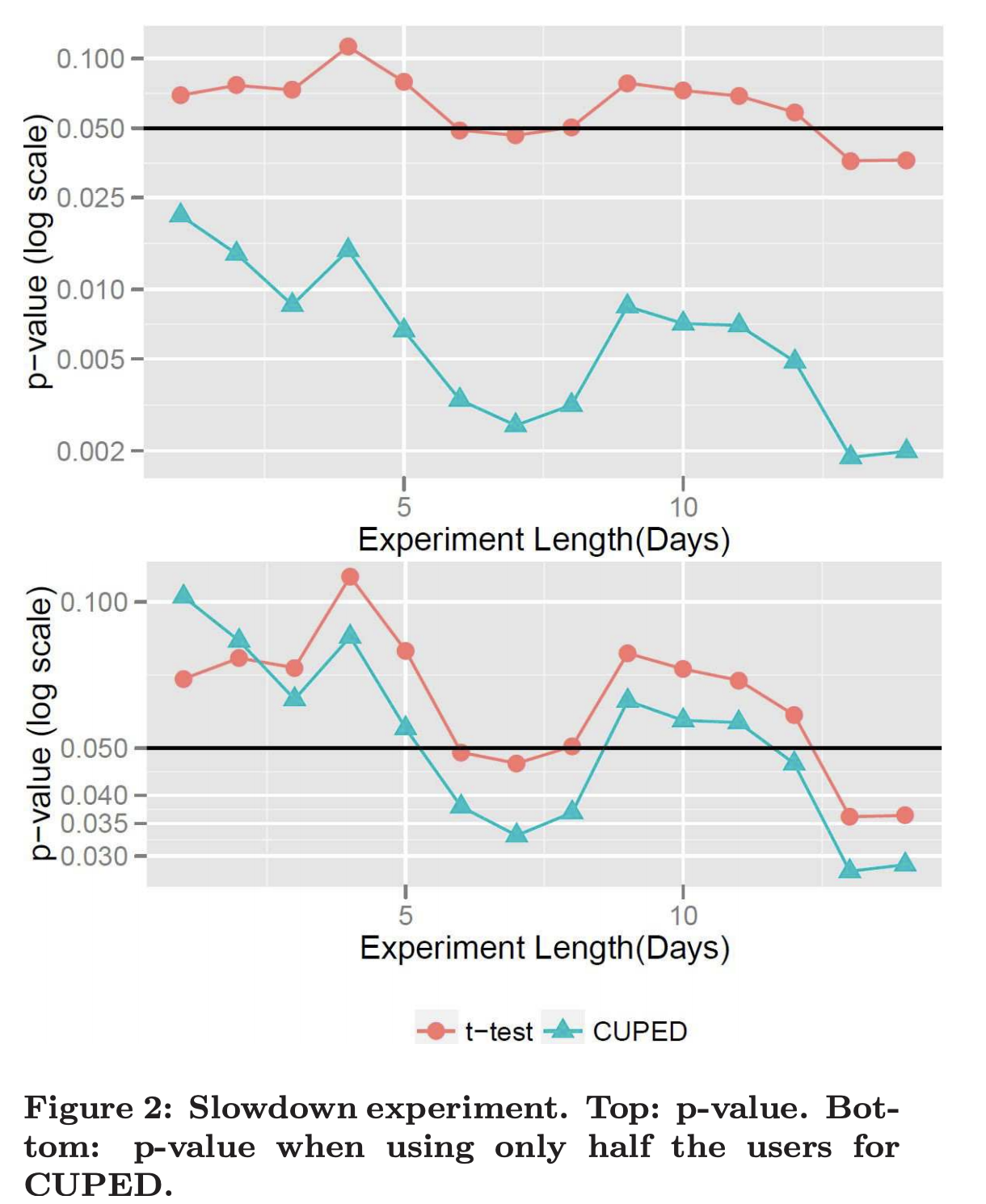
论文中作者在实际AB实验中检验了CUPED的效果。Bing实验检测检测加载时间对用户点击率的影响。 一个原本运行两周只有个别天显著的实验在用CUPED调整后在第一天就显著,当把CUPED估计用的样本减少一半后显著性依旧超过直接使用T-test.
Netflix 多种方法的实际效果对比
Netflix尝试了一种新的stratification, 上述论文中的stratification被称作post-stratification因为它只在估计实验效果时用到分组,这时用pre-experiment估计的分组概率会和随机AB分组得到的实验中的分组概率存在一定差异,所以Netflix尝试在实验前就进行分层分组。通过多个实验结果,Netflix得到以下结论:
- 大样本下,post-strat在实际中更灵活和pre-strat表现相当
- 能否成功找到和实验核心指标相关的covariate是成功的关键
Booking.com 新日历交互对用户影响
How Booking.com increases the power of online experiments with CUPED
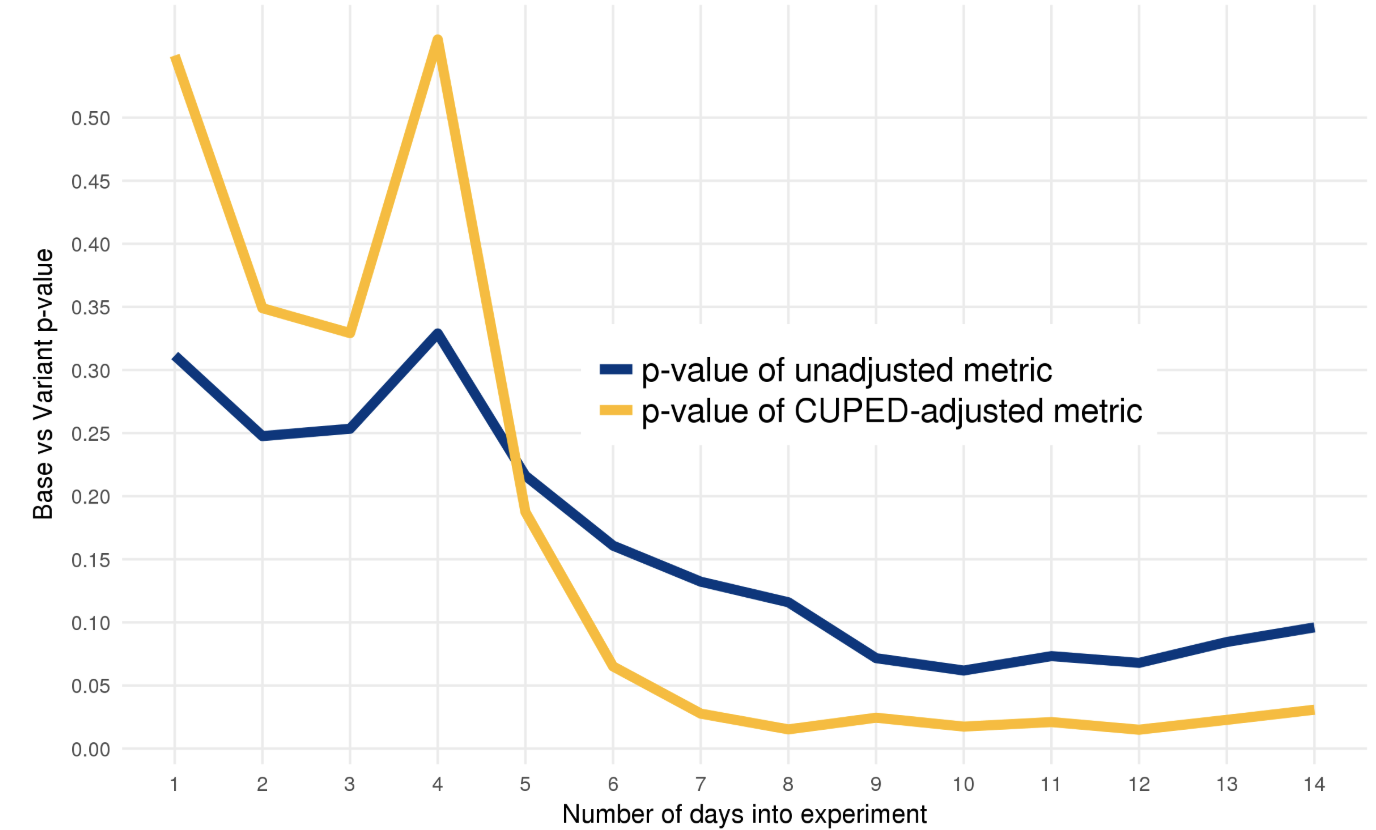
实验效果对比如下,CUPED用更少的样本更短的时间得到了显著的结果。了解细节请戳上面的博客,作者讲的非常通俗易懂。
想更多了解AB实验高端系列的朋友,戳这里呦
AB实验的高端玩法系列2 - 更敏感的AB实验, CUPED!的更多相关文章
- AB实验的高端玩法系列3 - AB组不随机?观测试验?Propensity Score
背景 都说随机是AB实验的核心,为什么随机这么重要呢?有人说因为随机所以AB组整体不存在差异,这样才能准确估计实验效果(ATE) \[ ATE = E(Y_t(1) - Y_c(0)) \] 那究竟随 ...
- AB实验的高端玩法系列4- 实验渗透低?用户未被触达?CACE/LATE
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect.在观测数据中的应用需要和Instrument Variable ...
- 第四模块MySQL50题作业,以及由作业引申出来的一些高端玩法
一.表关系 先参照如下表结构创建7张表格,并创建相关约束 班级表:class 学生表:student cid caption grade_id ...
- Word 查找替换高级玩法系列之 -- 把论文中的缩写词快速变成目录下边的注释表
1. 前言 问题:Word写论文如何把文中的缩写快速转换成注释表? 原来样子: 想要的样子: 2. 步骤 使用查找替换高级用法,替换缩写顺序 选中所有文字 打开查找替换对话框,输入以下表达式: 替换后 ...
- windows下mongodb基础玩法系列二CURD附加一
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- windows下mongodb基础玩法系列二CURD操作(创建、更新、读取和删除)
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- windows下mongodb基础玩法系列一介绍与安装
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
- Word 查找替换高级玩法系列之 -- 段首批量添加字符
打开「查找和替换」输入框,按照下图操作: 更多查找替换高级玩法,参看:Word查找替换高级玩法系列 -- 目录篇 未完 ...... 点击访问原文(进入后根据右侧标签,快速定位到本文)
- Hadoop大数据零基础高端实战培训系列配文本挖掘项目
随机推荐
- 微信小程序全局变量的设置、使用、修改
1. 全局变量的设置 在miniprogram > app.js 文件中设置,globalData对象就是存储全局变量的. App({ globalData: { hasLogin: false ...
- elasticsearch应用于产品列表
package com.linkwee.web.service; import java.util.List; import com.linkwee.api.request.cim.ProductPa ...
- 性能优化:虚拟列表,如何渲染10万条数据的dom,页面同时不卡顿
列表大概有2万条数据,又不让做成分页,如果页面直接渲染2万条数据,在一些低配电脑上可能会照成页面卡死,基于这个需求,我们来手写一个虚拟列表 思路 列表中固定只显示少量的数据,比如60条 在列表滚动的时 ...
- c++中不需要显示指出struct
赫 21:48:16请教个问题赫 21:49:53类声明前对私有继承的结构,的struct定义是什么作用?类声明前对该类私有继承的结构,的struct定义是什么作用?赫 21:51:21stru ...
- Kotlin学习系列(三)
类声明 Kotlin使用class关键字声明类: class Invoice{ } Kotlin类声明基本包括header与body: [<Modifier>] <class> ...
- Flask基础(17)-->防止 CSRF 攻击
CSRF CSRF全拼为Cross Site Request Forgery,译为跨站请求伪造. CSRF指攻击者盗用了你的身份,以你的名义发送恶意请求. 包括:以你名义发送邮件,发消息,盗取你的账号 ...
- pandas.DataFrame的groupby()方法的基本使用
pandas.DataFrame的groupby()方法是一个特别常用和有用的方法.让我们快速掌握groupby()方法的基础使用,从此数据分析又多一法宝. 首先导入package: import p ...
- Disruptor—核心概念及体验
本文基于最新的3.4.2的版本文档进行翻译,翻译自: https://github.com/LMAX-Exchange/disruptor/wiki/Introduction https://gith ...
- pyinstaller 打包exe程序读不到配置文件No such file
挺久没更新博客的,一来之前是觉得才疏学浅,记录下来的太简单没人看.二来时间上不是很充裕(不是借口,有时间打游戏,没时间总结) 偶然有一次发现同事在搜索解决问题的时候正在看我博客的解决思路,很奇妙的感觉 ...
- Vue躬行记(1)——数据绑定
Vue.js的核心是通过基于HTML的模板语法声明式地将数据绑定到DOM结构中,即通过模板将数据显示在页面上,如下所示. <div id="container">{{c ...
背景 都说随机是AB实验的核心,为什么随机这么重要呢?有人说因为随机所以AB组整体不存在差异,这样才能准确估计实验效果(ATE) \[ ATE = E(Y_t(1) - Y_c(0)) \] 那究竟随 ...
CACE全称Compiler Average Casual Effect或者Local Average Treatment Effect.在观测数据中的应用需要和Instrument Variable ...
一.表关系 先参照如下表结构创建7张表格,并创建相关约束 班级表:class 学生表:student cid caption grade_id ...
1. 前言 问题:Word写论文如何把文中的缩写快速转换成注释表? 原来样子: 想要的样子: 2. 步骤 使用查找替换高级用法,替换缩写顺序 选中所有文字 打开查找替换对话框,输入以下表达式: 替换后 ...
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
windows下mongodb基础玩法系列 windows下mongodb基础玩法系列一介绍与安装 windows下mongodb基础玩法系列二CURD操作(创建.更新.读取和删除) windows下 ...
打开「查找和替换」输入框,按照下图操作: 更多查找替换高级玩法,参看:Word查找替换高级玩法系列 -- 目录篇 未完 ...... 点击访问原文(进入后根据右侧标签,快速定位到本文)
1. 全局变量的设置 在miniprogram > app.js 文件中设置,globalData对象就是存储全局变量的. App({ globalData: { hasLogin: false ...
package com.linkwee.web.service; import java.util.List; import com.linkwee.api.request.cim.ProductPa ...
列表大概有2万条数据,又不让做成分页,如果页面直接渲染2万条数据,在一些低配电脑上可能会照成页面卡死,基于这个需求,我们来手写一个虚拟列表 思路 列表中固定只显示少量的数据,比如60条 在列表滚动的时 ...
赫 21:48:16请教个问题赫 21:49:53类声明前对私有继承的结构,的struct定义是什么作用?类声明前对该类私有继承的结构,的struct定义是什么作用?赫 21:51:21stru ...
类声明 Kotlin使用class关键字声明类: class Invoice{ } Kotlin类声明基本包括header与body: [<Modifier>] <class> ...
CSRF CSRF全拼为Cross Site Request Forgery,译为跨站请求伪造. CSRF指攻击者盗用了你的身份,以你的名义发送恶意请求. 包括:以你名义发送邮件,发消息,盗取你的账号 ...
pandas.DataFrame的groupby()方法是一个特别常用和有用的方法.让我们快速掌握groupby()方法的基础使用,从此数据分析又多一法宝. 首先导入package: import p ...
本文基于最新的3.4.2的版本文档进行翻译,翻译自: https://github.com/LMAX-Exchange/disruptor/wiki/Introduction https://gith ...
挺久没更新博客的,一来之前是觉得才疏学浅,记录下来的太简单没人看.二来时间上不是很充裕(不是借口,有时间打游戏,没时间总结) 偶然有一次发现同事在搜索解决问题的时候正在看我博客的解决思路,很奇妙的感觉 ...
Vue.js的核心是通过基于HTML的模板语法声明式地将数据绑定到DOM结构中,即通过模板将数据显示在页面上,如下所示. <div id="container">{{c ...