Scrapy爬虫框架(2)--内置py文件
Scrapy概念图
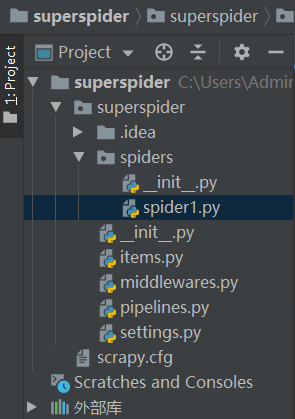
- 这里有很多py文件,分别与Scrapy的各个模块对应
- superspider是一个爬虫项目
- spider1.py则是一个创建好的爬虫文件,爬取资源返回url和数据
- items.py可以在里面预先定义要爬取的字段,并导入到其他模块,在爬虫解析页面时仅能使用已定义的这些字段
- middlewares.py里面可以编写有关爬虫中间件和下载中间件的内容
- pipelines.py则是提取数据的一个部分,编写有关数据处理的代码,接受由spider传过来的数据
- settings.py里面是一些爬虫的设置,也可以导入自己的设置并导入到其他模块
- superspider是一个爬虫项目
大致内容
- spider.py
- items.py
settings内容
原生设置
BOT_NAME = 'superspider'
SPIDER_MODULES = ['superspider.spiders']
NEWSPIDER_MODULE = 'superspider.spiders'
BOT_NAME: 项目名称SPIDER_MODULES:爬虫位置NEWSPIDER_MODULE: 新建爬虫的位置
Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'superspider (+http://www.yourdomain.com)'
- 可在这里设置User-Agent
ROBOTSTXT_OBEY = True
ROBOTSTXT_OBEY:是否遵守robots协议默认为遵守,改 False 可不遵守
Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
CONCURRENT_REQUESTS:Scrapy downloader 并发请求(concurrent requests)的最大值,默认: 16
Configure a delay for requests for the same website (default: 0)
DOWNLOAD_DELAY = 3
The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
DOWNLOAD_DELAY:页面请求延迟时间,默认为0(秒)可缓解对方服务器压力- 下载延迟设置,只能有一个生效
CONCURRENT_REQUESTS_PER_DOMAIN对单个网站并发请求最大值CONCURRENT_REQUESTS_PER_IP对单个IP并发请求最大值- 设置为0则下载延迟生效
Disable cookies (enabled by default)
COOKIES_ENABLED = False Disable Telnet Console (enabled by default)
TELNETCONSOLE_ENABLED = False
- cookies和控制台,默认禁用
COOKIES_ENABLED
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}- 默认的请求头,User-agent和cookies不需要在这里设置
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'superspider.pipelines.SuperspiderPipeline': 300,
#}
- item pipelines的配置
'superspider.pipelines.SuperspiderPipeline' = 300300指的是优先级
额外经常用到的配置
默认: True,是否启用logging。
LOG_ENABLED=True
默认: 'utf-8',logging使用的编码。
LOG_ENCODING='utf-8'
它是利用它的日志信息可以被格式化的字符串。默认值:'%(asctime)s [%(name)s] %(levelname)s: %(message)s'
LOG_FORMAT='%(asctime)s [%(name)s] %(levelname)s: %(message)s'
它是利用它的日期/时间可以格式化字符串。默认值: '%Y-%m-%d %H:%M:%S'
LOG_DATEFORMAT='%Y-%m-%d %H:%M:%S'
日志文件名
LOG_FILE = "dg.log"
LOG_LEVEL = 'WARNING'
- 日志文件级别,默认值:“DEBUG”,log的最低级别。可选的级别有: CRITICAL、 ERROR、WARNING、INFO、DEBUG 。
logging模块的简单使用
- settings中设置LOG_LEVEL = "WARNING"
- settings中设置LOG_FILE = "./a.log"就不会在终端显示日志内容
scrapy shell可以在终端进行调试
Scrapy爬虫框架(2)--内置py文件的更多相关文章
- 第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
随机推荐
- 20175314 《Java程序设计》第十周学习总结
20175314 <Java程序设计>第十周学习总结 教材学习内容总结 进程与线程:一个进程的进行期间可以产生多个线程. Java内置对多线程的支持,计算机只能执行线程中的一个,Java虚 ...
- jQuery数组去重复
例如: var yearArray = new Array("三二一", "三二一", "学历", "学历", &quo ...
- [斯坦福大学2014机器学习教程笔记]第五章-控制语句:for,while,if语句
在本节中,我们将学习如何为Octave程序写控制语句. 首先,我们先学习如何使用for循环.我们将v设为一个10行1列的零向量. 接着,我们写一个for循环,让i等于1到10.写出来就是for i = ...
- FastJson反序列化和构造函数之间的一点小秘密
各位看官大家下午好,FastJson想必大家都很熟悉了,很常见的Json序列化工具.今天在下要和大家分享一波FastJson反序列化和构造函数之间的一点小秘密. 下面先进入大家都深恶痛绝的做题环节.哈 ...
- Centos6升级内核方法
docker需要内核在3.0以上,如果centos6上需要安装docker的话需要先将内核进行升级 工具/原料 Centos6.5_x64 方法/步骤 操作系统为centos6.5,内核为 ...
- 5个最佳WordPress通知栏插件
作者:品博客 链接:https://blog.pingbook.top/328/ 来源:品博客 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. WordPress通知栏可有效地将 ...
- Thinkphp getLastSql函数用法
如何判断一个更新操作是否成功: $Model = D('Blog'); $data['id'] = 10; $data['name'] = 'update name'; $result = $Mode ...
- python的字符串、列表、字典和函数
一.字符串 在python中字符串无需通过像php中的explode或者javascript中的split进行分解即可完成切片,可以直接通过下标获取字符串中的每一个字符,下标从0开始,如果从厚望签署, ...
- 修复Windows10引导,适用gpt+uefi环境
在双硬盘多系统安装时,容易损坏Win10的开机引导文件. 可以尝试用Windows原版安装盘启动,进入命令提示符模式: 首先使用diskpart命令确认需要修复的Windows分区的安装卷X:. 再运 ...
- 29.3 ArrayList、List、LinkedList(链表)优缺点
ArrayList.List特点:查询快.增删慢 链表特点:查询慢,增删快 案例 package day29_collection集合体系; import java.util.ArrayList; i ...