Scrapy学习-(1)
Scrapy框架介绍
Scrapy是一个非常优秀的爬虫框架,基于python。
只需要在cmd运行pip install scrapy就可以自动安装。用scrapy-h检验是否成功安装
Scrapy部署一个简单的爬虫库,是一个爬虫框架。此外和requests库相比,Scrapy库适合大型爬虫,适合网站爬虫。
爬虫框架
爬虫框架是实现爬虫功能的一个软件结构和功能组件的集合,是一个半成品,能够帮助用户实现专业网络爬虫。
Scrapy框架有几个主要的板块,形成“5+2”结构,板块之间的路径关系如下图。
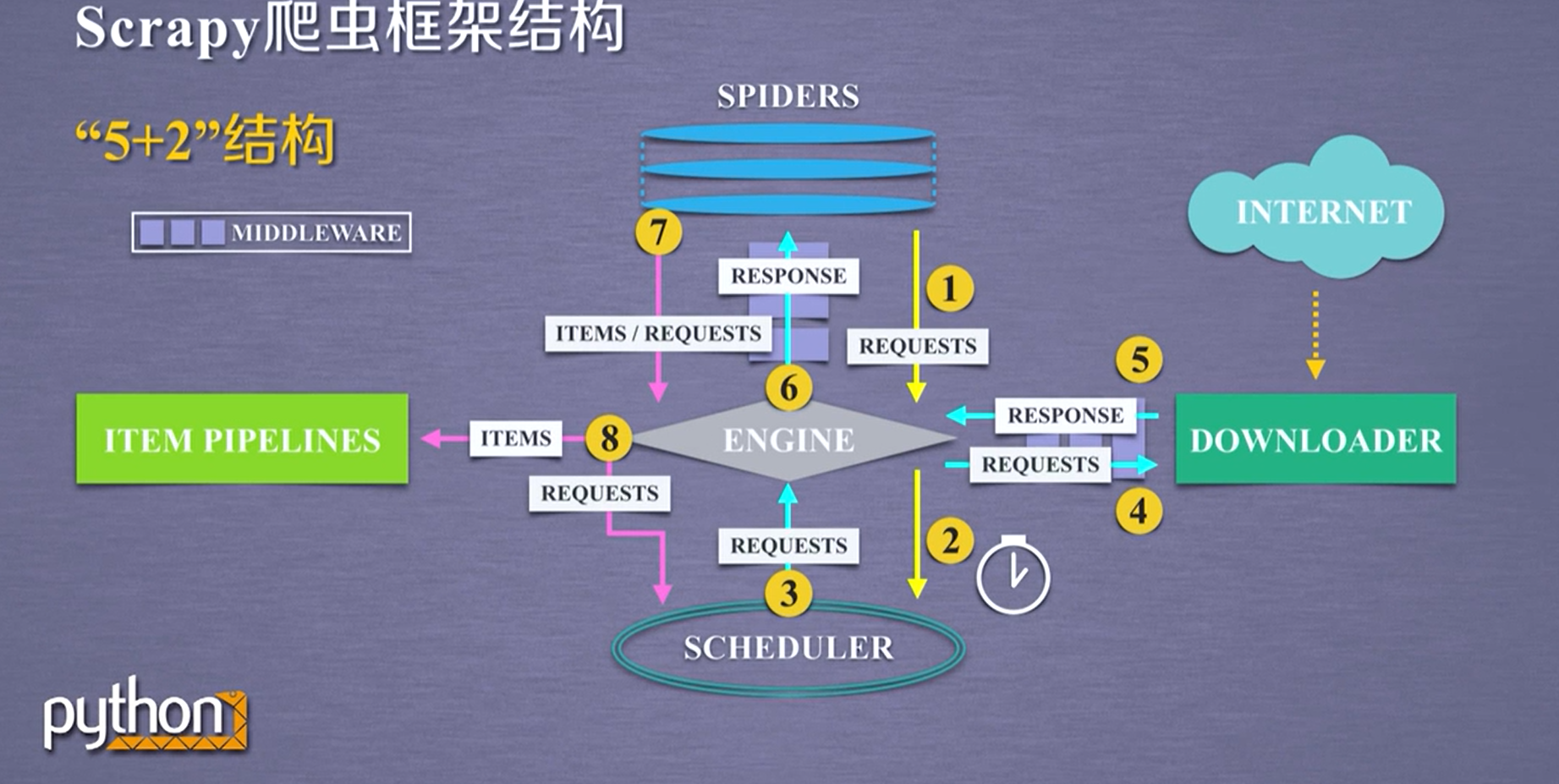
Scrapy框架的入口是SPIDERS,出口是ITEM PIPELINES。只有入口和出口是需要用户编写的。其他都是内部写好的。


Scrapy库的主要命令
用scrapy-h进入命令行
命令行格式 >scrapy[options][args]
| 代码 | 作用 | 格式 |
|---|---|---|
| startproject | 创建一个新的工程 | scrapy startproject [dir] |
| genspider | 创建一个爬虫 | scrapy genspider [options] |
| setting | 获得爬虫的配置信息 | scrapy setting [options] |
| crawl | 运行一个爬虫 | scrapy crawl |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动url调试命令行 | scrapy shell[url] |
我们需要理解工程和爬虫的爬虫的区别。
注意Scrapy爬虫是用命令行爬虫的,最初设计是给程序员使用的,没有图形界面。
Scrapy爬虫的一个实例
建立一个爬虫工程
打开cmd,用cd命令调整到特定的文件夹,建立一个工程。例如:scrapy startproject python123demo
建立好了后,工程会生成一个目录,这个目的就是这个工程。
这个目录包含一个部署爬虫的配置文件scrapy.cfg ,包含一个初始化脚本__init__.py,一个Items代码模板(继承类)item.py
Middlewares模板(继承类)middlewares.py,Piplines代码模板(继承类)pipelines.py,Scrapy爬虫配置文件 settings.py
下面有一个spiders/目录 里面是Spiders代码模板目录(继承类)存放是建立的爬虫
建立一个爬虫
打开命令行输入scrapy genspider demo来建立一个爬虫,生成一个demo.py文件到你的cmd路径。不要忘记修改cmd的路径到spyder下。

配置产生的爬虫
打开demo文件,修改里面的代码。

运行爬虫
打开命令行,输入scrapy crawl demo,执行后会出现一个demo.html文件,这个文件就是网页源码。
下面是demo.py完整代码
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
def start_request(scrapy.Spider):
urls = {'http://python123.io/ws/demo.html'}
for url in urls:
yield scrapy.Request(url=url ,callback=self.parse)
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname , 'wb') as f:
f.write(response.body)
self.log('Saved file %s.' % name)
Scrapy学习-(1)的更多相关文章
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- Scrapy学习篇(七)之Item Pipeline
在之前的Scrapy学习篇(四)之数据的存储的章节中,我们其实已经使用了Item Pipeline,那一章节主要的目的是形成一个笼统的认识,知道scrapy能干些什么,但是,为了形成一个更加全面的体系 ...
- Scrapy:学习笔记(2)——Scrapy项目
Scrapy:学习笔记(2)——Scrapy项目 1.创建项目 创建一个Scrapy项目,并将其命名为“demo” scrapy startproject demo cd demo 稍等片刻后,Scr ...
- Scrapy:学习笔记(1)——XPath
Scrapy:学习笔记(1)——XPath 1.快速开始 XPath是一种可以快速在HTML文档中选择并抽取元素.属性和文本的方法. 在Chrome,打开开发者工具,可以使用$x工具函数来使用XPat ...
- scrapy学习(完全版)
scrapy1.6中文文档 scrapy1.6中文文档 scrapy中文文档 Scrapy框架 下载页面 解析页面 并发 深度 安装 scrapy学习教程 如果安装了anconda,可以在anacon ...
- python爬虫之Scrapy学习
在爬虫的路上,学习scrapy是一个必不可少的环节.也许有好多朋友此时此刻也正在接触并学习scrapy,那么很好,我们一起学习.开始接触scrapy的朋友可能会有些疑惑,毕竟是一个框架,上来不知从何学 ...
- 转载一个不错的Scrapy学习博客笔记
背景: 最近在学习网络爬虫Scrapy,官网是 http://scrapy.org 官方描述:Scrapy is a fast high-level screen scraping and web c ...
- Scrapy学习篇(十一)之设置随机User-Agent
大多数情况下,网站都会根据我们的请求头信息来区分你是不是一个爬虫程序,如果一旦识别出这是一个爬虫程序,很容易就会拒绝我们的请求,因此我们需要给我们的爬虫手动添加请求头信息,来模拟浏览器的行为,但是当我 ...
- Scrapy学习篇(九)之文件与图片下载
Media Pipeline Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines . 这些pipeline有些共同的方 ...
- Scrapy学习笔记(5)-CrawlSpider+sqlalchemy实战
基础知识 class scrapy.spiders.CrawlSpider 这是抓取一般网页最常用的类,除了从Spider继承过来的属性外,其提供了一个新的属性rules,它提供了一种简单的机制,能够 ...
随机推荐
- Hive常用命令及作用
1-创建表 -- 内部表 create table aa(col1 string,col2 int) partitioned by(statdate int) ROW FORMAT DELIMITED ...
- coding++:java-全局异常处理
本次使用工具:SpringBoot <version>1.5.19.RELEASE</version> Code: AbstractException: package m ...
- 事务框架之声明事务(自动开启,自动提交,自动回滚)Spring AOP 封装
利用Spring AOP 封装事务类,自己的在方法前begin 事务,完成后提交事务,有异常回滚事务 比起之前的编程式事务,AOP将事务的开启与提交写在了环绕通知里面,回滚写在异常通知里面,找到指定的 ...
- Ubuntu虚拟机查看文件,目录颜色详解
查看文件 查看Home(不是home)目录下文件: [duanyongchun@localhost ~]$ ls 查看根目录下文件: [duanyongchun@localhost ~]$ cd / ...
- 三、【Docker笔记】Docker镜像
镜像是Docker的三大核心概念之一.Docker在运行容器之前,本地需要存有镜像,若不存在则Docker会首先尝试从默认的镜像仓库中去下载,当然我们也可以去配置自己的仓库,如此就会从我们配置的仓库中 ...
- JS烟花案例
html代码部分 <!DOCTYPE html> <!-- * @Descripttion: * @version: * @Author: 小小荧 * @Date: 2020-03- ...
- 为什么我建议每个开发人员都需要学Python?
转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 原文出处:https://dzone.com/articles/10-reasons-why-every-d ...
- 安装部署Tomcat服务器
安装部署Tomcat服务器 案例1:安装部署Tomcat服务器 案例2:使用Tomcat部署虚拟主机 案例3:使用Varnish加速Web 1案例1:安装部署Tom ...
- app测试的一些较为重要的测试点
安装测试 从不同的手机所自带的不同的版本的软件商城里面下载抖音并安装查看是否成功 安装后是否能正常运行安装后的文件和文件夹是否写到了指定的目录里 安装过程中取消安装,安装的文件是否在指定的目录里 安装 ...
- 基于 Spring Cloud 的微服务架构实践指南(下)
show me the code and talk to me,做的出来更要说的明白 本文源码,请点击learnSpringCloud 我是布尔bl,你的支持是我分享的动力! 一.引入 上回 基于 S ...